## paketleri CRAN'dan yükle
pacman::p_load(rio, # Dosya içe aktarma
here, # Dosya bulucu
tidyverse, # veri yönetimi + ggplot2 grafikleri
tsibble, # zaman serisi veri kümelerini işleme
survey, # anket işlevleri için
srvyr, # anket paketi için dplyr sarmalayıcı
gtsummary, # tablolar üretmek için anket paketi için sarıcı
apyramid, # yaş piramitleri oluşturmaya adanmış bir paket
patchwork, # ggplot'ları birleştirmek için
ggforce # alüvyon/sankey grafikleri için
)
## paketleri github'dan yükle
pacman::p_load_gh(
"R4EPI/sitrep" # gözlem süresi / ağırlıklandırma fonksiyonları için
)26 Anket analizi
26.1 Genel bakış
Bu sayfa, anket analizi için çeşitli paketlerin kullanımını göstermektedir.
Çoğu anket R paketleri, ağırlıklı analiz yapmak için survey paketine güvenir. survey paketinin yanı sıra srvyr (tidyverse-stili kodlamaya izin veren bir survey sarmalayıcısı) ve gtsummary (yayına hazır tablolara izin veren bir survey sarmalayıcısı) kullanacağız. Orijinal survey paketi tidyverse-stili kodlamaya izin vermese de, anket ağırlıklı genelleştirilmiş doğrusal modellere izin verme avantajına sahiptir (bu sayfaya daha sonraki bir tarihte eklenecektir). Örnekleme ağırlıkları oluşturmak için sitrep paketinden bir fonksiyonu kullanmayı da göstereceğiz (n.b , bu paket şu anda CRAN’da değil, ancak github’dan kurulabilir).
Bu sayfanın çoğu “R4Epis” projesi için yapılan çalışmalara dayanmaktadır; ayrıntılı kod ve R-markdown şablonları için “R4Epis” github sayasına bakabilirsiniz. survey paketine ait kodlardan bazıları, EPIET vaka çalışmalarının ilk sürümlerini temel almaktadır.
Şu anda bu sayfa, örneklem büyüklüğü hesaplamalarını veya örneklemeyi ele almamaktadır. Örnek boyutu hesaplayıcıyı kullanmak için basit bir kullanım için OpenEpi’ye bakabilirsiniz. El kitabının GIS temelleri sayfasında eninde sonunda uzamsal rastgele örnekleme üzerine bir bölüm mevcuttur ve bu sayfa sonunda örnekleme çerçeveleri ve örnek boyutu hesaplamaları hakkında bir bölüme sahip olacaktır.
- Anket verisi
- Gözlem süresi
- Ağırlıklandırma
- Anket tasarım nesneleri
- Tanımlayıcı analiz
- Ağırlıklı orantılar
- Ağırlıklı hızlar
26.2 Hazırlık
Paketler
Bu kod parçası, analizler için gereken paketlerin yüklenmesini gösterir. Bu el kitabında, gerekirse paketi kuran ve kullanım için yükleyen pacman paketinden p_load() fonksiyonunu kullanacağız. Ayrıca R tabanı’dan library() ile paketleri yükleyebilirsiniz. R paketleri hakkında daha fazla bilgi için [R temelleri] sayfasına bakabilirsiniz.
Burada ayrıca, github’dan henüz CRAN’da yayınlanmayan bir paketi yüklemek için pacman paketinden p_load_gh() fonksiyonunu kullanmayı gösteriyoruz.
Veri yükleme
Bu bölümde kullanılan örnek veri kümeleri aşağıda listelenmiştir:
- kurgusal ölüm anketi verileri.
- araştırma alanı için kurgusal nüfus sayımları.
- kurgusal ölüm anketi verileri için veri sözlüğü.
Bu, MSF OCA etik inceleme kurulu tarafından önceden onaylanmış ankete dayanmaktadır. Kurgusal veri seti “R4Epis” projesi kapsamında üretilmiştir. Bunların tümü, Open Data Kit’e dayalı bir veri toplama yazılımı olan KoboToolbox kullanılarak toplanan verilere dayanmaktadır.
Kobo, hem toplanan verileri hem de bu veri kümesi için veri sözlüğünü dışa aktarmanıza olanak tanır. Veri temizlemeyi basitleştirdiği ve değişkenleri/soruları aramak için kullanışlı olduğu için bunu yapmanızı şiddetle tavsiye etmekteyiz.
İPUCU: Kobo veri sözlüğünün anket sayfasının “name” sütununda değişken adları vardır. Her değişken için olası değerler, seçenekler sayfasında belirtilmiştir. Seçenekler sekmesinde “name” kısaltılmış değere sahiptir ve “label::english” ve “label::french” sütunları gerekli uzun versiyonlara da sahiptir. Bir Kobo sözlük excel dosyasını içe aktarmak için epidict paketi msf_dict_survey() fonksiyonunu kullanarak bu adları otomatik olarak yeniden biçimlendirebilirsiniz. Bu sayede kodlarınızı tekrardan kullanma şansınız olur.
DİKKAT: Bu örnek veri kümesi dışa aktarılan formatı ile aynı değildir (Kobo’da farklı anket düzeylerini ayrı ayrı dışa aktardığınız gibi) - farklı düzeyleri birleştirmek için aşağıdaki anket verileri bölümüne bakmalısınız.
Veri kümesi, rio paketinden import() fonksiyonu kullanılarak içe aktarılır. Verileri içe aktarmanın çeşitli yolları için İçe ve dışa aktarma sayfasına bakın.
# anket verilerini içe aktar
survey_data <- rio::import("survey_data.xlsx")
# sözlüğü R’ın içine aktar
survey_dict <- rio::import("survey_dict.xlsx") Anketin ilk 10 satırı aşağıda gösterilmiştir.
Uygun ağırlıklar üretebilmemiz için örneklem popülasyonundaki verileri de içe aktarmak istiyoruz. Bu veriler farklı formatlarda olabilir, ancak aşağıda görüldüğü gibi olmasını öneririz (bu sadece bir excel’e yazılabilir).
# nüfus verilerini içe aktar
population <- rio::import("population.xlsx")Anketin ilk 10 satırı aşağıda gösterilmiştir.
Küme anketleri için küme düzeyinde anket ağırlıkları eklemek isteyebilirsiniz. Bu verileri yukarıdaki gibi okuyabilirsiniz. Alternatif olarak, yalnızca birkaç sayı varsa, bunlar bir tibble’a aşağıdaki gibi girilebilir. Her durumda, anket verilerinizle eşleşen bir küme tanımlayıcısına sahip bir sütuna ve her bir kümedeki hane sayısını içeren başka bir sütuna ihtiyacınız olacaktır.
