Esta página muestra como se pueden emplear las funciones de regresión de R base , como glm() y el paquete gtsummary para observar las asociaciones entre variables (por ejemplo, odds ratios, risk ratios y hazard ratios). También utiliza funciones como tidy() del paquete broom para limpiar los resultados de la regresión.
Univariante: tablas de dos por dos
Estratificado: estimaciones mantel-haenszel
Multivariable: selección de variables, selección de modelos, tabla final
NOTA: Utilizamos el término multivariable para referirnos a una regresión con múltiples variables explicativas. En este sentido, un modelo multivariante sería una regresión con varios resultados - véase este editorial para más detalles.
19.1 Preparación
Cargar paquetes
Este trozo de código muestra la carga de los paquetes necesarios para realizar los análisis. En este manual se hace énfasis en en el empleo de p_load() de pacman, que instala el paquete si es necesario y lo carga para tu uso. Los paquetes ya instalados también pueden cargarse empleando library() de R base. Consulta la página sobre fundamentos de R para obtener más información sobre los paquetes de R.
pacman::p_load( rio, # Importación de ficheros here, # Localizador de ficheros tidyverse, # gestión de datos + gráficos ggplot2, stringr, # manipular cadenas de texto purrr, # bucle sobre objetos de forma ordenada gtsummary, # resumen estadístico y tests broom, # ordenar resultados de regresiones lmtest, # pruebas de razón de verosimilitud parameters, # alternativa para ordenar los resultados de las regresiones ver # alternativa para visualizar gráficos de bosque )
Installing package into 'C:/Users/ngulu864/AppData/Local/R/win-library/4.3'
(as 'lib' is unspecified)
Warning: package 'ver' is not available for this version of R
A version of this package for your version of R might be available elsewhere,
see the ideas at
https://cran.r-project.org/doc/manuals/r-patched/R-admin.html#Installing-packages
Warning: unable to access index for repository http://www.stats.ox.ac.uk/pub/RWin/bin/windows/contrib/4.3:
cannot open URL 'http://www.stats.ox.ac.uk/pub/RWin/bin/windows/contrib/4.3/PACKAGES'
Warning in p_install(package, character.only = TRUE, ...):
Warning in library(package, lib.loc = lib.loc, character.only = TRUE,
logical.return = TRUE, : there is no package called 'ver'
Warning in pacman::p_load(rio, here, tidyverse, stringr, purrr, gtsummary, : Failed to install/load:
ver
Importar datos
Importaremos los datos de casos de una epidemia de ébola simulada. Para seguir el proceso, clica aquí para descargar la base de datos linelist “limpia” (como archivo .rds). Importa tus datos con la función import() del paquete rio (la cual acepta múltiples tipos de archivos como .xlsx, .rds, .csv - Checa la página de importación y exportación para más detalles).
A continuación se muestran las primeras 50 filas de la base de datos linelist.
Datos limpios
Almacenar las variables explicativas
Almacenamos en un vector de caracteres los nombres de las columnas explicativas. Esto se explicará más adelante.
## definir las variables de interésexplanatory_vars <-c("gender", "fever", "chills", "cough", "aches", "vomit")
Convertir a 1’s y 0’s
A continuación convertimos las columnas explicativas de “sí”/“no”, “m”/“f”, y “muerto”/“vivo” a 1 / 0, para cumplir con las expectativas de los modelos de regresión logística. Para hacer esto de manera eficiente, utilizaremos across() de dplyr para transformar varias columnas a la vez. La función que aplicamos a cada columna es case_when() (también de dplyr) que aplica la lógica para convertir los valores especificados en 1’s y 0’s. Mira las secciones sobre across() y case_when() en la página de Limpieza de datos y funciones básicas).
Nota: el “.” que aparece a continuación representa la columna que está siendo procesada por across() en ese momento.
## convertir variables dicotómicas a 0/1linelist <- linelist %>%mutate(across( .cols =all_of(c(explanatory_vars, "outcome")), ## para cada columna listada y "outcome".fns =~case_when( . %in%c("m", "yes", "Death") ~1, ## recodifica hombre, yes y defunción a 1 . %in%c("f", "no", "Recover") ~0, ## mujer, no y recuperado a 0TRUE~NA_real_) ## de lo contrario, lo establece como faltante ) )
Eliminar las filas con valores perdidos
Para eliminar las filas con valores perdidos, se puede utilizar la función drop_na() de tidyr. Sin embargo, sólo queremos hacer esto para las filas a las que les faltan valores en las columnas de interés.
Lo primero que debemos hacer es asegurarnos de que nuestro vector explanatory_vars incluye la columna age (age habría producido un error en la operación anterior case_when(), que sólo era para variables dicotómicas). A continuación, escribimos un pipe uniendo linelist con drop_na() para eliminar cualquier fila con valores perdidos en la columna outcome o en cualquiera de las columnas explanatory_vars.
Antes de ejecutar el código, podemos comprobar el número de filas inicial de linelist empleando nrow(linelist).
## añadir age_category a las variables explicativas explanatory_vars <-c(explanatory_vars, "age_cat")## eliminar las filas con información no disponible para las variables de interés linelist <- linelist %>%drop_na(any_of(c("outcome", explanatory_vars)))
Podremos checar el número de filas que quedan en linelist tras la operación empleando nrow(linelist).
19.2 Univariante
Al igual que en la página sobre Tablas descriptivas, en función de la tarea que vayas a realizar, podremos elegir que función emplear. A continuación presentamos dos opciones para realizar análisis univariantes:
Puedes utilizar las funciones disponibles en R base para imprimir rápidamente los resultados en la consola. Después, puedes utilizar el paquete broom para convertir esos outputs a formato tidy.
Puedes utilizar el paquete gtsummary para modelar y obtener resultados en tablas listas para su publicación.
R base
Regresión lineal
La función lm() de R base realiza una regresión lineal, evaluando la relación entre la respuesta numérica y las variables explicativas que se supone tienen una relación lineal.
Para ello, proporciona la ecuación como una fórmula, con los nombres de las columnas de respuesta y explicativa separados por una tilde ~. Además, especifica la base de datos a data =. Finalmente, define los resultados del modelo como un objeto R, para poder utilizarlos más tarde.
