![]()
4 Transição para o R
Abaixo, fornecemos alguns conselhos e recursos se você estiver fazendo a transição para o R.
O R foi lançado no final dos anos 90 e desde então, seu escopo tem crescido dramaticamente. Suas capacidades são tão amplas que programas alternativos comerciais reagiram ao surgimento do R para se manterem competitivas! (leia este artigo comparando R, SPSS, SAS, STATA, e Python).
Além disso, o R é muito mais fácil de aprender do que era há 10 anos. Anteriormente, o R tinha a reputação de ser difícil para os iniciantes. Agora é muito mais fácil de aprender, com interfaces de usuário amigáveis como RStudio, código intuitivo como o tidyverse, e muitos recursos tutoriais.
Não se sinta intimidado - venha descobrir o mundo do R!
4.1 Partindo do Excel
A transição do Excel diretamente para R é uma meta muito viável. Pode parecer assustador, mas você consegue fazer isso!
É verdade que alguém com fortes habilidades no Excel pode fazer atividades muito avançadas somente no Excel - até mesmo usando ferramentas de programação em código como VBA. O Excel é usado em todo o mundo e é uma ferramenta essencial para um epidemiologista. Entretanto, complementá-lo com R pode melhorar drasticamente e expandir seus fluxos de trabalho.
Benefícios
Você descobrirá que o uso de R oferece imensos benefícios, desde tempo economizado, análises mais consistentes e precisas, reprodutibilidade, compartilhabilidade e correção mais rápida de erros. Como qualquer software novo, há uma “curva” de aprendizado que reflete o tempo que você deve investir para se familiarizar em ele. Os dividendos serão significativos e um imenso escopo de novas possibilidades se abrirá para você com o R.
Excel é um software bem conhecido que pode ser fácil para um iniciante usar para produzir análises e visualizações simples com o “apontar e clicar”. Em comparação, pode levar algumas semanas para se tornar confortável com as funções e a interface do R. No entanto, o R evoluiu nos últimos anos para se tornar muito mais amigável para iniciantes.
Muitos fluxos de trabalho do Excel dependem da memória e da repetição - portanto, há muitas oportunidades de erro. Além disso, geralmente a limpeza de dados, a metodologia de análise e as equações utilizadas são ocultadas da vista. Pode ser necessário um tempo substancial para que um novo colega aprenda o que uma pasta de trabalho Excel está fazendo e como resolvê-la. Com R, todas as etapas são explicitamente escritas no script e podem ser facilmente visualizadas, editadas, corrigidas e aplicadas a outros conjuntos de dados.
Para iniciar sua transição do Excel para o R, você deve ajustar sua mentalidade de algumas maneiras importantes:
Dados bem arrumados (tidy data)
Use dados “arrumados” (tidy), isto é, que sejam legíveis para a máquina em vez de dados bagunçados, que são apenas “legíveis para humanos”. Estes são os três principais requisitos para dados do tipo “tidy”, como explicado neste tutorial sobre dados “tidy” em R:
- Cada variável deve ter sua própria coluna
- Cada observação deve ter sua própria linha
- Cada valor deve ter sua própria célula
Para os usuários do Excel - pense no papel que as “tabelas” Excel desempenham na padronização dos dados e na maior previsibilidade do formato.
Um exemplo de dados “tidy” seria a lista (linelist) de casos utilizada ao longo deste manual - cada variável está contida dentro de uma coluna, cada observação (um caso) tem sua própria linha, e cada valor está em apenas uma célula. Abaixo você pode ver as primeiras 50 linhas desta linelist:
O principal motivo pelo qual entramos dados não-arrumados por aí (non-tidy) se deve ao fato de muitas planilhas Excel serem projetadas para priorizar a leitura fácil por humanos, não a leitura fácil por máquinas/software.