## her kümedeki hane sayısını tanımla
cluster_counts <- tibble(cluster = c("village_1", "village_2", "village_3", "village_4",
"village_5", "village_6", "village_7", "village_8",
"village_9", "village_10"),
households = c(700, 400, 600, 500, 300,
800, 700, 400, 500, 500))Veri temizleme
Aşağıdaki kodlar, tarih sütununun uygun biçimde olmasını sağlar. Bunu yapmanın başka yolları da vardır (ayrıntılar için Tarihlerle çalışma sayfasına bakın), ancak tarihleri tanımlamak için sözlüğü kullanmak hızlı ve kolaydır.
Ayrıca **epikit* paketindeki age_categories() fonksiyonunu kullanarak bir yaş grubu değişkeni oluşturuyoruz - ayrıntılar için el kitabındaki Verileri temizleme bölümüne bakabilirsiniz. Ek olarak, çeşitli kümelerin hangi bölgede olduğunu tanımlayan bir karakter değişkeni oluşturuyoruz.
Son olarak, tüm evet/hayır değişkenlerini DOĞRU/YANLIŞ değişkenlere yeniden kodlarız - aksi takdirde bunlar survey orantı fonksiyonları tarafından kullanılamaz.
## sözlükten tarih değişkeni adlarını seç
DATEVARS <- survey_dict %>%
filter(type == "date") %>%
filter(name %in% names(survey_data)) %>%
## filter to match the column names of your data
pull(name) # select date vars
## tarihleri değiştir
survey_data <- survey_data %>%
mutate(across(all_of(DATEVARS), as.Date))
## yıl değişkenine yalnızca ay cinsinden yaşı olanları ekle (on ikiye böl)
survey_data <- survey_data %>%
mutate(age_years = if_else(is.na(age_years),
age_months / 12,
age_years))
## yaş grubu değişkenini tanımla
survey_data <- survey_data %>%
mutate(age_group = age_categories(age_years,
breakers = c(0, 3, 15, 30, 45)
))
## farklı bir değişkenin gruplarına dayalı bir karakter değişkeni oluştur
survey_data <- survey_data %>%
mutate(health_district = case_when(
cluster_number %in% c(1:5) ~ "district_a",
TRUE ~ "district_b"
))
## sözlükten evet/hayır değişken isimlerini seç
YNVARS <- survey_dict %>%
filter(type == "yn") %>%
filter(name %in% names(survey_data)) %>%
## filter to match the column names of your data
pull(name) # select yn vars
## tarihleri değiştir
survey_data <- survey_data %>%
mutate(across(all_of(YNVARS),
str_detect,
pattern = "yes"))Warning: There was 1 warning in `mutate()`.
ℹ In argument: `across(all_of(YNVARS), str_detect, pattern = "yes")`.
Caused by warning:
! The `...` argument of `across()` is deprecated as of dplyr 1.1.0.
Supply arguments directly to `.fns` through an anonymous function instead.
# Previously
across(a:b, mean, na.rm = TRUE)
# Now
across(a:b, \(x) mean(x, na.rm = TRUE))26.3 Anket verisi
Anketler için kullanılabilecek çok sayıda farklı örnekleme tasarımı vardır. Burada şu kodları göstereceğiz: - Tabakalı - Küme - Tabakalı ve küme
Yukarıda açıklandığı gibi (anketinizi nasıl tasarladığınıza bağlı olarak) her seviye için veriler Kobo’dan ayrı bir veri seti olarak dışa aktarılacaktır. Örneğimizde, haneler için bir düzey ve bu hanelerdeki bireyler için bir düzey vardır.
Bu iki seviye benzersiz bir tanımlayıcı ile birbirine bağlanır. Bir Kobo veri kümesi için bu değişken, bireysel düzeyde “_parent_index” ile eşleşen hane düzeyinde “_index” dir. Bu, eşleşen her bireyle hane için yeni satırlar oluşturacaktır, ayrıntılar için Verileri ekleme ilgili el kitabı bölümüne bakabilirsiniz.
## eksiksiz bir veri seti oluşturmak için bireysel ve hane verilerini birleştir
survey_data <- left_join(survey_data_hh,
survey_data_indiv,
by = c("_index" = "_parent_index"))
## iki düzeyin endekslerini birleştirerek benzersiz bir tanımlayıcı oluştur
survey_data <- survey_data %>%
mutate(uid = str_glue("{index}_{index_y}"))26.4 Gözlem süresi
Mortalite araştırmaları için, ilgilendiğimiz döneme ait uygun bir ölüm oranını hesaplayabilmek için her bireyin bölgede ne kadar süredir bulunduğunu bilmek istiyoruz. Bu, tüm anketlerde geçerli değildir, ancak özellikle ölüm anketleri için bu önemlidir, çünkü bunlar sık sık hareketli veya göç etmiş nüfuslarda kullanılabilir.
Bunu yapmak için önce, geri çağırma dönemi olarak da bilinen ilgilendiğimiz süreyi tanımlarız (yani, katılımcılardan soruları cevaplarken rapor vermelerinin istendiği süre). Daha sonra bu süreyi, uygun olmayan tarihleri kayıp olarak ayarlamak için kullanabiliriz, örneğin ölümler ilgili dönemin dışından bildirilirse.
## geri çağırma süresinin başlangıcını/sonunu ayarla
## veri setinden tarih değişkenleri olarak değiştirilebilir
## (örn. başlangıç tarihi & anket tarihi)
survey_data <- survey_data %>%
mutate(recall_start = as.Date("2018-01-01"),
recall_end = as.Date("2018-05-01")
)
# kurallara göre uygunsuz tarihleri NA olarak ayarla
## örneğin, başlangıçtan önce varışlar, bitişten sonra ayrılışlar
survey_data <- survey_data %>%
mutate(
arrived_date = if_else(arrived_date < recall_start,
as.Date(NA),
arrived_date),
birthday_date = if_else(birthday_date < recall_start,
as.Date(NA),
birthday_date),
left_date = if_else(left_date > recall_end,
as.Date(NA),
left_date),
death_date = if_else(death_date > recall_end,
as.Date(NA),
death_date)
)Daha sonra her birey için başlangıç ve bitiş tarihlerini tanımlamak için tarih değişkenlerimizi kullanabiliriz. Tarihlerin nedenlerini belirlemek için sitrep paketinden find_start_date() fonksiyonunu kullanabilir ve ardından bunu günler arasındaki farkı (kişi-zaman) hesaplamak için kullanabiliriz.