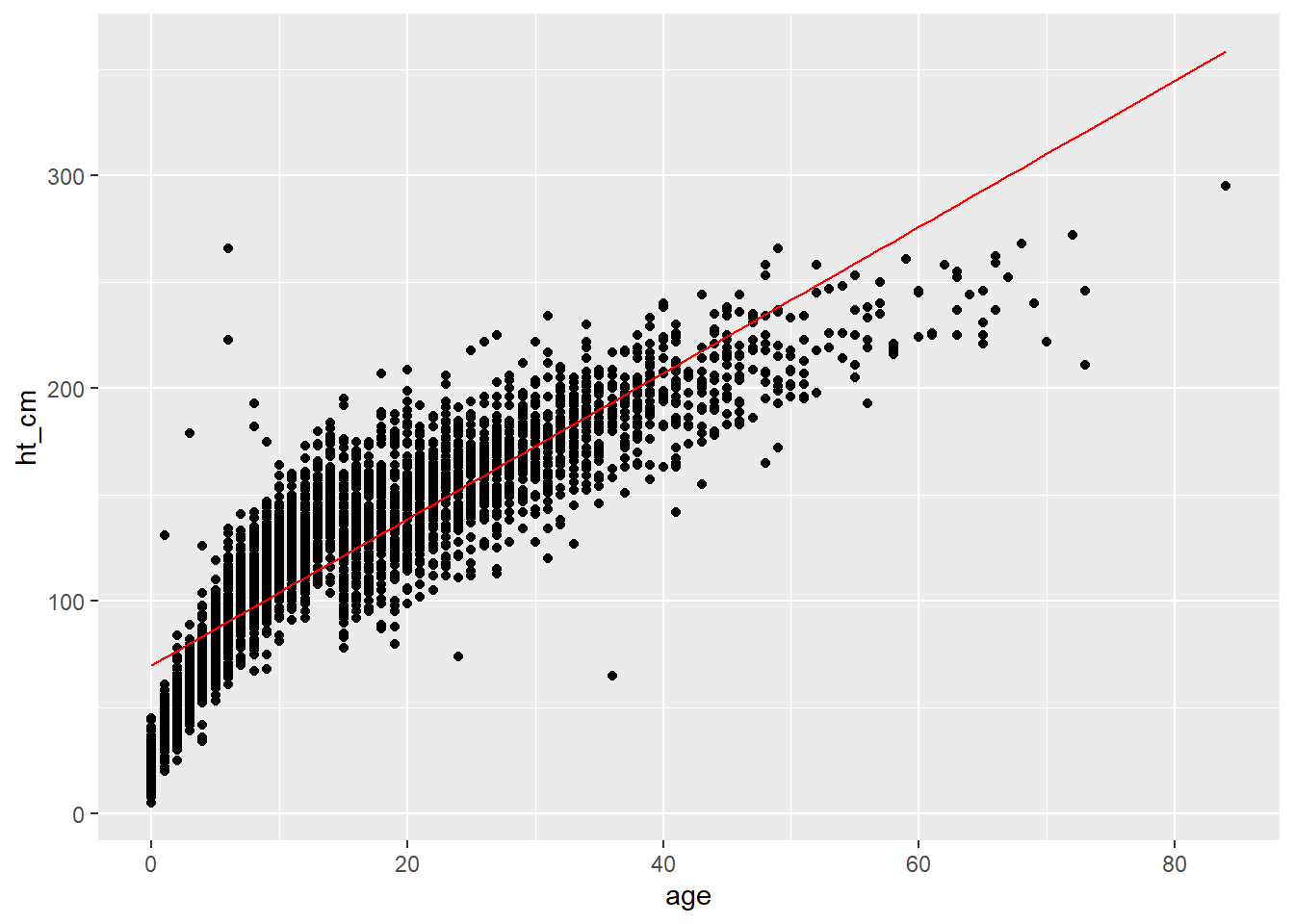
lm_results <-lm(ht_cm ~ age, data = linelist)
A continuación, puedes ejecutar summary() en los resultados del modelo para ver los coeficientes (estimaciones), el valor P, los residuos y otras medidas.
summary(lm_results)
Call:
lm(formula = ht_cm ~ age, data = linelist)
Residuals:
Min 1Q Median 3Q Max
-128.579 -15.854 1.177 15.887 175.483
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 69.9051 0.5979 116.9 <2e-16 ***
age 3.4354 0.0293 117.2 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 23.75 on 4165 degrees of freedom
Multiple R-squared: 0.7675, Adjusted R-squared: 0.7674
F-statistic: 1.375e+04 on 1 and 4165 DF, p-value: < 2.2e-16
También se puede utilizar la función tidy() del paquete broom para obtener los resultados en una tabla. Lo que nos dicen los resultados es que por cada año de aumento de la edad la altura aumenta 3,5 cm y esto es estadísticamente significativo.
tidy(lm_results)
# A tibble: 2 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 69.9 0.598 117. 0
2 age 3.44 0.0293 117. 0
También podemos utilizar esta regresión para añadirla a un ggplot, para hacer esto, primero juntamos los puntos de los datos observados y la línea ajustada en un dataframe utilizando la función augment() de broom.