Para ajudá-lo a ver a diferença, abaixo estão alguns exemplos fictícios de dados não-arrumados que priorizam leitura por humanos em vez de leitura por máquina:
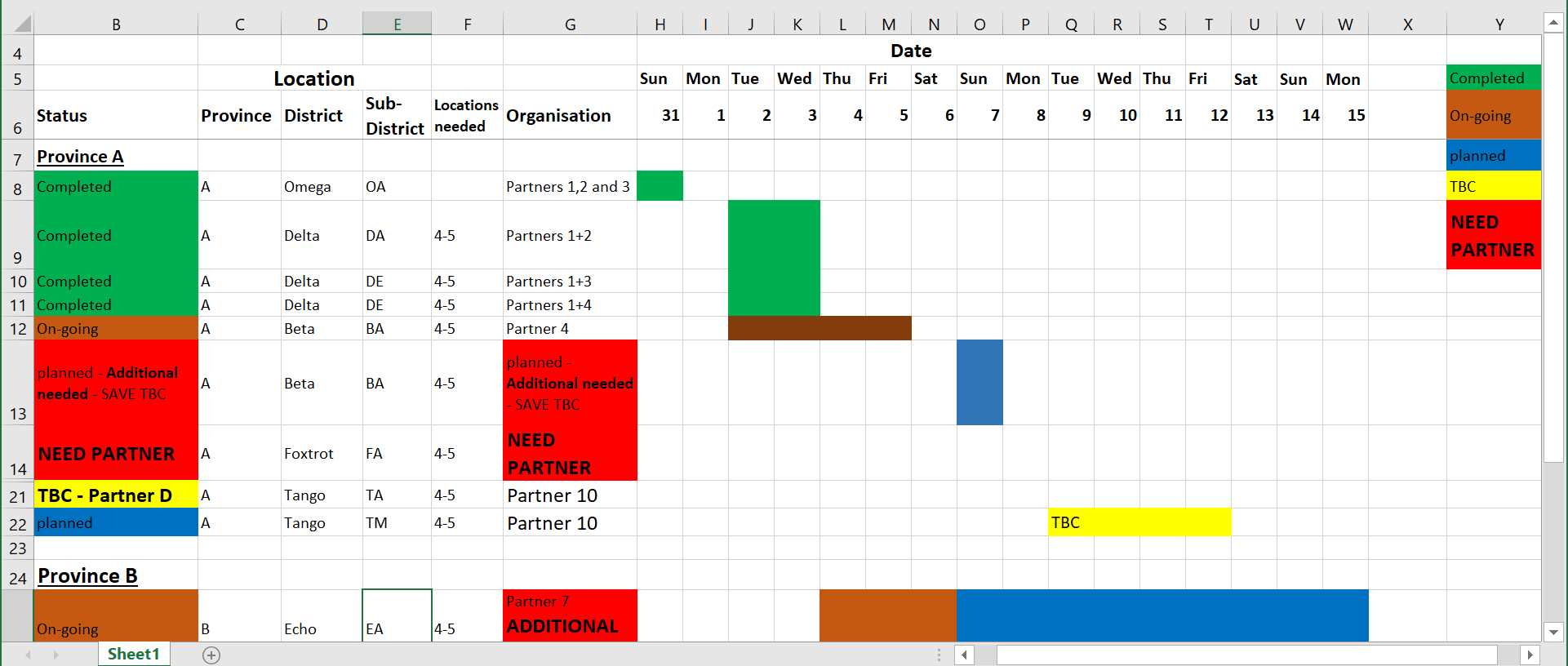
Problemas: Na planilha acima, há células mescladas que não são facilmente digeridas pelo R. Qual linha deve ser considerada o “cabeçalho” não está totalmente clara. Um dicionário baseado em cores está do lado direito e os valores das células são representados por cores - o que também não é facilmente interpretado pelo R (nem por humanos daltônicos!). Além disso, diferentes pedaços de informação são combinados em uma célula (múltiplas organizações parceiras trabalhando em uma área, ou o status “TBC” na mesma célula que “Parceiro (partner) D”).