başlangıç tarihi: Geri çağırma döneminiz içindeki en erken uygun varış olayı Geri çağırma sürenizin başlangıcı (önceden tanımladığınız) veya varsa, geri çağırma başlangıcından sonraki bir tarih (örneğin varışlar veya doğumlar)
bitiş tarihi: Geri çağırma süreniz içindeki en erken uygun ayrılma olayı Geri çağırma sürenizin sonu ya da varsa, geri çağırma süresinin bitiminden önceki bir tarih (örn. ayrılışlar, ölümler)
## başlangıç ve bitiş tarihleri/nedenleri için yeni değişkenler oluştur
survey_data <- survey_data %>%
## ankete girilen en erken tarihi seç
## doğumlardan, hane girişlerinden ve kamp varışlarından
find_start_date("birthday_date",
"arrived_date",
period_start = "recall_start",
period_end = "recall_end",
datecol = "startdate",
datereason = "startcause"
) %>%
## ankete girilen en erken tarihi seç
## kamptan ayrılma, ölüm ve çalışmanın bitiminden
find_end_date("left_date",
"death_date",
period_start = "recall_start",
period_end = "recall_end",
datecol = "enddate",
datereason = "endcause"
)
## başlangıçta/sonda olanları etiketle (doğumlar/ölümler hariç)
survey_data <- survey_data %>%
mutate(
##geri çağırma süresinin başlangıcı olarak başlangıç tarihini gir (boş olanlar için)
startdate = if_else(is.na(startdate), recall_start, startdate),
## geri çağırma periyoduna eşitse, başlangıç nedenini başlangıçta gösterecek şekilde ayarla
## doğum tarihine eşit değilse
startcause = if_else(startdate == recall_start & startcause != "birthday_date",
"Present at start", startcause),
## geri çağırma süresinin bitimi için bitiş tarihini gir (boş olanlar için)
enddate = if_else(is.na(enddate), recall_end, enddate),
## son nedeni, geri çağırma sonuna eşitse, sonunda sunacak şekilde ayarla
## ölüm tarihine eşit olmadıkça
endcause = if_else(enddate == recall_end & endcause != "death_date",
"Present at end", endcause))
## Gözlem süresini gün olarak tanımla
survey_data <- survey_data %>%
mutate(obstime = as.numeric(enddate - startdate))26.5 Ağırlıklandırma
Anket ağırlıkları eklemeden önce hatalı gözlemleri bırakmanız önemlidir. Örneğin, negatif gözlem süresine sahip gözlemleriniz varsa, bunları kontrol etmeniz gerekecektir (bunu sitrep paketinden assert_positive_timespan() fonksiyonuyla yapabilirsiniz. Başka bir şey de boş satırlar bırakmak istiyorsanız (örneğin drop_na(uid) ile) veya kopyaları kaldırabilirsiniz (ayrıntılar için El Kitabının [Tekilleştirme] bölümüne bakın). İzinsiz olanların da çıkarılması gerekir.
Bu örnekte, bırakmak ve ayrı bir veri çerçevesinde saklamak istediğimiz durumları filtreliyoruz - bu şekilde anketten hariç tutulanları tanımlayabiliriz. Ardından, bu bırakılan durumları anket verilerimizden çıkarmak için dplyr paketinden anti_join() fonksiyonunu kullanırız.
TEHLİKE: Ağırlık değişkeninizde veya anket tasarımınızla ilgili herhangi bir değişkende (örneğin yaş, cinsiyet, tabaka veya küme değişkenleri) eksik değerler olamaz.
## düşürdüğünüz vakaları tanımlayabilmek için sakla (ör.rıza dışı
## veya yanlış köy/küme)
dropped <- survey_data %>%
filter(!consent | is.na(startdate) | is.na(enddate) | village_name == "other")
## kullanılmayan satırları anket veri setinden çıkarmak için bırakılan vakaları kullan
survey_data <- anti_join(survey_data, dropped, by = names(dropped))Yukarıda bahsedildiği gibi, üç farklı çalışma tasarımı (katmanlı, küme ve tabakalı küme) için ağırlıkların nasıl ekleneceğini gösteriyoruz. Bunlar, kaynak popülasyon ve/veya incelenen kümeler hakkında bilgi gerektirir. Bu örnek için tabakalı küme kodunu kullanacağız, ancak çalışma tasarımınız için en uygun olanı kullanın.
# tabakalı ------------------------------------------------------------------
# "surv_weight_strata" adında bir değişken oluştur
# her birey için ağırlıklar içerir - yaş grubuna, cinsiyete ve sağlık bölgesine göre
survey_data <- add_weights_strata(x = survey_data,
p = population,
surv_weight = "surv_weight_strata",
surv_weight_ID = "surv_weight_ID_strata",
age_group, sex, health_district)
## küme ---------------------------------------------------------------------
# hane başına görüşülen bireylerin kişi sayısını al
# hane (ebeveyn) indeks değişkeni sayılarına sahip bir değişken ekler
survey_data <- survey_data %>%
add_count(index, name = "interviewed")
## küme ağırlıkları oluştur
survey_data <- add_weights_cluster(x = survey_data,
cl = cluster_counts,
eligible = member_number,
interviewed = interviewed,
cluster_x = village_name,
cluster_cl = cluster,
household_x = index,
household_cl = households,
surv_weight = "surv_weight_cluster",
surv_weight_ID = "surv_weight_ID_cluster",
ignore_cluster = FALSE,
ignore_household = FALSE)
# tabakalı ve küme ---------------------------------------------------------
# küme ve tabalalar için bir anket ağırlığı oluştur
survey_data <- survey_data %>%
mutate(surv_weight_cluster_strata = surv_weight_strata * surv_weight_cluster)26.6 Anket tasarım nesneleri
Çalışma tasarımınıza göre anket nesnesi oluşturun. Ağırlık orantılarını vb. hesaplamak için veri çerçeveleri ile aynı şekilde kullanılır. Bundan önce gerekli tüm değişkenlerin oluşturulduğundan emin olun.
Dört seçenek vardır, kullanmadıklarınızı yorumlayarak kodun dışında bırakın:
- Basit rastgele
- Tabakalı
- Küme
- Tabakalı küme
Bu şablon için - anketleri iki ayrı katmanda (sağlık bölgeleri A ve B) gruplandırdığımızı farz edeceğiz. Bu nedenle, genel tahminler elde etmek için küme ve tabaka ağırlıklarının birleştirilmesine ihtiyacımız var.
Daha önce de belirtildiği gibi, bunu yapmak için iki paket mevcuttur. Klasik olan survey paketidir; ve daha sonra düzenli tidyverse dostu nesneler ve işlevler yapan srvyr adında bir sarmalayıcı paket vardır. Burada her ikisini de göstereceğiz, ancak bu bölümdeki kodun çoğunun srvyr tabanlı nesneleri kullanacağını unutmayın. Tek istisna, gtsummary paketinin yalnızca anket nesnelerini kabul etmesidir.
26.6.1 Survey paketi
survey paketi, R tabanı kodlamasını etkin bir şekilde kullanır ve bu nedenle tüneller (%>%) veya diğer dplyr sözdizimini kullanmak mümkün değildir. survey paketiyle, uygun kümeler, ağırlıklar ve tabakalarla bir anket nesnesi tanımlamak için svydesign() fonksiyonunu kullanırız.
NOT: Değişkenlerin önünde yaklaşık işareti (~) kullanmamız gerekir, bunun nedeni paketin formüllere dayalı değişkenler atamak için R tabanı sözdizimini kullanmasıdır.