## extraer los puntos de regresión y los datos observados en un conjunto de datospoints <-augment(lm_results)## representar los datos utilizando la edad como eje-x ggplot(points, aes(x = age)) +## añadir puntos para la alturageom_point(aes(y = ht_cm)) +## añadir la recta de regresión geom_line(aes(y = .fitted), colour ="red")
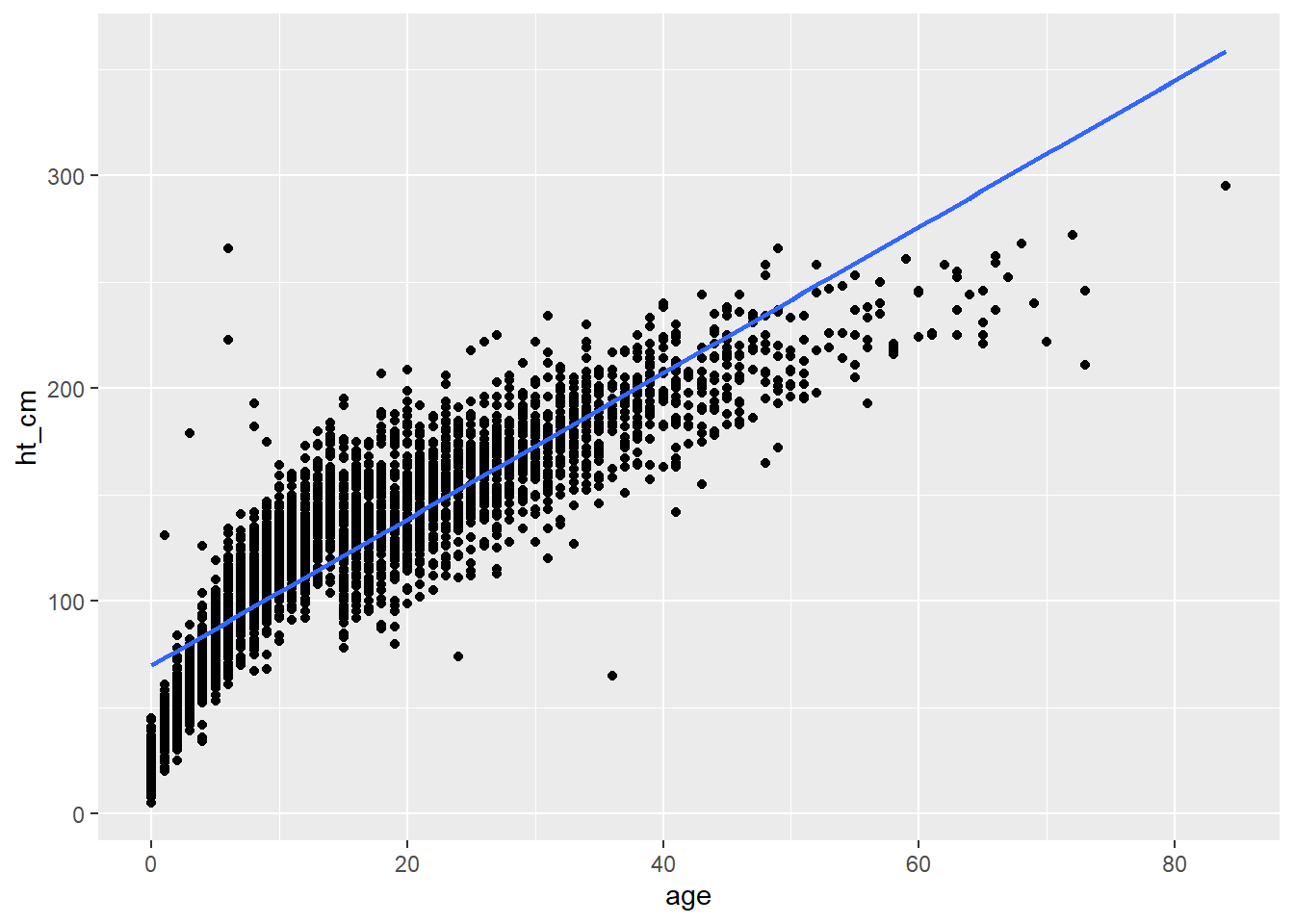
También es posible añadir una recta de regresión lineal en ggplot utilizando la función geom_smooth().
## añade tus datos a un gráfico ggplot(linelist, aes(x = age, y = ht_cm)) +## mostrar puntosgeom_point() +## añadir una regresión lineal geom_smooth(method ="lm", se =FALSE)
`geom_smooth()` using formula = 'y ~ x'
Consulta la sección de recursos al final de este capítulo para consultar tutoriales más detallados.
Regresión logística
La función glm() del paquete stats (parte de R base) se utiliza para ajustar los modelos lineales generalizados (GLM).
glm() puede utilizarse para la regresión logística univariante y multivariable (por ejemplo, para obtener Odds Ratios). Aquí están las partes principales:
# argumentos para glm()glm(formula, family, data, weights, subset, ...)
formula = El modelo se proporciona a glm() como una ecuación, con el resultado a la izquierda y las variables explicativas a la derecha de una tilde ~.
family = Determina el tipo de modelo a ejecutar. Para la regresión logística, utiliza family = "binomial", para poisson utiliza family = "poisson". Otros ejemplos se encuentran en la tabla siguiente.
data = Especifica tu base de datos.
Si es necesario, también puede especificar la función de enlace mediante la sintaxis family = familytype(link = "linkfunction")). Puedes leer más en la documentación sobre otras familias y argumentos opcionales como weights = y subset = (?glm).
Familia
Función de enlace por defecto
"binomial"
(link = "logit")
"gaussian"
(link = "identity")
"Gamma"
(link = "inverse")
"inverse.gaussian"
(link = "1/mu^2")
"poisson"
(link = "log")
"quasi"
(link = "identity", variance = "constant")
"quasibinomial"
(link = "logit")
"quasipoisson"
(link = "log")
Cuando se ejecuta glm() lo más habitual es guardar los resultados como un objeto R. A continuación, se pueden mostrar los resultados en la consola utilizando summary() como se muestra a continuación, o realizar otras operaciones con los resultados (por ejemplo, exponenciar).
Si necesitas ejecutar una regresión binomial negativa, puede utilizar el paquete MASS; el cual contiene la función glm.nb() que utiliza la misma sintaxis que glm().