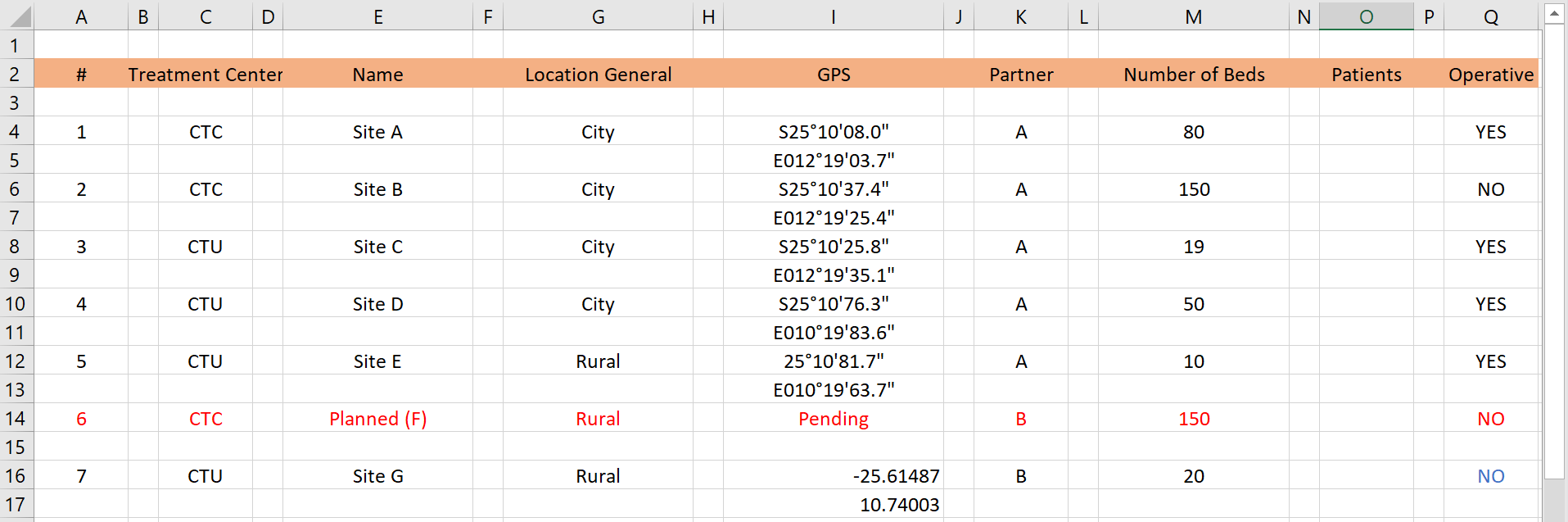
Problemas: Na planilha acima, há numerosas linhas e colunas vazias extras dentro do conjunto de dados - isto causará dores de cabeça para a limpeza do banco no R. Além disso, as coordenadas GPS estão espalhadas por duas linhas para um determinado centro de tratamento. Como nota lateral - as coordenadas GPS estão em dois formatos diferentes!
Os conjuntos de dados “tidy” podem não ser tão legíveis a um olho humano, mas tornam a limpeza e análise dos dados muito mais fácil! Dados “tidy” podem ser armazenados em vários formatos, por exemplo “longo/comprido” (long) ou “largo/amplo” (wide) (ver página em Pivotando dados), mas os princípios acima serão sempre observados.
Funções
A palavra “função” em R pode ser nova, mas o conceito também existe no Excel como fórmulas. As fórmulas no Excel também requerem sintaxe precisa (por exemplo, colocação de ponto-e-vírgula e parênteses). Tudo o que você precisa fazer é aprender algumas novas funções e como elas funcionam juntas em R.
Scripts
Em vez de clicar nos botões e arrastar as células, você estará escrevendo todos os passos e procedimentos em um “roteiro” (daqui em diante referido como script). Os usuários do Excel podem estar familiarizados com “macros VBA” que também empregam uma abordagem de códigos de programação.
O script R consiste de instruções passo a passo. Isto permite que qualquer colega leia o script e veja facilmente os passos que você deu. Isto também ajuda a eliminar erros ou cálculos imprecisos. Veja a seção Introdução ao R sobre scripts para exemplos.
Aqui está um exemplo de um script em R:
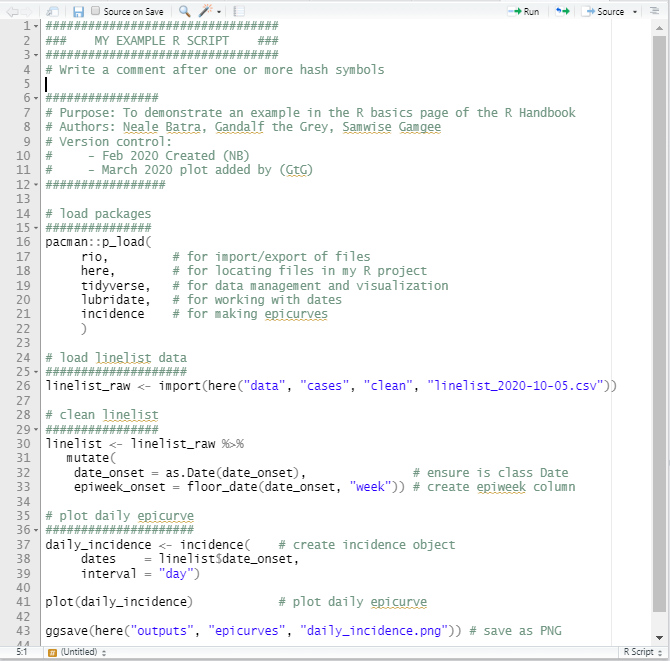
Do Excel-para-R: recursos
Interação R-Excel
R tem formas robustas de importar pastas de trabalho do Excel, trabalhar com os dados, exportar/guardar arquivos Excel e trabalhar com as nuances das planilhas Excel.
É verdade que algumas das formatações mais estéticas do Excel podem se perder na tradução (por exemplo, itálico, texto lateral, etc.). Se seu fluxo de trabalho exigir a passagem de documentos entre R e Excel enquanto mantém a formatação original do Excel, tente pacotes como openxlsx*.
4.2 Partindo do Stata
Vindo do Stata para R*
Muitos epidemiologistas são ensinados primeiro a usar Stata, e pode parecer assustador mudar para R. Entretanto, se você é um usuário confortável de Stata, então o salto para R é certamente mais manejável do que você possa pensar. Embora existam algumas diferenças chave entre Stata e R em como os dados podem ser criados e modificados, bem como a maneira que as funções de análise são implementadas - após aprender estas diferenças chave você será capaz de adaptar suas habilidades.
Abaixo estão algumas traduções chave entre Stata e R, que podem ser úteis como sua revisão deste guia.
Notas gerais
| STATA | R |
|---|---|
| Você só pode visualizar e manipular um conjunto de dados de cada vez | Você pode visualizar e manipular vários conjuntos de dados ao mesmo tempo, portanto você terá que especificar freqüentemente seu conjunto de dados dentro do código |
| Comunidade online disponível por meio de https://www.statalist.org/ | Comunidade online disponível por meio de RStudio, StackOverFlow, e R-bloggers |
| Funcionalidade “apontar e clicar” como opção | Funcionalidade “apontar e clicar” mínima |
Ajuda para comandos disponíveis por help [comando]
|
Ajuda disponível por ?função ou busca no painel de Ajuda |
| Comentar código usando * ou /// ou /* TEXTO */ | Comentar código usando # |
| Quase todos os comandos são nativos ao Stata. Funções novas/escritas pelo usuário podem ser instaladas como arquivos ado* usando ssc install [pacote] | A instalação do R vem com funções base , mas o uso típico envolve a instalação de outros pacotes do CRAN (veja página em Introdução ao R) |
| A análise é geralmente escrita em um arquivo do | Análise escrita em um script R no painel de fontes do RStudio. Scripts em R Markdown são uma alternativa. |
Diretório de trabalho
| STATA | R |
|---|---|
| Os diretórios de trabalho envolvem caminhos de arquivo absolutos (por exemplo, “C:/ nome do usuário/documentos/projetos/dados/”) | Os diretórios de trabalho podem ser absolutos, ou relativos a uma pasta raiz do projeto usando o pacote here (ver Importar e exportar) |
| Ver diretório de trabalho atual com pwd | Utilize getwd() ou here() (se utilizar o pacote here), com parênteses vazios |
| Definir diretório de trabalho com cd “localização de pasta” | Utilize setwd("localização de pasta"), ou set_here("localização de pasta") (se estiver utilizando here* pacote) |
Importando e visualizando dados
| STATA | R |
|---|---|
| Comandos específicos por tipo de arquivo | Utilize import() do pacote rio para quase todos os tipos de arquivo. Existem funções específicas como alternativas (ver Importar e exportar) |
| A leitura em arquivos csv é feita por importar delimited “filename.csv”. | Use import("nomedoarquivo.csv")
|
| A leitura em arquivos xslx é feita por import excel “filename.xlsx” | Use import("nomedoarquivo.xlsx")
|
| Navegue seus dados em uma nova janela utilizando o comando browse | Visualize um conjunto de dados no painel de origem do RStudio utilizando View(conjunto de dados). Você precisa especificar o nome de seu conjunto de dados para a função em R porque vários conjuntos de dados podem ser mantidos ao mesmo tempo. Note “V” maiúsculo nesta função. |
| Obtenha uma visão geral do seu conjunto de dados utilizando summarize, que fornece os nomes das variáveis e informações básicas | Obtenha uma visão geral do seu conjunto de dados utilizando summary(conjunto de dados). |
Manipulações básicas de dados
| STATA | R |
|---|---|
| As colunas do conjunto de dados são frequentemente referidas como “variáveis” | Mais frequentemente referidas como “colunas” ou às vezes como “vetores” ou “variáveis”. |
| Não é necessário especificar o conjunto de dados | Em cada um dos comandos abaixo, você precisa especificar o conjunto de dados - veja a página em Limpeza de dados e principais funções para exemplos |
| Novas variáveis são criadas utilizando o comando generate nome_var = | Gerar novas variáveis utilizando a função mutate(nome_var = ). Consulte a página Limpeza de dados e principais funções para obter detalhes sobre todas as funções abaixo dplyr*. |
| As variáveis são renomeadas utilizando rename nome_antigo nome_novo | Colunas podem ser renomeadas utilizando a função rename(novo_nome = nome_antigo)
|
| As variáveis são descartadas utilizando drop nome_var | As colunas podem ser removidas utilizando a função select() com o nome da coluna entre parênteses, seguindo um sinal de subtração |
| As variáveis fatoriais podem ser etiquetadas usando uma série de comandos como label define | Os valores de etiquetagem podem ser feitos convertendo a coluna para a classe fator e especificando níveis. Veja a página em Fatores. Os nomes das colunas não são tipicamente etiquetados como estão na Stata. |
Análise descritiva
| STATA | R |
|---|---|
| Tabula contagens de uma variável utilizando tab nome_var | Forneça o conjunto de dados e nome da coluna para table() tal como table(dataset$nome_da_coluna). Alternativamente, utilize count(nome_var) do pacote dplyr, como explicado em Agrupando dados. |
| Uma tabela de contingência de duas variáveis em uma tabela 2x2 é feito com tab nome_var1 nome_var2 | Use table(dataset$nome_var1, dataset$nome_var2 ou count(nome_var1, nome_var2)
|
Embora esta lista dê uma visão geral dos conceitos básicos na tradução dos comandos Stata em R, ela não é completa. Há muitos outros grandes recursos para os usuários da Stata em transição para R que poderiam ser de interesse:
- https://dss.princeton.edu/training/RStata.pdf
- https://clanfear.github.io/Stata_R_Equivalency/docs/r_stata_commands.html
- http://r4stats.com/books/r4stata/
4.3 Partindo do SAS
Vindo da SAS para R*
O SAS é comumente usado em agências de saúde pública e campos de pesquisa acadêmica. Embora a transição para um novo idioma raramente seja um processo simples, compreender as diferenças-chave entre SAS e R pode ajudá-lo a começar a navegar no novo idioma usando seu idioma nativo. A seguir, descrevemos as principais traduções no gerenciamento de dados e análise descritiva entre a SAS e o R.
Notas gerais
| SAS | R |
|---|---|
| Comunidade online disponível em SAS Customer Support | Comunidade online disponível em RStudio, StackOverFlow, e R-bloggers |
Ajuda para os comandos disponíveis por help [comando]
|
Ajuda disponível por ?função ou busca no painel de Ajuda |
Comentar código utilizando * TEXT ; ou /* TEXT */
|
Comentar código utilizando # |
Quase todos os comandos são nativos. Os usuários podem escrever novas funções utilizando a macro SAS, SAS/IML, SAS Component Language (SCL) e, mais recentemente, procedimentos Proc Fcmp e Proc Proto
|
A instalação do R vem com as funções base, mas o uso típico envolve a instalação de outros pacotes do CRAN (veja a página em Introdução ao R) |
| A análise é geralmente conduzida escrevendo um programa SAS na janela do Editor. | Análise escrita em um script R no painel fonte do RStudio. Scripts em R Markdown são uma alternativa. |
Diretório de trabalho
| SAS | R |
|---|---|
Os diretórios de trabalho podem ser absolutos ou relativos a uma pasta raiz do projeto, definindo a pasta raiz utilizando %let rootdir=/root path; %include "&rootdir/subfoldername/nome_arqquivo"
|
Os diretórios de trabalho podem ser absolutos ou relativos a uma pasta raiz do projeto utilizando o pacote here (ver Importar e exportar) |
Veja o diretório de trabalho atual com % de produção %sysfunc(getoption(work));
|
Use getwd() ou here() (se utilizar o pacote here), com parênteses vazios |
Definir diretório de trabalho com libname "localização de pasta"
|
Use setwd("localização de pasta"), ou set_here("localização de pasta) se utilizar o pacote here. |
Importando e visualizando dados
| SAS | R |
|---|---|
Utilize o procedimento Proc Importar' ou utilize a declaraçãoData Step Infile’. |
Utilize a função import() do pacote rio para quase todos os tipos de arquivos. Existem funções específicas como alternativas (ver Importar e exportar). |
A leitura em arquivos csv é feita utilizando Proc Import datafile="nome_arqquivo.csv" out=work.nome_arqquivo dbms=CSV; run; ou usando Data Step Infile statement
|
Use import("nome_arqquivo.csv")
|
A leitura em arquivos xslx é feita utilizando Proc Import datafile="nome_arqquivo.xlsx" out=work.nome_arqquivo dbms=xlsx; run; ou usando Data Step Infile statement
|
Use import(“nome_arqquivo.xlsx”) |
| Navegue pelos seus dados em uma nova janela abrindo a janela do Explorer e selecione a biblioteca desejada e o conjunto de dados | Veja um conjunto de dados no painel de fontes do RStudio usando View(dataset). Você precisa especificar o nome de seu conjunto de dados para a função em R porque vários conjuntos de dados podem ser mantidos ao mesmo tempo. atenção para “V” maiúsculo nesta função |
Manipulações básicas de dados
| SAS | R |
|---|---|
| As colunas do conjunto de dados são frequentemente referidas como “variáveis” | Mais frequentemente referidas como “colunas” ou às vezes como “vetores” ou “variáveis”. |
| Não são necessários procedimentos especiais para criar uma variável. Novas variáveis são criadas simplesmente digitando o novo nome da variável, seguido por um sinal de igual e, em seguida, uma expressão para o valor | Gere novas variáveis utilizando a função mutate(). Consulte a página Limpeza de dadps e principais funções para obter detalhes sobre todas as funções abaixo dplyr. |
As variáveis são renomeadas utilizando renome *nome_antigo=nome_novo*
|
As colunas podem ser renomeadas utilizando a função rename(novo_nome = nome_antigo)
|
As variáveis são mantidas utilizando **keep**=nome_var
|
Colunas podem ser selecionadas utilizando a função select() com o nome da coluna entre parênteses |
As variáveis são descartadas utilizando **drop**=nome da coluna
|
As colunas podem ser removidas utilizando a função select() com o nome da coluna entre parênteses, seguindo um sinal de subtração |
| As variáveis do tipo fator podem ser etiquetadas na Etapa de Dados, utilizando a declaração de ‘Label’ | Os valores do rótulo podem ser feitos convertendo a coluna para a classe Fator e especificando níveis. Veja a página em Fatores. Os nomes das colunas não são tipicamente rotulados. |
Os registros são selecionados utilizando a instrução Where ou If na Etapa de Dados. As condições de seleção múltipla são separadas utilizando o comando “and”. |
Os registros são selecionados utilizando a função filter() com condições de seleção múltipla separadas por um operador AND (&) ou por uma vírgula |
Os conjuntos de dados são combinados utilizando a declaração Merge na Etapa de Dados. Os conjuntos de dados a serem fundidos precisam ser ordenados primeiro utilizando o procedimento Proc Sort. |
O pacote dplyr oferece algumas funções para fundir conjuntos de dados. Consulte a página Agrupando Dados para obter detalhes. |
Análise descritiva
| SAS | R |
|---|---|
| Obtenha uma visão geral do seu conjunto de dados utilizando o procedimento “Proc Summary”, que fornece os nomes das variáveis e as estatísticas descritivas. | Obtenha uma visão geral do seu conjunto de dados utilizando o “summary(conjunto_de_dados)” ou “skimr(conjunto_de_dados)” do pacote skimr. |
Tabular contagens de uma variável utilizando proc freq data=Dataset; Tables varname; Run;
|
Ver a página em Tabelas descritivas. As opções incluem table() do R base, e tabyl() do pacote janitor , entre outras. Observe que você precisará especificar o conjunto de dados e o nome da coluna, pois R contém vários conjuntos de dados. |
A tabulação cruzada (tabela de contingência) de duas variáveis em uma tabela 2x2 é feita com proc freq data=Dataset; Tables rowvar*colvar; Run;
|
Novamente, você pode utilizar table(), tabyl() ou outras opções como descritas na página Tabelas descritivas. |
Alguns recursos úteis:
4.4 Interoperabilidade de dados
Veja a página Importar e exportar para detalhes sobre como o pacote rio do R pode importar e exportar arquivos como arquivos STATA .dta, arquivos SAS .xpt e.sas7bdat, arquivos SPSS .por e.sav, e muitos outros.