# basit rastgele ---------------------------------------------------------------
base_survey_design_simple <- svydesign(ids = ~1, # küme kimliği yok demek için 1
weights = NULL, # Ağırlık eklenmedi
strata = NULL, # örnekleme basitti (tabaka yok)
data = survey_data # veri kümesini belirtmek zorunda
)
## tabakalı --------------------------------------------------------------------
base_survey_design_strata <- svydesign(ids = ~1, # küme kimliği yok demek için 1
weights = ~surv_weight_strata, # yukarıda oluşturulan ağırlık değişkeni
strata = ~health_district, # örnekleme bölgelere göre tabakalandırılmıştır
data = survey_data # veri kümesini belirtmek zorunda
)
# küme -------------------------------------------------------------------------
base_survey_design_cluster <- svydesign(ids = ~village_name, # küme kimlikleri
weights = ~surv_weight_cluster, # yukarıda oluşturulan ağırlık değişkeni
strata = NULL, # örnekleme basitti (tabaka yok)
data = survey_data # veri kümesini belirtmek zorunda
)
# tabakalı küme ----------------------------------------------------------------
base_survey_design <- svydesign(ids = ~village_name, # küme kimlikleri
weights = ~surv_weight_cluster_strata, # yukarıda oluşturulan ağırlık değişkeni
strata = ~health_district, # örnekleme bölgelere göre tabakalandırılmıştır
data = survey_data # veri kümesini belirtmek zorunda
)26.6.2 Srvyr paketi
srvyr paketiyle, yukarıdakiyle aynı argümanlara sahip olan ancak tünellere (%>%) izin veren as_survey_design() fonksiyonunu kullanabiliriz ve bu nedenle tilde (~) kullanmamız gerekmez.
## basit rastgele --------------------------------------------------------------
survey_design_simple <- survey_data %>%
as_survey_design(ids = 1, # küme kimliği yok demek için 1
weights = NULL, # Ağırlık eklenmedi
strata = NULL # örnekleme basitti (tabaka yok)
)
## tabakalı --------------------------------------------------------------------
survey_design_strata <- survey_data %>%
as_survey_design(ids = 1, # küme kimliği yok demek için 1
weights = surv_weight_strata, # yukarıda oluşturulan ağırlık değişkeni
strata = health_district # örnekleme bölgelere göre tabakalandırılmıştır
)
## küme ------------------------------------------------------------------------
survey_design_cluster <- survey_data %>%
as_survey_design(ids = village_name, # küme kimlikleri
weights = surv_weight_cluster, # yukarıda oluşturulan ağırlık değişkeni
strata = NULL # örnekleme basitti (tabaka yok)
)
## tabakalı küme ---------------------------------------------------------------
survey_design <- survey_data %>%
as_survey_design(ids = village_name, # küme kimlikleri
weights = surv_weight_cluster_strata, # yukarıda oluşturulan ağırlık değişkeni
strata = health_district # örnekleme bölgelere göre tabakalandırılmıştır
)26.7 Tanımlayıcı analiz
Temel tanımlayıcı analiz ve görselleştirme, el kitabının diğer bölümlerinde kapsamlı bir şekilde ele alınmıştır, bu nedenle burada üzerinde durmayacağız. Ayrıntılar için tanımlayıcı tablolar, istatistiksel testler, sunum tabloları, ggplot temelleri ve R markdown raporları ile ilgili bölümlere bakabilirsiniz.
Bu bölümde, örnekleminizdeki yanlılığı nasıl araştırıp bunu görselleştireceğimize odaklanacağız. Ayrıca alüvyon/sankey diyagramlarını kullanarak bir anket ortamında nüfus akışını görselleştirmeye bakacağız.
Genel olarak, aşağıdaki tanımlayıcı analizleri dahil etmeyi düşünmelisiniz:
- Dahil edilen kümelerin, hanelerin ve bireylerin nihai sayısı
- Dışlanan kişi sayısı ve dışlanma nedenleri
- Küme başına medyan (aralık) hane ve hane başına birey sayısı
26.7.1 Örnekleme yanlılığı
Örnekleminiz ve kaynak popülasyon arasındaki her yaş grubundaki orantıları karşılaştırın. Bu, potansiyel örnekleme yanlılığını vurgulayabilmek için önemlidir. Benzer şekilde, cinsiyete göre dağılımlara bakarak da bunu tekrarlayabilirsiniz.
Bu p değerlerinin yalnızca gösterge niteliğinde olduğunu ve kaynak popülasyona kıyasla çalışma örneğinizdeki dağılımların açıklayıcı bir tartışmasının (veya aşağıdaki yaş piramitleriyle görselleştirmenin) binom testinin kendisinden daha önemli olduğunu unutmayın. Bunun nedeni, örnek boyutunun artmasının, verilerinizi ağırlıklandırdıktan sonra alakasız olabilecek farklılıklara yol açmamasıdır.
## çalışma popülasyonunun sayıları ve orantıları
ag <- survey_data %>%
group_by(age_group) %>%
drop_na(age_group) %>%
tally() %>%
mutate(proportion = n / sum(n),
n_total = sum(n))
## kaynak popülasyonun sayıları ve orantıları
propcount <- population %>%
group_by(age_group) %>%
tally(population) %>%
mutate(proportion = n / sum(n))