En este ejemplo estamos evaluando la asociación entre diferentes categorías de edad y el resultado de muerte (codificado como 1 en la sección anterior “Preparación”). A continuación se muestra un modelo univariante de outcome por age_cat. Guardamos la salida del modelo como model y luego la imprimimos con summary() en la consola. Observa que las estimaciones proporcionadas son las probabilidades logarítmicas (log odds) y que el nivel de referencia es el primer nivel del factor age_cat (“0-4”).
model <-glm(outcome ~ age_cat, family ="binomial", data = linelist)summary(model)
Call:
glm(formula = outcome ~ age_cat, family = "binomial", data = linelist)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 0.233738 0.072805 3.210 0.00133 **
age_cat5-9 -0.062898 0.101733 -0.618 0.53640
age_cat10-14 0.138204 0.107186 1.289 0.19726
age_cat15-19 -0.005565 0.113343 -0.049 0.96084
age_cat20-29 0.027511 0.102133 0.269 0.78765
age_cat30-49 0.063764 0.113771 0.560 0.57517
age_cat50-69 -0.387889 0.259240 -1.496 0.13459
age_cat70+ -0.639203 0.915770 -0.698 0.48518
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 5712.4 on 4166 degrees of freedom
Residual deviance: 5705.1 on 4159 degrees of freedom
AIC: 5721.1
Number of Fisher Scoring iterations: 4
Para modificar el nivel de referencia de una variable determinada, asegúrate de que la columna es del tipo Factor y mueve el nivel deseado a la primera posición con fct_relevel() (véase la página sobre Factores). Por ejemplo, a continuación tomamos la columna age_cat y establecemos “20-29” como línea de base antes de conectar mediante pipes el dataframe modificado con glm().
linelist %>%mutate(age_cat =fct_relevel(age_cat, "20-29", after =0)) %>%glm(formula = outcome ~ age_cat, family ="binomial") %>%summary()
Call:
glm(formula = outcome ~ age_cat, family = "binomial", data = .)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 0.26125 0.07163 3.647 0.000265 ***
age_cat0-4 -0.02751 0.10213 -0.269 0.787652
age_cat5-9 -0.09041 0.10090 -0.896 0.370220
age_cat10-14 0.11069 0.10639 1.040 0.298133
age_cat15-19 -0.03308 0.11259 -0.294 0.768934
age_cat30-49 0.03625 0.11302 0.321 0.748390
age_cat50-69 -0.41540 0.25891 -1.604 0.108625
age_cat70+ -0.66671 0.91568 -0.728 0.466546
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 5712.4 on 4166 degrees of freedom
Residual deviance: 5705.1 on 4159 degrees of freedom
AIC: 5721.1
Number of Fisher Scoring iterations: 4
Imprimir resultados
En la mayoría de los casos, para su empleo posterior, es necesario hacer modificaciones a los resultados obtenidos anteriormente. La función tidy() del paquete broom es útil de cara a hacer más presentables los resultados de nuestros modelos.
Aquí demostramos cómo combinar los resultados del modelo con una tabla de recuento.
Obtén las estimaciones de log odds ratio exponenciadas y los intervalos de confianza pasando el modelo a tidy() y estableciendo exponentiate = TRUE y conf.int = TRUE.
model <-glm(outcome ~ age_cat, family ="binomial", data = linelist) %>%tidy(exponentiate =TRUE, conf.int =TRUE) %>%# exponenciar y producir ICsmutate(across(where(is.numeric), round, digits =2)) # redondear todas las columnas numéricas
Warning: There was 1 warning in `mutate()`.
ℹ In argument: `across(where(is.numeric), round, digits = 2)`.
Caused by warning:
! The `...` argument of `across()` is deprecated as of dplyr 1.1.0.
Supply arguments directly to `.fns` through an anonymous function instead.
# Previously
across(a:b, mean, na.rm = TRUE)
# Now
across(a:b, \(x) mean(x, na.rm = TRUE))
A continuación, se muestra el objeto tibble model resultante:
Combina estos resultados del modelo con una tabla de recuentos. A continuación, creamos la tabla cruzada de recuentos con la función tabyl() de janitor, como se explica en la página de tablas descriptivas.
Este es el aspecto de este dataframe counts_table:
Ahora podemos unir counts_table y los resultados del model horizontalmente con bind_cols() (dplyr). Recuerda que con bind_cols() las filas de los dos dataframes deben estar perfectamente alineadas. En este código, como estamos enlazando mediante pipes, utilizamos . para representar el objeto counts_table mientras lo enlazamos con el modelo. Para terminar el proceso, utilizamos select() para elegir las columnas deseadas y determinar su orden, y finalmente aplicamos la función round() de R base en todas las columnas numéricas para especificar 2 decimales.
combined <- counts_table %>%# comienza con la tabla de recuentosbind_cols(., model) %>%# combina con los resultados de la regresión select(term, 2:3, estimate, # selecciona y reordena las columnas conf.low, conf.high, p.value) %>%mutate(across(where(is.numeric), round, digits =2)) ## redondea a 2 decimales
Este es el aspecto del dataframe combinado, impreso de forma agradable como una imagen con una función de flextable. En Tablas para presentación se explica cómo personalizar dichas tablas con flextable, o bien puede utilizar otros paquetes como knitr o GT.
combined <- combined %>% flextable::qflextable()
Loops con múltiples modelos univariantes
A continuación presentamos un método que utiliza glm() y tidy(). Para un enfoque más sencillo, véase la sección sobre gtsummary.
Para ejecutar los modelos en varias variables de exposición para producir odds ratios univariantes (es decir, sin controlar entre sí), se puede utilizar el enfoque siguiente. Utiliza str_c() de stringr para crear fórmulas univariantes (véase Caracteres y cadenas), ejecuta la regresión glm() en cada fórmula, pasa cada resultado de glm() a tidy() y finalmente junta todos los resultados de los modelos resultantes con bind_rows() de tidyr. Este enfoque utiliza map() del paquete purrr para iterar - véase la página sobre Iteración, bucles y listas para más información sobre esta herramienta.
Crea un vector de nombres de columnas de las variables explicativas. Ya lo tenemos como explanatory_vars de la sección de preparación de esta página.
Utiliza str_c() para crear múltiples fórmulas de cadena, con el resultado a la izquierda, y un nombre de columna de explanatory_vars a la derecha. El punto . sustituye al nombre de la columna en explanatory_vars.
Pasa estas fórmulas de cadena a map() y establece ~glm() como la función a aplicar a cada entrada. Dentro de glm(), establece la fórmula de regresión como as.formula(.x), donde .x se sustituirá por la fórmula de cadena definida en el paso anterior. map() realizará un bucle sobre cada una de las fórmulas de cadena, ejecutando regresiones para cada una.
Los resultados de este primer map() se pasan a un segundo comando map(), que aplica tidy() a los resultados de la regresión.
Por último, la salida de la segunda función map() (una lista de dataframes ordenados) se condensa con bind_rows(), dando lugar a un dataframe con todos los resultados univariantes.
models <- explanatory_vars %>%# comienza con las variables de interésstr_c("outcome ~ ", .) %>%# combina cada variable en una fórmula ("resultado ~ variable de interés")# iterar a través de cada fórmula univariantemap( .f =~glm( # pasa las fórmulas una a una a glm()formula =as.formula(.x), # dentro de glm(), la fórmula de cadena es .xfamily ="binomial", # especifica el tipo de glm (logístico)data = linelist)) %>%# conjunto de datos# ordenar cada uno de los resultados de regresión glm anterioresmap(.f =~tidy( .x, exponentiate =TRUE, # exponenciación conf.int =TRUE)) %>%# devuelve los intervalos de confianza# colapsar la lista de resultados de regresión en un marco de datosbind_rows() %>%# redondear todas las columnas numéricasmutate(across(where(is.numeric), round, digits =2))
Esta vez, el objeto final models es más largo porque ahora representa los resultados combinados de varias regresiones univariantes. Clica para ver todas las filas de model.
Como antes, podemos crear una tabla de recuentos a partir de linelist para cada variable explicativa, vincularla a models y hacer una bonita tabla. Comenzamos con las variables, e iteramos a través de ellas con map(). Iteramos a través de una función definida por el usuario que implica la creación de una tabla de recuentos con funciones dplyr. Luego se combinan los resultados y se vinculan con los resultados del modelo models.
## para cada variable explicativauniv_tab_base <- explanatory_vars %>%map(.f =~{linelist %>%## comienza con linelistgroup_by(outcome) %>%## agrupa los datos por resultadocount(.data[[.x]]) %>%## produce recuentos para la variable de interéspivot_wider( ## extiende a formato ancho (como en tabulación cruzada)names_from = outcome,values_from = n) %>%drop_na(.data[[.x]]) %>%## elimina las filas que faltanrename("variable"= .x) %>%## cambia la columna de la variable de interés a "variable"mutate(variable =as.character(variable))} ## convierte a carácter, de lo contrario las variables no dicotómicas (categóricas) aparecen como factor y no se pueden combinar ) %>%## colapsar la lista de resultados de conteo en un dataframebind_rows() %>%## combinar con los resultados de la regresión bind_cols(., models) %>%## conservar sólo las columnas de interés select(term, 2:3, estimate, conf.low, conf.high, p.value) %>%## redondear decimalesmutate(across(where(is.numeric), round, digits =2))
A continuación se muestra el aspecto del dataframe. Consulta la página sobre Tablas para presentación para obtener ideas sobre cómo convertir esta tabla en una bonita tabla HTML (por ejemplo, con flextable).
Paquete gtsummary
A continuación presentamos el uso de tbl_uvregression() del paquete gtsummary. Al igual que en la página sobre Tablas descriptivas, las funciones de gtsummary hacen un buen trabajo a la hora de realizar estadísticas y producir outputs con aspecto profesional. Esta función produce una tabla de resultados de regresión univariante.
Seleccionamos sólo las columnas necesarias de linelist (variables explicativas y la variable de resultado) y las introducimos en tbl_uvregression(). Vamos a ejecutar una regresión univariante en cada una de las columnas que definimos como explanatory_vars en la sección de preparación de datos (sexo, fiebre, escalofríos, tos, dolores, vómitos y age_cat).
Dentro de la propia función, proporcionamos el method = como glm (sin comillas), la columna de resultado y = (outcome), especificamos a method.args = que queremos ejecutar la regresión logística a través de family = binomial, y le decimos que exponencie los resultados.
La salida es HTML y contiene el recuento de cada variable.
univ_tab <- linelist %>% dplyr::select(explanatory_vars, outcome) %>%## selecciona las variables de interéstbl_uvregression( ## produce una tabla univariantemethod = glm, ## define la regresión que se desea ejecutar (modelo lineal generalizado)y = outcome, ## define la variable de resultadomethod.args =list(family = binomial), ## define el tipo de glm que se quiere ejecutar (logístico)exponentiate =TRUE## exponencia para producir odds ratios (en lugar de log odds) )## ver la tabla de resultados univariantesuniv_tab
Characteristic
N
OR
1
95% CI
1
p-value
gender
4,167
1.00
0.88, 1.13
>0.9
fever
4,167
1.00
0.85, 1.17
>0.9
chills
4,167
1.03
0.89, 1.21
0.7
cough
4,167
1.15
0.97, 1.37
0.11
aches
4,167
0.93
0.76, 1.14
0.5
vomit
4,167
1.09
0.96, 1.23
0.2
age_cat
4,167
0-4
—
—
5-9
0.94
0.77, 1.15
0.5
10-14
1.15
0.93, 1.42
0.2
15-19
0.99
0.80, 1.24
>0.9
20-29
1.03
0.84, 1.26
0.8
30-49
1.07
0.85, 1.33
0.6
50-69
0.68
0.41, 1.13
0.13
70+
0.53
0.07, 3.20
0.5
1
OR = Odds Ratio, CI = Confidence Interval
Hay muchas modificaciones que se pueden hacer al output de esta tabla, como ajustar las etiquetas de texto, poner en negrita las filas por tu valor p, etc. Puedes consultar tutoriales aquí y en internet.
19.3 Estratificado
Actualmente, el análisis estratificado para gtsummary se está desarrollando. Esta página se actualizará a su debido tiempo.
19.4 Multivariable
Para el análisis multivariable, volvemos a presentar dos enfoques:
glm() y tidy()
Paquete gtsummary
El flujo de trabajo es similar para cada uno de ellos, siendo diferente el último paso al elaborar una tabla final.
Realizar análisis multivariable
Aquí utilizamos glm() pero en este caso, añadiremos más variables al lado derecho de la ecuación, separadas por símbolos de suma (+).