## iki tablonun sütunlarını birbirine bağla, yaşa göre grupla ve bir
## n/toplamın popülasyondan önemli ölçüde farklı olup olmadığını görmek için binom testi orantısı.
## buradaki son ek, iki veri kümesinin her birindeki sütunların sonuna metne ekler
left_join(ag, propcount, by = "age_group", suffix = c("", "_pop")) %>%
group_by(age_group) %>%
## broom::tidy(binom.test()) binom testinden bir veri çerçevesi yapar ve
## p.value, parametre, conf.low, conf.high, method ve değişkenlerini ekleyecektir.
## Burada sadece p.value kullanacağız. diğerlerini dahil edebilirsiniz
## güven aralıklarını bildirmek istiyorsanız sütunlar
mutate(binom = list(broom::tidy(binom.test(n, n_total, proportion_pop)))) %>%
unnest(cols = c(binom)) %>% # important for expanding the binom.test data frame
mutate(proportion_pop = proportion_pop * 100) %>%
## Yanlış pozitifleri düzeltmek için p-değerlerini ayarla
## (çünkü birden fazla yaş grubunu test ediyor). Bu sadece yapacak
## birçok yaş kategoriniz varsa bir fark verir
mutate(p.value = p.adjust(p.value, method = "holm")) %>%
## Yalnızca 0,001'in üzerindeki p değerlerini göster (<0,001 olarak rapor edilenler)
mutate(p.value = ifelse(p.value < 0.001,
"<0.001",
as.character(round(p.value, 3)))) %>%
## sütunları uygun şekilde yeniden adlandır
select(
"Age group" = age_group,
"Study population (n)" = n,
"Study population (%)" = proportion,
"Source population (n)" = n_pop,
"Source population (%)" = proportion_pop,
"P-value" = p.value
)# A tibble: 5 × 6
# Groups: Age group [5]
`Age group` `Study population (n)` `Study population (%)`
<chr> <int> <dbl>
1 0-2 12 0.0256
2 3-14 42 0.0896
3 15-29 64 0.136
4 30-44 52 0.111
5 45+ 299 0.638
# ℹ 3 more variables: `Source population (n)` <dbl>,
# `Source population (%)` <dbl>, `P-value` <chr>26.7.2 Demografik piramitler
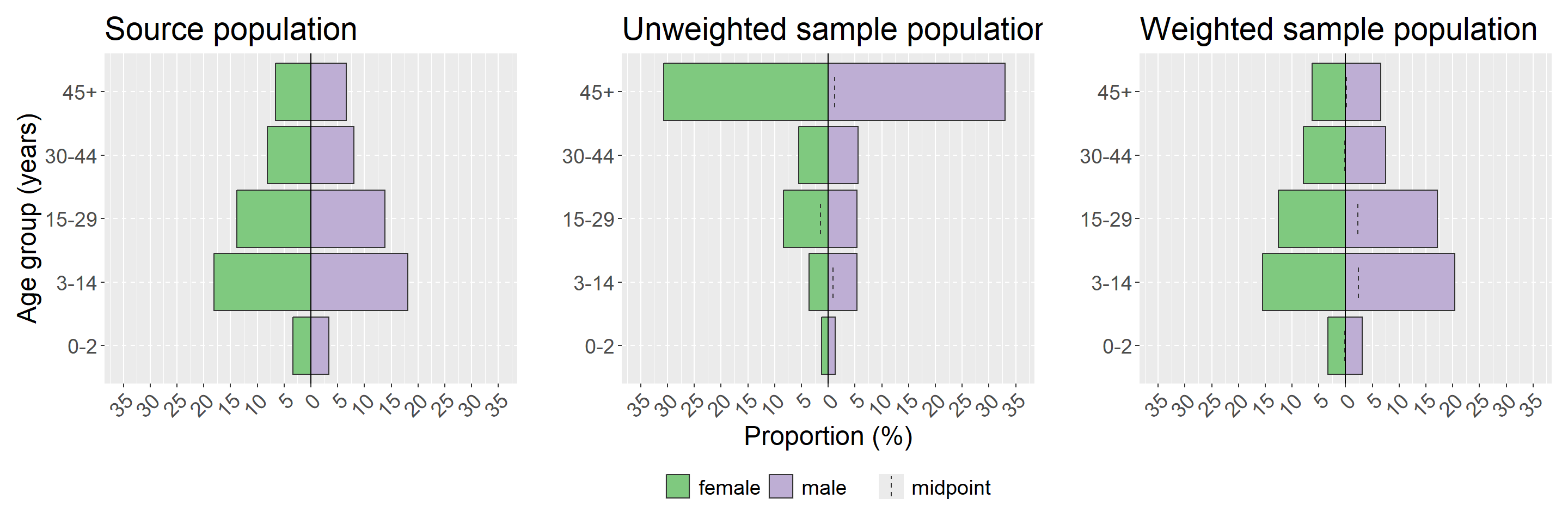
Demografik (veya yaş-cinsiyet) piramitler, anket popülasyonunuzdaki dağılımı görselleştirmenin kolay bir yoludur. Anket tabaklarına göre yaş ve cinsiyet için tanımlayıcı tabloları oluşturmayı da düşünmeye değer. Yukarıda oluşturulan anket tasarım nesnemizi kullanarak ağırlıklı orantılara izin verdiği için apyramid paketini kullanmayı göstereceğiz. Demografik piramitler oluşturmaya yönelik diğer seçenekler, el kitabının bu bölümünde kapsamlı bir şekilde ele alınmıştır. Ayrıca, orantıları olan bir grafik üretmek için birkaç satır kodlama kaydeden, age_pyramid() adlı sitrep paketinden bir sarmalayıcı işlevi kullanacağız.
Yukarıda örnekleme yanlılığı bölümünde görülen resmi binom farklılık testinde olduğu gibi, burada örneklenen popülasyonumuzun kaynak popülasyondan önemli ölçüde farklı olup olmadığını ve ağırlıklandırmanın bu farkı düzeltip düzeltmediğini görselleştirmekle ilgileniyoruz. Bunu yapmak için ggplot görselleştirmelerimizi yan yana göstermek için patchwork paketini kullanacağız; ayrıntılar için el kitabının ggplot ipuçları bölümündeki grafikleri birleştirme bölümüne bakın. Kaynak popülasyonumuzu, ağırlıksız anket popülasyonumuzu ve ağırlıklı anket popülasyonumuzu görselleştireceğiz. Anketinizin her katmanına göre görselleştirmeyi de düşünebilirsiniz - buradaki örneğimizde bu, stack_by = "health_district" argümanını kullanmak olacaktır (ayrıntılar için ?age_pyramid komutuna bknz.).
NOT: x ve y eksenleri piramitlerde çevrilir.
## x ekseni sınırlarını ve etiketlerini tanımlayın -----------------------------
## (bu sayıları grafiğinizin değerleri olacak şekilde güncelle)
max_prop <- 35 # göstermek istediğiniz en yüksek orantıyı seç
step <- 5 # etiketler arasında istediğiniz boşluğu seç
## bu kısım, vektörü yukarıdaki sayıları kullanarak eksen sonları ile tanımlar.
breaks <- c(
seq(max_prop/100 * -1, 0 - step/100, step/100),
0,
seq(0 + step / 100, max_prop/100, step/100)
)
## bu kısım vektörü yukarıdaki sayıları kullanarak eksen limitleri ile tanımlar.
limits <- c(max_prop/100 * -1, max_prop/100)
## bu kısım, vektörü, eksen etiketleriyle birlikte yukarıdaki sayıları kullanarak tanımlar.
labels <- c(
seq(max_prop, step, -step),
0,
seq(step, max_prop, step)
)
## ayrı ayrı grafikler oluştur ------------------------------------------------
## kaynak popülasyonu grafiklendir
## not: bunun genel nüfus için daraltılması gerekiyor (yani sağlık bölgelerinin kaldırılması)
source_population <- population %>%
## yaş ve cinsiyetin faktörler olduğundan emin ol
mutate(age_group = factor(age_group,
levels = c("0-2",
"3-14",
"15-29",
"30-44",
"45+")),
sex = factor(sex)) %>%
group_by(age_group, sex) %>%
## birlikte her sağlık bölgesi için sayıları ekle
summarise(population = sum(population)) %>%
## genel orantıyı hesaplayabilmek için gruplandırmayı kaldır
ungroup() %>%
mutate(proportion = population / sum(population)) %>%
## piramid grafiği
age_pyramid(
age_group = age_group,
split_by = sex,
count = proportion,
proportional = TRUE) +
## sadece y ekseni etiketini göster (aksi takdirde her üç çizimde de tekrarlanır)
labs(title = "Source population",
y = "",
x = "Age group (years)") +
## x eksenini tüm grafikler için aynı yap
scale_y_continuous(breaks = breaks,
limits = limits,
labels = labels)
## ağırlıksız örnek popülasyonunu grafiklendir
sample_population <- age_pyramid(survey_data,
age_group = "age_group",
split_by = "sex",
proportion = TRUE) +
## sadece x ekseni etiketini göster (aksi takdirde her üç grafikte de tekrarlanır)
labs(title = "Unweighted sample population",
y = "Proportion (%)",
x = "") +
## x eksenini tüm grafikler için aynı yap
scale_y_continuous(breaks = breaks,
limits = limits,
labels = labels)
## ağırlıklı örnek popülasyonunu grafiklendir
weighted_population <- survey_design %>%
## değişkenlerin faktör olduğundan emin ol
mutate(age_group = factor(age_group),
sex = factor(sex)) %>%
age_pyramid(
age_group = "age_group",
split_by = "sex",
proportion = TRUE) +
## sadece x ekseni etiketini göster (aksi takdirde her üç grafikte de tekrarlanır)
labs(title = "Weighted sample population",
y = "",
x = "") +
## x eksenini tüm grafikler için aynı yap
scale_y_continuous(breaks = breaks,
limits = limits,
labels = labels)
## üç grafiğin tümünü birleştir ------------------------------------------------
## + kullanarak üç grafiği yan yana birleştir
source_population + sample_population + weighted_population +
## sadece bir legand göster ve temayı tanımla
## temayı plot_layout() ile birleştirmek için & kullanımına dikkat et
plot_layout(guides = "collect") &
theme(legend.position = "bottom", # açıklamayı aşağıya taşı
legend.title = element_blank(), # başlığı kaldır
text = element_text(size = 18), # metin boyutunu değiştir
axis.text.x = element_text(angle = 45, hjust = 1, vjust = 1) # x ekseni metnini çevir
)
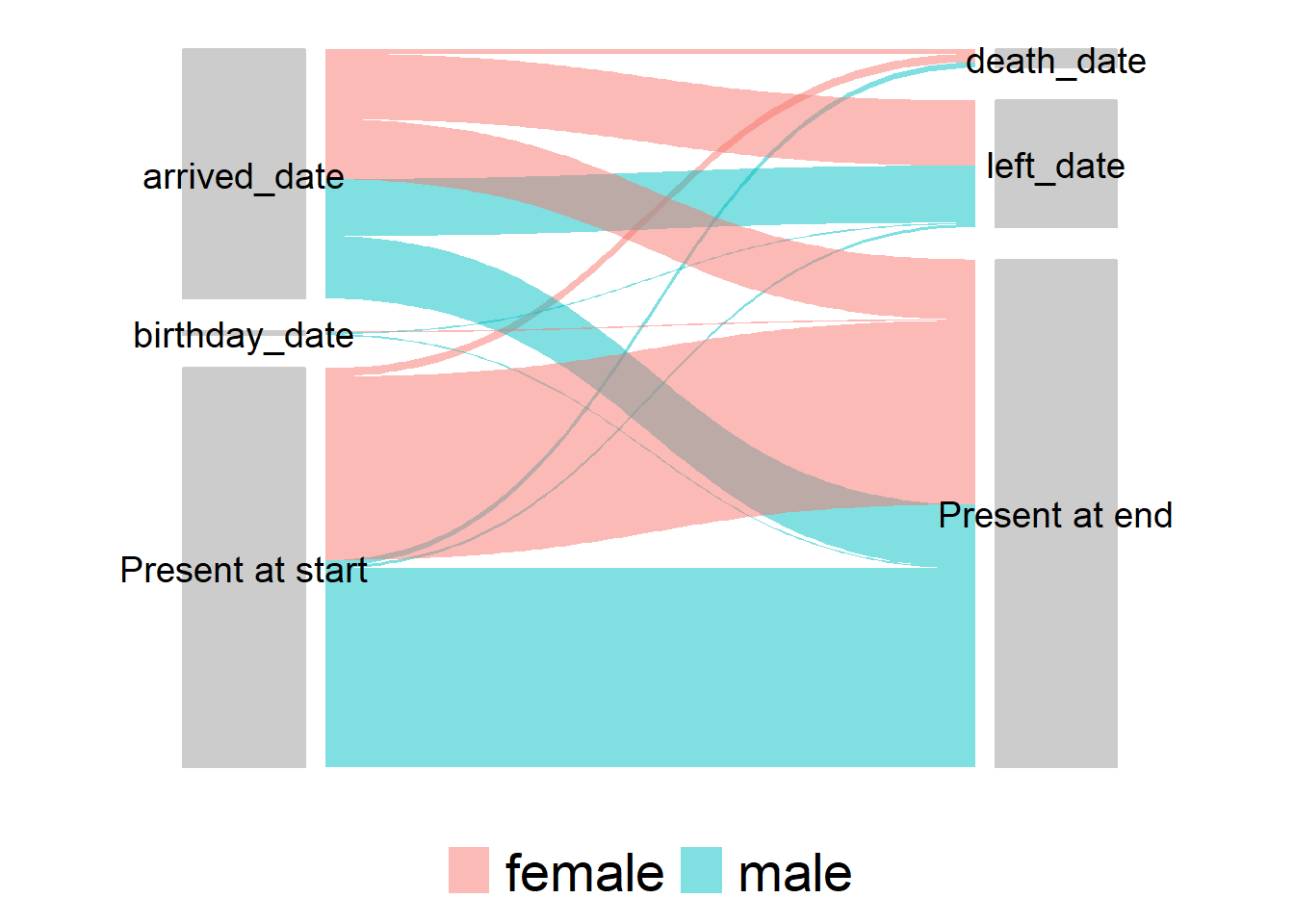
26.7.3 Alluvial/sankey diagramı
Bireyler için başlangıç noktalarını ve sonuçları görselleştirmek, genel bir bakış elde etmek için çok yardımcı olabilir. Mobil popülasyonlar için oldukça açık bir uygulama var, ancak kohortlar veya bireyler için durumlarda geçişlerin olduğu diğer durumlar gibi çok sayıda başka uygulama var. Bu diyagramların alüvyon, sankey ve paralel kümeler dahil olmak üzere birkaç farklı adı vardır - ayrıntılar el kitabının Diyagramlar ve çizelgeler bölümündedir.
## verileri özetle
flow_table <- survey_data %>%
count(startcause, endcause, sex) %>% # sayımları al
gather_set_data(x = c("startcause", "endcause")) # grafiklendirme için formatı değiştir
## veri kümesini çiz
## x ekseninde başlangıç ve bitiş nedenleri
## gather_set_data, her olası kombinasyon için bir kimlik oluşturur
## y ile bölme, olası başlangıç/bitiş kombinasyonlarını verir
## n'nin sayı olarak verdiği değer (orantı olarak da değiştirilebilir)
ggplot(flow_table, aes(x, id = id, split = y, value = n)) +
## cinsiyete göre renk çizgileri
geom_parallel_sets(aes(fill = sex), alpha = 0.5, axis.width = 0.2) +
## etiket kutularını gri doldur
geom_parallel_sets_axes(axis.width = 0.15, fill = "grey80", color = "grey80") +
## metin rengini ve açısını değiştir (ayarlanması gerekiyor)
geom_parallel_sets_labels(color = "black", angle = 0, size = 5) +
## ayarlanmış y ve x eksenleri (muhtemelen daha fazla dikey alana ihtiyaç duyar)
scale_x_discrete(name = NULL, expand = c(0, 0.2)) +
## eksen etiketlerini kaldır
theme(
title = element_text(size = 26),
text = element_text(size = 26),
axis.line = element_blank(),
axis.ticks = element_blank(),
axis.text.y = element_blank(),
panel.background = element_blank(),
legend.position = "bottom", # açıklamayı aşağıya taşı
legend.title = element_blank(), # başlığı kaldır
)
26.8 Ağırlıklı orantılar
Bu bölüm, ilişkili güven aralıkları ve tasarım etkisi ile birlikte ağırlıklı sayımlar ve oranlar için tabloların nasıl üretileceğini detaylandıracaktır. Aşağıdaki paketlerdeki işlevleri kullanan dört farklı seçenek vardır: survey, srvyr, sitrep ve gtsummary. Standart bir epidemiyoloji stili tablosu oluşturmak üzere minimum kodlama için, srvyr kodunun sarmalayıcısı olan sitrep fonksiyonunu öneriyoruz; Ancak bunun henüz CRAN’da olmadığını ve gelecekte değişebileceğini unutmayın. Aksi takdirde, survey kodu muhtemelen en istikrarlı ve uzun vadeli paket olacaktır, oysa srvyr paketi en iyi şekilde derli toplu iş akışlarına uymaktadır. gtsummary fonksiyonları çok fazla potansiyele sahip olsa da, bu kitap yazıldığı sırada deneysel ve eksiktirler.
26.8.1 Survey paketi
Ağırlıklı orantılar ve beraberindeki %95 güven aralıklarını elde etmek için survey paketinden svyciprop() fonksiyonunu kullanabiliriz. Uygun bir tasarım efekti, svyprop() fonksiyonu yerine svymean() kullanılarak da çıkarılabilir. svyprop() fonksiyonunun yalnızca 0 ile 1 (veya DOĞRU/YANLIŞ) arasındaki değişkenleri kabul ediyor gibi göründüğünü, dolayısıyla kategorik değişkenlerin çalışmayacağını belirtmekte fayda var.
NOT: survey paketinden gelen foksiyonlar ayrıca srvyr tasarım nesnelerini de kabul etmektedir, ancak burada anket survey nesnesini yalnızca tutarlılık için kullandık.
## ağırlıklı sayılar üretme
svytable(~died, base_survey_design)died
FALSE TRUE
1406244.43 76213.01 ## ağırlıklı orantılar üretme
svyciprop(~died, base_survey_design, na.rm = T) 2.5% 97.5%
died 0.0514 0.0208 0.12## tasarım efektini al
svymean(~died, base_survey_design, na.rm = T, deff = T) %>%
deff()diedFALSE diedTRUE
3.755508 3.755508 Yukarıda gösterilen survey fonksiyonları, aşağıda kendimizi tanımladığımız, svy_prop adlı bir fonksiyonda birleştirebiliriz; ve daha sonra bu fonksiyonu purrr paketindeki map() ile birlikte birkaç değişken üzerinde yineleme yapmak ve bir tablo oluşturmak için kullanabiliriz. purrr hakkında ayrıntılar için el kitabı yineleme bölümüne bakabilirsiniz.
# Ağırlıklı sayıları, oranlatıları, CI ve tasarım etkisini hesaplamak için fonksiyonu tanımla
# x tırnak içindeki değişkendir
# tasarım, sizin anket tasarım nesnenizdir
svy_prop <- function(design, x) {
## ilgilenilen değişkeni bir formüle koy
form <- as.formula(paste0( "~" , x))
## svytable'dan yalnızca DOĞRU sayım sütununu sakla
weighted_counts <- svytable(form, design)[[2]]
## orantıları hesapla (yüzdeleri almak için 100 ile çarpın)
weighted_props <- svyciprop(form, design, na.rm = TRUE) * 100
## güven aralıklarını çıkarın ve yüzdeleri elde etmek için çarp
weighted_confint <- confint(weighted_props) * 100
## tasarım etkisini hesaplamak için svymean kullanın ve yalnızca DOĞRU sütununu koru
design_eff <- deff(svymean(form, design, na.rm = TRUE, deff = TRUE))[[TRUE]]
## tek bir veri çerçevesinde birleştir
full_table <- cbind(
"Variable" = x,
"Count" = weighted_counts,
"Proportion" = weighted_props,
weighted_confint,
"Design effect" = design_eff
)
## tabloyu veri çerçevesi olarak döndür
full_table <- data.frame(full_table,
## remove the variable names from rows (is a separate column now)
row.names = NULL)
## sayısalları tekrar sayısal olarak değiştir
full_table[ , 2:6] <- as.numeric(full_table[, 2:6])
## veri çerçevesini döndür
full_table
}
## bir tablo oluşturmak için birkaç değişken üzerinde yineleme yap
purrr::map(
## ilgilenilen değişkenleri tanımla
c("left", "died", "arrived"),
## durum fonksiyonu kullanımı ve bu fonksiyon için argümanlar (tasarım)
svy_prop, design = base_survey_design) %>%
## listeyi tek bir veri çerçevesine daralt
bind_rows() %>%
## yuvarla
mutate(across(where(is.numeric), round, digits = 1)) Variable Count Proportion X2.5. X97.5. Design.effect
1 left 701199.1 47.3 39.2 55.5 2.4
2 died 76213.0 5.1 2.1 12.1 3.8
3 arrived 761799.0 51.4 40.9 61.7 3.926.8.2 Srvyr paketi
srvyr ile bir tablo oluşturmak için dplyr sözdizimini kullanabiliriz. survey_mean() fonksiyonunun kullanıldığını ve orantı argümanının belirtildiğini ve ayrıca tasarım etkisini hesaplamak için aynı fonksiyonu kullanıldığını unutmayın. Bunun nedeni, srvyr paketinin yukarıdaki bölümde kullanılan svyciprop() ve svymean() survey paketi fonksiyonun her ikisinin de etrafını sarmasıdır.
NOT: Kategorik değişkenlerden orantıları srvyr paketini kullanarak da almak pek mümkün görünmüyor, buna ihtiyacınız varsa sitrep paketini kullanmanız gerekir. Detaylar için aşağıdaki bölüme göz atın.
## srvyr tasarım nesnesini kullan
survey_design %>%
summarise(
## ağırlıklı sayıları üret
counts = survey_total(died),
## ağırlıklı orantıları ve güven aralıkları üret
## yüzde almak için 100 ile çarp
props = survey_mean(died,
proportion = TRUE,
vartype = "ci") * 100,
## tasarım efekti üret
deff = survey_mean(died, deff = TRUE)) %>%
## sadece ilgi alanlarını tut
## (standart hataları bırakın ve orantı hesaplamasını tekrarla)
select(counts, props, props_low, props_upp, deff_deff)# A tibble: 1 × 5
counts props props_low props_upp deff_deff
<dbl> <dbl> <dbl> <dbl> <dbl>
1 76213. 5.14 2.08 12.1 3.76Burada da purrr paketini kullanarak birden çok değişken üzerinde yineleme yapacak bir fonksiyon yazabiliriz. purrr hakkında ayrıntılar için el kitabı yineleme bölümüne bakabilirsiniz.
# Ağırlıklı sayıları, orantıları, CI ve tasarım etkisini hesaplamak için işlevi tanımla
# tasarım, sizin anket tasarım nesnenizdir
# x tırnak içindeki değişkendir
srvyr_prop <- function(design, x) {
summarise(
## anket tasarım nesnesini kullan
design,
## ağırlıklı sayıları üret
counts = survey_total(.data[[x]]),
## ağırlıklı orantıları ve güven aralıkları üret
## yüzde almak için 100 ile çarp
props = survey_mean(.data[[x]],
proportion = TRUE,
vartype = "ci") * 100,
## tasarım efekti üret
deff = survey_mean(.data[[x]], deff = TRUE)) %>%
## değişken adını ekle
mutate(variable = x) %>%
## sadece ilgi alanlarını tut
## (standart hataları bırak ve orantı hesaplamasını tekrarla)
select(variable, counts, props, props_low, props_upp, deff_deff)
}
## bir tablo oluşturmak için birkaç değişken üzerinde yineleme yap
purrr::map(
## ilgilenilen değişkenleri tanımla
c("left", "died", "arrived"),
## durum fonksiyonu kullanımı ve bu fonksiyon için argümanlar (tasarım)
~srvyr_prop(.x, design = survey_design)) %>%
## listeyi tek bir veri çerçevesine daralt
bind_rows()# A tibble: 3 × 6
variable counts props props_low props_upp deff_deff
<chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 left 701199. 47.3 39.2 55.5 2.38
2 died 76213. 5.14 2.08 12.1 3.76
3 arrived 761799. 51.4 40.9 61.7 3.9326.8.3 Sitrep paketi
sitrep paketinin tab_survey() fonksiyonu, minimum kodlama ile ağırlıklı tablolar oluşturmanıza olanak tanıyan srvyr paketi için bir sarmalayıcıdır. Ayrıca kategorik değişkenler için ağırlıklı orantıları hesaplamanıza olanak tanır.
## anket tasarım nesnesini kullan
survey_design %>%
## ilgilenilen değişkenlerin isimlerini alıntı yapılmadan ilet
tab_survey(arrived, left, died, education_level,
deff = TRUE, # tasarım etkisini hesapla
pretty = TRUE # oranı ve %95 CI'yi birleştir
)Warning: removing 257 missing value(s) from `education_level`# A tibble: 9 × 5
variable value n deff ci
<chr> <chr> <dbl> <dbl> <chr>
1 arrived TRUE 761799. 3.93 51.4% (40.9-61.7)
2 arrived FALSE 720658. 3.93 48.6% (38.3-59.1)
3 left TRUE 701199. 2.38 47.3% (39.2-55.5)
4 left FALSE 781258. 2.38 52.7% (44.5-60.8)
5 died TRUE 76213. 3.76 5.1% (2.1-12.1)
6 died FALSE 1406244. 3.76 94.9% (87.9-97.9)
7 education_level higher 171644. 4.70 42.4% (26.9-59.7)
8 education_level primary 102609. 2.37 25.4% (16.2-37.3)
9 education_level secondary 130201. 6.68 32.2% (16.5-53.3)26.8.4 Gtsummary paketi
gtsummary paketinde henüz güven aralıklarını veya tasarım efektini eklemek için yerleşik fonksiyonlar yok gibi görünüyor. Burada, güven aralıkları eklemek için bir fonksiyonun nasıl tanımlanacağını ve ardından tbl_svysummary() fonksiyonunu kullanılarak oluşturulan bir gtsummary tablosuna güven aralıklarının nasıl ekleneceğini gösteriyoruz.
confidence_intervals <- function(data, variable, by, ...) {
## güven aralıklarını çıkarın ve yüzdeleri elde etmek için çarp
props <- svyciprop(as.formula(paste0( "~" , variable)),
data, na.rm = TRUE)
## güven aralıklarını çıkar
as.numeric(confint(props) * 100) %>% ## sayısal yap ve yüzde için çarp
round(., digits = 1) %>% ## bir haneye yuvarla
c(.) %>% ## sayıları matristen çıkar
paste0(., collapse = "-") ## tek karakterle birleştir
}
## anket paketi tasarım nesnesini kullan
tbl_svysummary(base_survey_design,
include = c(arrived, left, died), ## dahil etmek istediğiniz değişkenleri tanımla
statistic = list(everything() ~ c("{n} ({p}%)"))) %>% ## ilgi istatistiklerini tanımla
add_n() %>% ## add the weighted total
add_stat(fns = everything() ~ confidence_intervals) %>% ## güven aralığını ekle
## sütun başlıklarını değiştir
modify_header(
list(
n ~ "**Weighted total (N)**",
stat_0 ~ "**Weighted Count**",
add_stat_1 ~ "**95%CI**"
)
)Characteristic |
Weighted total (N) |
Weighted Count 1 |
95%CI |
|---|---|---|---|
| arrived | 1,482,457 | 761,799 (51%) | 40.9-61.7 |
| left | 1,482,457 | 701,199 (47%) | 39.2-55.5 |
| died | 1,482,457 | 76,213 (5.1%) | 2.1-12.1 |
|
1
n (%) |
|||
26.9 Ağırlıklı hızlar
Benzer şekilde ağırlıklı hızlar için (ölüm hızları gibi) survey veya srvyr paketini kullanabilirsiniz. Birkaç değişken üzerinde yineleme yapmak için benzer şekilde (yukarıdakilere benzer) fonksiyonlar yazabilirsiniz. Ayrıca gtsummary için yukarıdaki gibi bir fonksiyon oluşturabilirsiniz, ancak şu anda dahili bir fonksiyonelliği bulunmamaktadır.
26.9.1 Survey paketi
ratio <- svyratio(~died,
denominator = ~obstime,
design = base_survey_design)
ci <- confint(ratio)
cbind(
ratio$ratio * 10000,
ci * 10000
) obstime 2.5 % 97.5 %
died 5.981922 1.194294 10.7695526.9.2 Srvyr paketi
survey_design %>%
## gözlem süresini hesaba katmak için kullanılan anket hızı
summarise(
mortality = survey_ratio(
as.numeric(died) * 10000,
obstime,
vartype = "ci")
)# A tibble: 1 × 3
mortality mortality_low mortality_upp
<dbl> <dbl> <dbl>
1 5.98 0.349 11.6