Para ejecutar el modelo con todas nuestras variables explicativas ejecutaríamos:
Call:
glm(formula = outcome ~ gender + fever + chills + cough + aches +
vomit + age_cat, family = "binomial", data = linelist)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 0.069054 0.131726 0.524 0.600
gender 0.002448 0.065133 0.038 0.970
fever 0.004309 0.080522 0.054 0.957
chills 0.034112 0.078924 0.432 0.666
cough 0.138584 0.089909 1.541 0.123
aches -0.070705 0.104078 -0.679 0.497
vomit 0.086098 0.062618 1.375 0.169
age_cat5-9 -0.063562 0.101851 -0.624 0.533
age_cat10-14 0.136372 0.107275 1.271 0.204
age_cat15-19 -0.011074 0.113640 -0.097 0.922
age_cat20-29 0.026552 0.102780 0.258 0.796
age_cat30-49 0.059569 0.116402 0.512 0.609
age_cat50-69 -0.388964 0.262384 -1.482 0.138
age_cat70+ -0.647443 0.917375 -0.706 0.480
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 5712.4 on 4166 degrees of freedom
Residual deviance: 5700.2 on 4153 degrees of freedom
AIC: 5728.2
Number of Fisher Scoring iterations: 4
Si quieres incluir dos variables y una interacción entre ellas puede separarlas con un asterisco * en lugar de un +. Si sólo especifica la interacción, sepáralas con dos puntos :. Por ejemplo:
glm(outcome ~ gender + age_cat * fever, family ="binomial", data = linelist)
Opcionalmente, puedes utilizar este código para aprovechar el vector predefinido de nombres de columnas y volver a crear el comando anterior utilizando str_c(). Esto puede ser útil si los nombres de sus variables explicativas cambian, o si no quieres escribirlas todos de nuevo.
## ejecutar una regresión con todas las variables de interés mv_reg <- explanatory_vars %>%## comienza con el vector de nombres de columnas explicativasstr_c(collapse ="+") %>%## combina todos los nombres de las variables de interés separados por un másstr_c("outcome ~ ", .) %>%## combina los nombres de las variables de interés con el resultado en forma de fórmulaglm(family ="binomial", ## define el tipo de glm como logístico,data = linelist) ## se establece el conjunto de datos
Construir el modelo
Puedes construir tu modelo paso a paso, guardando varios modelos que incluyan determinadas variables explicativas. Puedes comparar estos modelos con pruebas de razón de verosimilitud utilizando lrtest() del paquete lmtest, como se indica a continuación:
NOTA: El uso de anova(model1, model2, test = "Chisq") de R base produce los mismos resultados
model1 <-glm(outcome ~ age_cat, family ="binomial", data = linelist)model2 <-glm(outcome ~ age_cat + gender, family ="binomial", data = linelist)lmtest::lrtest(model1, model2)
Likelihood ratio test
Model 1: outcome ~ age_cat
Model 2: outcome ~ age_cat + gender
#Df LogLik Df Chisq Pr(>Chisq)
1 8 -2852.6
2 9 -2852.6 1 2e-04 0.9883
Otra opción es tomar el objeto que contiene el modelo y aplicar la función step() del paquete stats. Especifica qué dirección de selección de variables deseas utilizar al construir el modelo.
## escoger un modelo usando selección hacia adelante basada en AIC## también se puede hacer "hacia atrás" o "ambos" ajustando la direcciónfinal_mv_reg <- mv_reg %>%step(direction ="forward", trace =FALSE)
Para mayor claridad, también puedes desactivar la notación científica en tu sesión de R.
options(scipen=999)
Como se describe en la sección sobre el análisis univariante, pasamos la salida del modelo a tidy() para exponenciar las probabilidades logarítmicas y los IC. Finalmente, redondeamos todas las columnas numéricas a dos decimales. Haz scroll para ver el resultado.
mv_tab_base <- final_mv_reg %>% broom::tidy(exponentiate =TRUE, conf.int =TRUE) %>%## get a tidy dataframe of estimates mutate(across(where(is.numeric), round, digits =2)) ## redonda
Este es el aspecto del dataframe resultante:
Combinar regresiones univariantes y multivariables
Combinar con gtsummary
El paquete gtsummary proporciona la función tbl_regression(), que toma los resultados de una regresión (glm() en este caso) y produce una bonita tabla resumen.
## mostrar la tabla de resultados de la regresión final mv_tab <-tbl_regression(final_mv_reg, exponentiate =TRUE)
Veamos la tabla:
mv_tab
Characteristic
OR
1
95% CI
1
p-value
gender
1.00
0.88, 1.14
>0.9
fever
1.00
0.86, 1.18
>0.9
chills
1.03
0.89, 1.21
0.7
cough
1.15
0.96, 1.37
0.12
aches
0.93
0.76, 1.14
0.5
vomit
1.09
0.96, 1.23
0.2
age_cat
0-4
—
—
5-9
0.94
0.77, 1.15
0.5
10-14
1.15
0.93, 1.41
0.2
15-19
0.99
0.79, 1.24
>0.9
20-29
1.03
0.84, 1.26
0.8
30-49
1.06
0.85, 1.33
0.6
50-69
0.68
0.40, 1.13
0.14
70+
0.52
0.07, 3.19
0.5
1
OR = Odds Ratio, CI = Confidence Interval
También puedes combinar varias tablas producidas por gtsummary con la función tbl_merge(). En este ejemplo combinaremos los resultados multivariables con los resultados univariantes de gtsummary que creamos anteriormente:
## combinar con resultados univariantes tbl_merge(tbls =list(univ_tab, mv_tab), # combinatab_spanner =c("**Univariate**", "**Multivariable**")) # establece los nombres de las cabeceras
Characteristic
Univariate
Multivariable
N
OR
1
95% CI
1
p-value
OR
1
95% CI
1
p-value
gender
4,167
1.00
0.88, 1.13
>0.9
1.00
0.88, 1.14
>0.9
fever
4,167
1.00
0.85, 1.17
>0.9
1.00
0.86, 1.18
>0.9
chills
4,167
1.03
0.89, 1.21
0.7
1.03
0.89, 1.21
0.7
cough
4,167
1.15
0.97, 1.37
0.11
1.15
0.96, 1.37
0.12
aches
4,167
0.93
0.76, 1.14
0.5
0.93
0.76, 1.14
0.5
vomit
4,167
1.09
0.96, 1.23
0.2
1.09
0.96, 1.23
0.2
age_cat
4,167
0-4
—
—
—
—
5-9
0.94
0.77, 1.15
0.5
0.94
0.77, 1.15
0.5
10-14
1.15
0.93, 1.42
0.2
1.15
0.93, 1.41
0.2
15-19
0.99
0.80, 1.24
>0.9
0.99
0.79, 1.24
>0.9
20-29
1.03
0.84, 1.26
0.8
1.03
0.84, 1.26
0.8
30-49
1.07
0.85, 1.33
0.6
1.06
0.85, 1.33
0.6
50-69
0.68
0.41, 1.13
0.13
0.68
0.40, 1.13
0.14
70+
0.53
0.07, 3.20
0.5
0.52
0.07, 3.19
0.5
1
OR = Odds Ratio, CI = Confidence Interval
Combinar con dplyr
Una forma alternativa de combinar los resultados univariables y multivariables de glm()/tidy() es con las funciones join de dplyr.
Unimos los resultados univariantes obtenidos anteriormente (univ_tab_base, que contiene los recuentos) con los resultados multivariables en formato tidy de mv_tab_base.
Utilizamos select() para mantener sólo las columnas que queremos, especificar su orden y renombrarlas
Empleamos round() con dos decimales en todas las columnas que sean de tipo “Double”.
## combine univariate and multivariable tables left_join(univ_tab_base, mv_tab_base, by ="term") %>%## choose columns and rename themselect( # new name = old name"characteristic"= term, "recovered"="0", "dead"="1", "univ_or"= estimate.x, "univ_ci_low"= conf.low.x, "univ_ci_high"= conf.high.x,"univ_pval"= p.value.x, "mv_or"= estimate.y, "mvv_ci_low"= conf.low.y, "mv_ci_high"= conf.high.y,"mv_pval"= p.value.y ) %>%mutate(across(where(is.double), round, 2))
Esta sección muestra cómo producir un gráfico con los resultados de tu regresión. Hay dos opciones, puedes construir un gráfico tú mismo usando ggplot2 o usar un metapaquete llamado easystats (un paquete que incluye muchos paquetes).
Consulta la página sobre Conceptos básicos de ggplot si no estás familiarizado con el paquete de gráficos ggplot2.
Paquete ggplot2
Puedes construir un gráfico de bosque con ggplot() trazando elementos de los resultados de la regresión multivariable. Añade las capas de los gráficos utilizando estos “geoms”:
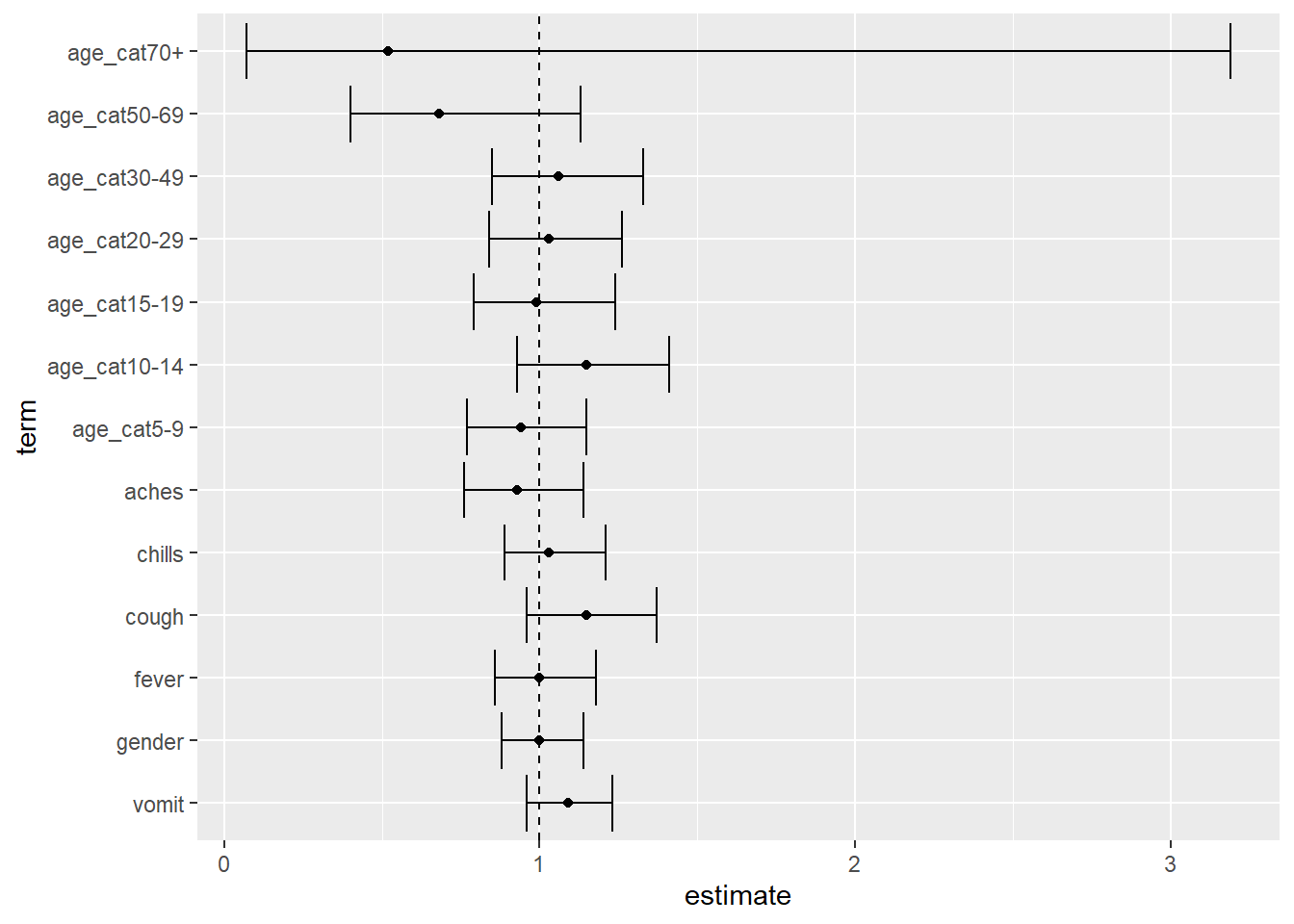
Añadimos estimaciones con geom_point()
Añadimos intervalos de confianza con geom_errorbar()
Ploteamos una línea vertical en OR = 1 con geom_vline()
Antes de empezar a plotear, es posible que sea necesario utilizar fct_relevel() del paquete forcats para establecer el orden de las variables/niveles en el eje y. De no establecer un orden en las variables, ggplot() podría mostrar las variables en orden alfanumérico, lo que no funcionaría bien para los valores de categoría de edad (“30” aparecería antes de “5”). Mira la página sobre Factores para más detalles.
## eliminar el término de intercepción de los resultados multivariantesmv_tab_base %>%# establece el orden de los niveles que aparecerán en el eje-ymutate(term =fct_relevel( term,"vomit", "gender", "fever", "cough", "chills", "aches","age_cat5-9", "age_cat10-14", "age_cat15-19", "age_cat20-29","age_cat30-49", "age_cat50-69", "age_cat70+")) %>%# eliminar la fila "intercept" del gráficofilter(term !="(Intercept)") %>%## gráfico con la variable en el eje y y la estimación (OR) en el eje-xggplot(aes(x = estimate, y = term)) +## muestra la estimación como un puntogeom_point() +## añadir una barra de error para los intervalos de confianzageom_errorbar(aes(xmin = conf.low, xmax = conf.high)) +## mostrar como línea discontinua dónde está OR = 1 como referenciageom_vline(xintercept =1, linetype ="dashed")
Paquetes easystats
Una alternativa, si no deseas el nivel de precisión y control que proporciona ggplot2, es utilizar la combinación de paquetes easystats.
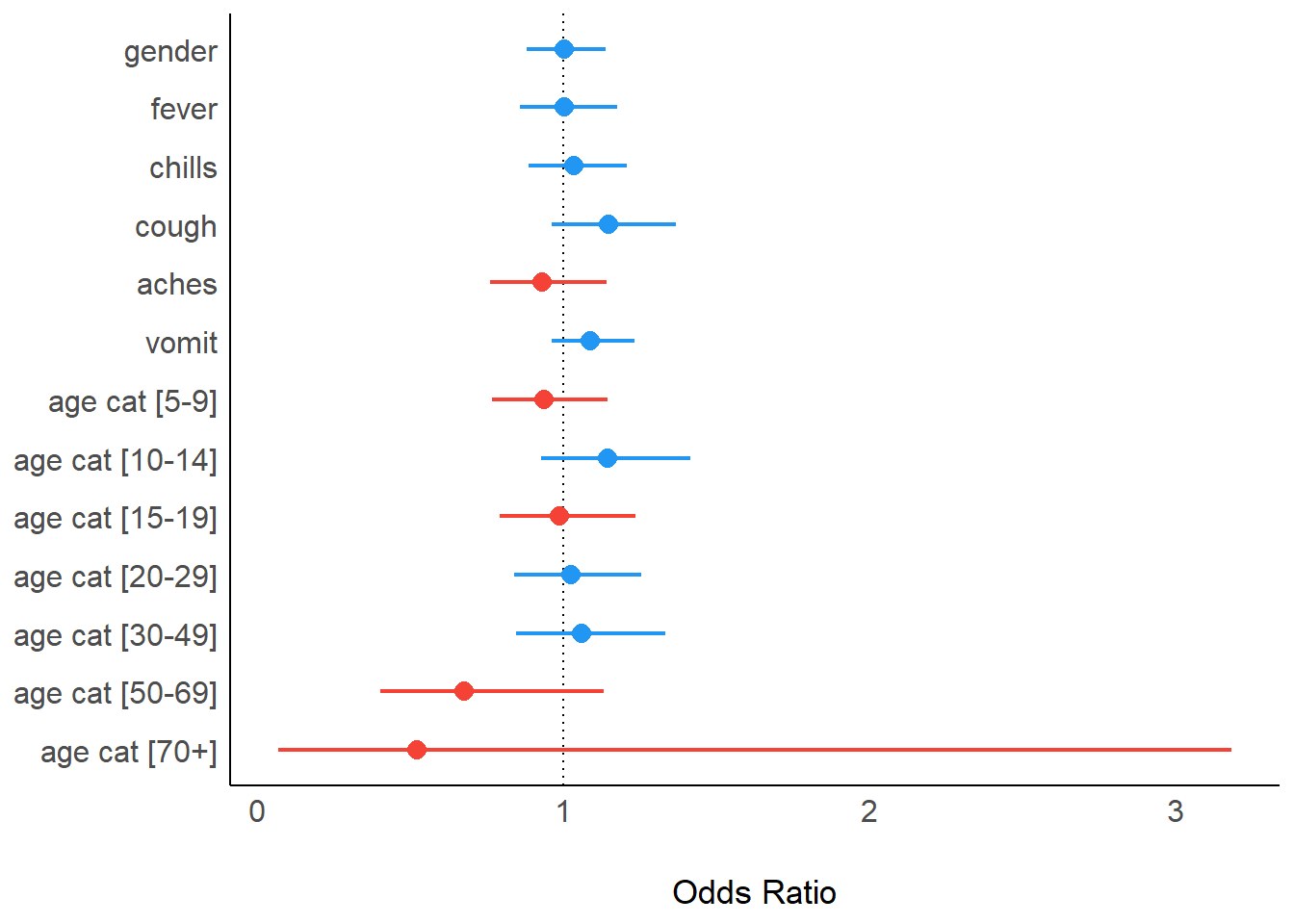
La función model_parameters() del paquete parameters hace el equivalente de la función tidy() del paquete broom. El paquete see acepta esos resultados y crea por defecto un forest plot, dándo como output un objeto ggplot().
pacman::p_load(easystats)## eliminar el término de intercepción de los resultados multivariantesfinal_mv_reg %>%model_parameters(exponentiate =TRUE) %>%plot()
19.6 Recursos
El contenido de esta página se ha basado en estos recursos y viñetas: