pacman::p_load(
rio, # importing data
here, # relative file pathways
janitor, # data cleaning and tables
lubridate, # working with dates
epikit, # age_categories() function
apyramid, # age pyramids
tidyverse, # data manipulation and visualization
RColorBrewer, # color palettes
formattable, # fancy tables
kableExtra # table formatting
)25 Truy vết tiếp xúc
Chương này trình bày phân tích mô tả về dữ liệu truy vết tiếp xúc, bổ sung một số cân nhắc chính và cách tiếp cận độc đáo đối với kiểu dữ liệu này.
Chương này đề cập nhiều đến năng lực quản lý dữ liệu và trực quan hóa mà đã được đề cập đến trong các chương khác (ví dụ: làm sạch dữ liệu, xoay trục dữ liệu, data table, phân tích chuỗi thời gian), nhưng chúng tôi sẽ nêu bật các ví dụ cụ thể về truy vết tiếp xúc, năng lực hữu ích cho việc đưa ra quyết định hành động. Ví dụ, nó bao gồm việc trực quan hóa dữ liệu truy vết tiếp xúc theo thời gian hoặc trên các khu vực địa lý, hay tạo bảng Chỉ Số Đánh Giá Hiệu Quả Công Việc (Key Performance Indicator - KPI) rõ ràng hỗ trợ cho người giám sát truy vết tiếp xúc.
Với mục đích minh họa, chúng tôi sẽ sử dụng dữ liệu truy vết tiếp xúc mẫu từ nền tảng Go.Data. Các nguyên tắc được đề cập ở đây sẽ áp dụng cho cả dữ liệu truy vết tiếp xúc từ những nền tảng khác - bạn có thể chỉ cần trải qua các bước xử lý trước dữ liệu khác nhau tùy thuộc vào cấu trúc dữ liệu của bạn.
Bạn có thể đọc thêm về dự án Go.Data trên Trang tài liệu Github và Cộng đồng thực hành.
25.1 Chuẩn bị
Gọi package
Đoạn code này hiển thị những package cần cho các phân tích. Trong sổ tay này, chúng tôi nhấn mạnh đến hàm p_load() từ pacman, hàm sẽ cài đặt package nếu cần và gọi nó để sử dụng. Bạn cũng có thể gọi các package đã cài đặt với hàm library() từ base R. Xem chương R cơ bản để có thêm thông tin về các R package.
Nhập dữ liệu
Chúng ta sẽ nhập bộ dữ liệu mẫu về những người tiếp xúc và thông tin “theo dõi” của họ. Những dữ liệu này đã được truy xuất và không được lồng ghép với Go.Data API, đồng thời được lưu trữ dưới dạng tệp “.rds”.
Bạn có thể tải xuống tất cả dữ liệu mẫu cho sổ tay này từ chương Tải sách và dữ liệu.
Nếu bạn muốn tải xuống dữ liệu truy vết tiếp xúc mẫu cụ thể cho chương này, hãy sử dụng ba liên kết tải xuống dưới đây:
Bấm để tải xuống dữ liệu điều tra ca mắc (file .rds)
Bấm để tải xuống dữ liệu khai báo tiếp xúc (file .rds)
Bấm để tải xuống dữ liệu theo dõi tiếp xúc (file .rds)
Ở dạng gốc các các tệp có thể tải xuống được, dữ liệu thể hiện dữ liệu gốc được cung cấp bởi Go.Data API (tìm hiểu thêm về APIs ở đây). Đối với mục đích ví dụ ở đây, chúng ta sẽ làm sạch dữ liệu để giúp bạn đọc chương này dễ dàng hơn. Nếu bạn đang sử dụng một phiên bản Go.Data, bạn có thể xem hướng dẫn đầy đủ về cách truy xuất dữ liệu của mình tại đây.
Dưới đây, các bộ dữ liệu được nhập bằng hàm import() từ package rio. Xem chương về Nhập xuất dữ liệu để biết những cách nhập dữ liệu khác nhau. Chúng tôi sử dụng hàm here() để xác định đường dẫn tệp - bạn nên cung cấp đường dẫn tệp cụ thể cho máy tính của mình. Sau đó, chúng tôi sử dụng hàm select() để chỉ chọn một số cột nhất định của dữ liệu, nhằm đơn giản hóa cho mục đích diễn giải.
Dữ liệu ca mắc
Dữ liệu này là một bảng các ca mắc và thông tin về họ.
cases <- import(here("data", "godata", "cases_clean.rds")) %>%
select(case_id, firstName, lastName, gender, age, age_class,
occupation, classification, was_contact, hospitalization_typeid)Dưới đây là nrow(cases) các trường hợp :
Dữ liệu tiếp xúc
Những dữ liệu này là một bảng gồm tất cả những người tiếp xúc và thông tin về họ. Một lần nữa, hãy cung cấp đường dẫn tệp của riêng bạn. Sau khi nhập, chúng tôi thực hiện một số bước làm sạch dữ liệu sơ bộ bao gồm:
- Thiết lập age_class là biến kiểu factor và đảo ngược thứ tự giá trị của biến sao cho những người trẻ hơn nằm ở trên đầu
- Chỉ chọn một số cột nhất định, và đặt lại tên cho một trong số chúng
- Giả định gán các hàng missing ở cột admin_2_name thành “Djembe”, để cải thiện sự rõ ràng ở một số ví dụ trực quan hóa.
contacts <- import(here("data", "godata", "contacts_clean.rds")) %>%
mutate(age_class = forcats::fct_rev(age_class)) %>%
select(contact_id, contact_status, firstName, lastName, gender, age,
age_class, occupation, date_of_reporting, date_of_data_entry,
date_of_last_exposure = date_of_last_contact,
date_of_followup_start, date_of_followup_end, risk_level, was_case, admin_2_name) %>%
mutate(admin_2_name = replace_na(admin_2_name, "Djembe"))Đây là nrow(contacts) các hàng của bộ dữ liệu contacts:
Dữ liệu theo dõi
Những dữ liệu này là bản ghi của các tương tác được “theo dõi” với những người tiếp xúc. Mỗi người tiếp xúc được cho là có một cuộc gặp gỡ mỗi ngày với ca mắc trong vòng 14 ngày sau khi phơi nhiễm.
Chúng ta nhập dữ liệu và thực hiện một số bước làm sạch. Chúng ta chọn một số cột nhất định và cũng chuyển đổi tất cả các giá trị thành chữ thường ở một cột định dạng ký tự.
followups <- rio::import(here::here("data", "godata", "followups_clean.rds")) %>%
select(contact_id, followup_status, followup_number,
date_of_followup, admin_2_name, admin_1_name) %>%
mutate(followup_status = str_to_lower(followup_status))Đây là 50 hàng đầu tiên của nrow(followups) - hàng của bộ dữ liệu followups (mỗi hàng là một người tiếp xúc được theo dõi, với trạng thái kết quả trong cột followup_status):
Dữ liệu mối quan hệ
Ở đây chúng ta nhập dữ liệu cho thấy mối quan hệ giữa các ca mắc và người tiếp xúc. Chúng ta chọn một số cột nhất định để hiển thị.
relationships <- rio::import(here::here("data", "godata", "relationships_clean.rds")) %>%
select(source_visualid, source_gender, source_age, date_of_last_contact,
date_of_data_entry, target_visualid, target_gender,
target_age, exposure_type)Dưới đây là 50 hàng đầu tiên của bộ dữ liệu relationships, bộ dữ liệu này ghi lại tất cả mối quan hệ giữa các ca mắc và những người tiếp xúc.
25.2 Phân tích mô tả
Bạn có thể sử dụng các kỹ thuật được đề cập đến trong những chương khác của sổ tay này để tiến hành các phân tích mô tả về những ca mắc, người tiếp xúc và mối quan hệ của họ. Dưới đây là một số ví dụ.
Nhân khẩu học
Như được trình bày trong chương Tháp dân số và thang đo Likert, bạn có thể trực quan hóa phân bố theo độ tuổi và giới tính (ở đây chúng tôi sử dụng package apyramid).
Tuổi và Giới tính của người tiếp xúc
Kim tự tháp dưới đây so sánh sự phân bố độ tuổi của những người tiếp xúc theo giới tính. Lưu ý rằng những người tiếp xúc bị missing tuổi được đưa vào thanh riêng của họ ở trên cùng. Bạn có thể thay đổi hiển thị mặc định này, nhưng sau đó hãy xem xét liệt kê số bị missing trong chú thích.
apyramid::age_pyramid(
data = contacts, # use contacts dataset
age_group = "age_class", # categorical age column
split_by = "gender") + # gender for halfs of pyramid
labs(
fill = "Gender", # title of legend
title = "Age/Sex Pyramid of COVID-19 contacts")+ # title of the plot
theme_minimal() # simple background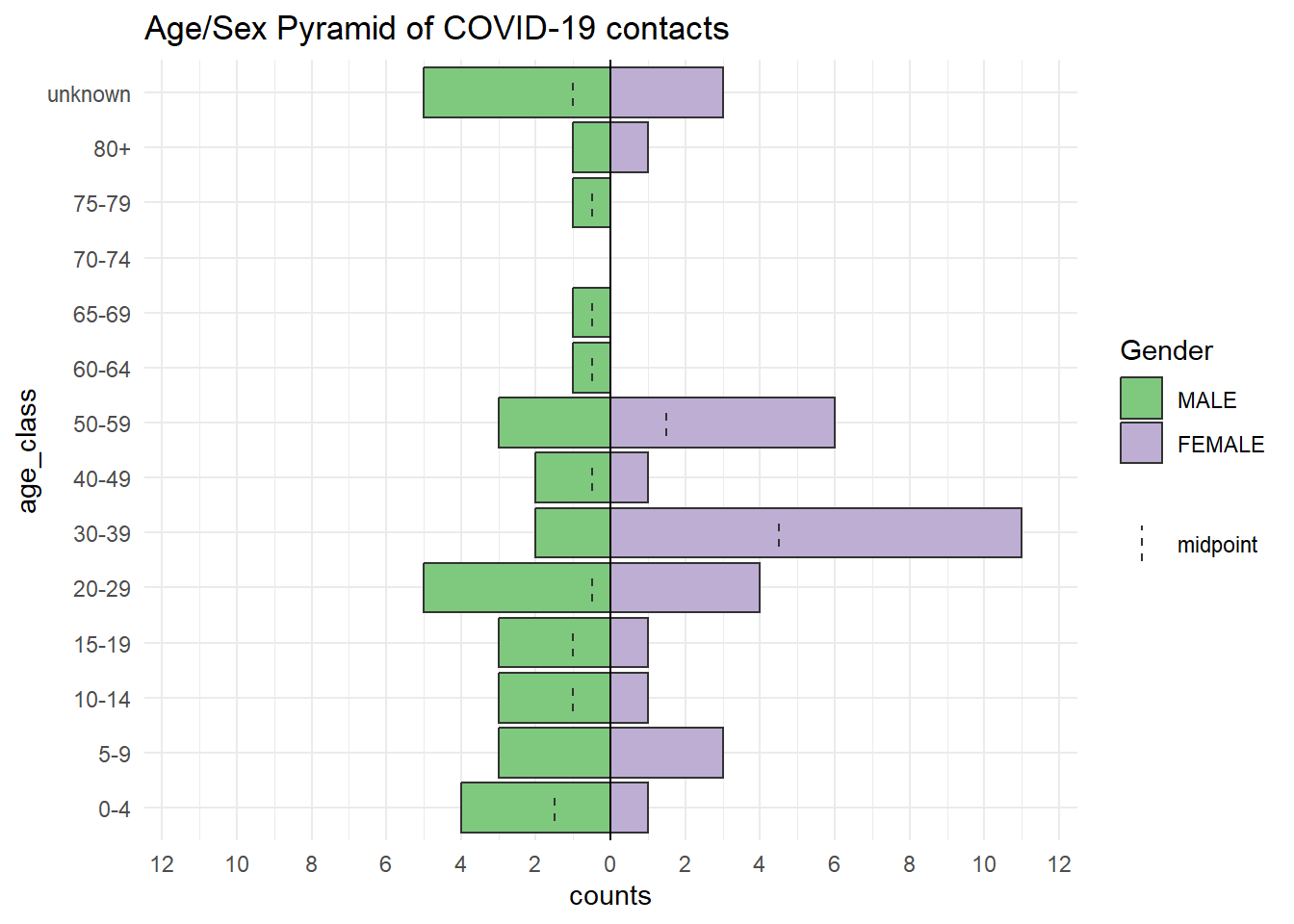
Với cấu trúc dữ liệu Go.Data, bộ dữ liệu relationships bao gồm độ tuổi của cả các ca mắc và những người tiếp xúc, vì vậy bạn có thể sử dụng bộ dữ liệu đó và tạo tháp tuổi cho thấy sự khác biệt giữa hai nhóm người này. Data frame relationships sẽ được biến đổi để chuyển các cột tuổi ở dạng số số thành các nhóm định danh (xem chương Làm sạch số liệu và các hàm quan trọng). Chúng ta cũng sẽ xoay trục dataframe sang định dạng dọc nhằm vẽ biểu đồ dễ dàng hơn với ggplot2 (xem chương Xoay trục dữ liệu).
relation_age <- relationships %>%
select(source_age, target_age) %>%
transmute( # transmute is like mutate() but removes all other columns not mentioned
source_age_class = epikit::age_categories(source_age, breakers = seq(0, 80, 5)),
target_age_class = epikit::age_categories(target_age, breakers = seq(0, 80, 5)),
) %>%
pivot_longer(cols = contains("class"), names_to = "category", values_to = "age_class") # pivot longer
relation_age# A tibble: 200 × 2
category age_class
<chr> <fct>
1 source_age_class 80+
2 target_age_class 15-19
3 source_age_class <NA>
4 target_age_class 50-54
5 source_age_class <NA>
6 target_age_class 20-24
7 source_age_class 30-34
8 target_age_class 45-49
9 source_age_class 40-44
10 target_age_class 30-34
# ℹ 190 more rowsBây giờ chúng ta có thể vẽ biểu đồ bộ dữ liệu đã chuyển đổi này với hàm age_pyramid() như trước đây, nhưng thay thế gender bởi category (người tiếp xúc, hoặc ca mắc).
apyramid::age_pyramid(
data = relation_age, # use modified relationship dataset
age_group = "age_class", # categorical age column
split_by = "category") + # by cases and contacts
scale_fill_manual(
values = c("orange", "purple"), # to specify colors AND labels
labels = c("Case", "Contact"))+
labs(
fill = "Legend", # title of legend
title = "Age/Sex Pyramid of COVID-19 contacts and cases")+ # title of the plot
theme_minimal() # simple background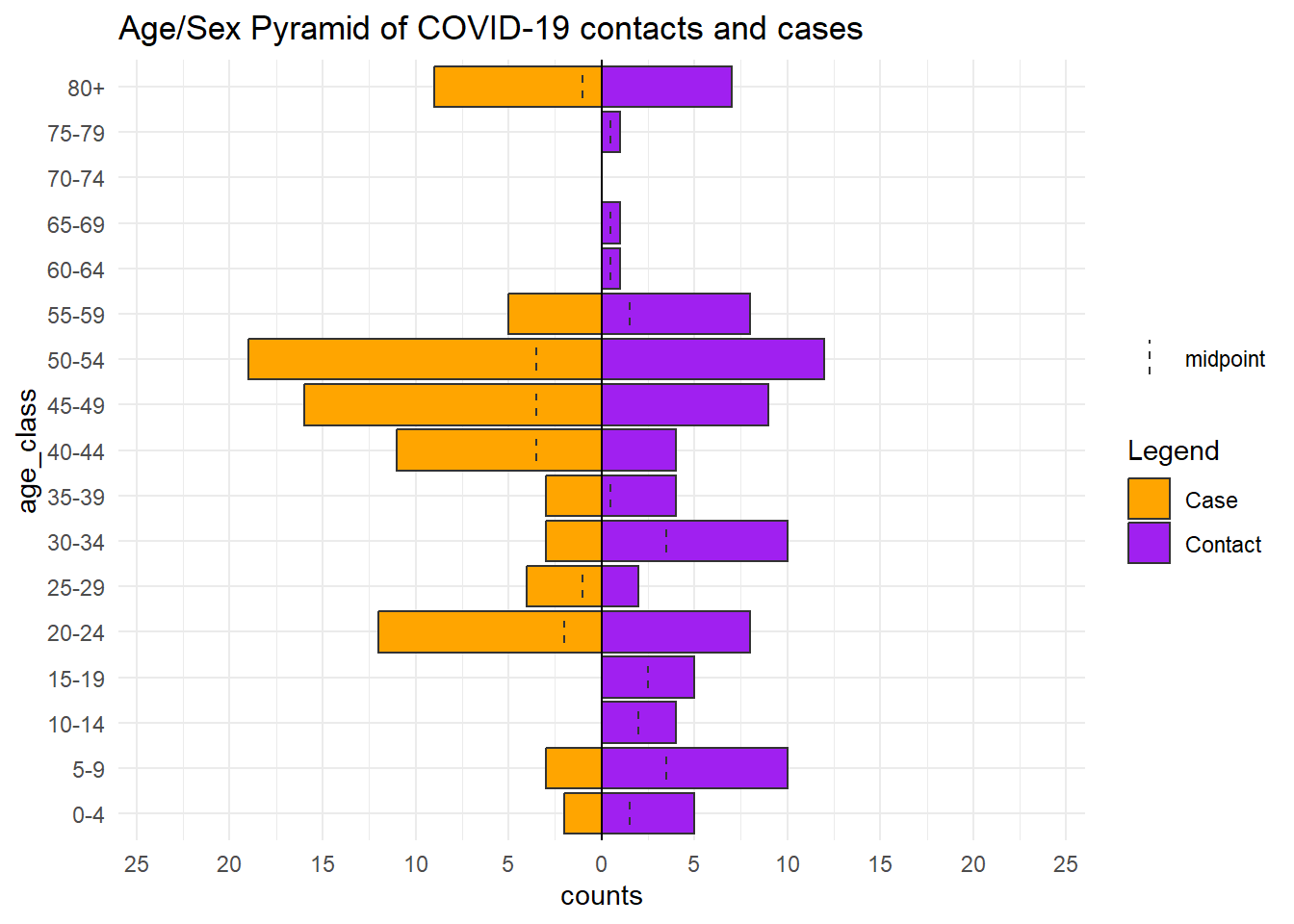
Chúng ta cũng có thể xem xét các đặc điểm khác như cơ cấu nghề nghiệp (ví dụ: ở dạng biểu đồ tròn).
# Clean dataset and get counts by occupation
occ_plot_data <- cases %>%
mutate(occupation = forcats::fct_explicit_na(occupation), # make NA missing values a category
occupation = forcats::fct_infreq(occupation)) %>% # order factor levels in order of frequency
count(occupation) # get counts by occupation
# Make pie chart
ggplot(data = occ_plot_data, mapping = aes(x = "", y = n, fill = occupation))+
geom_bar(width = 1, stat = "identity") +
coord_polar("y", start = 0) +
labs(
fill = "Occupation",
title = "Known occupations of COVID-19 cases")+
theme_minimal() +
theme(axis.line = element_blank(),
axis.title = element_blank(),
axis.text = element_blank())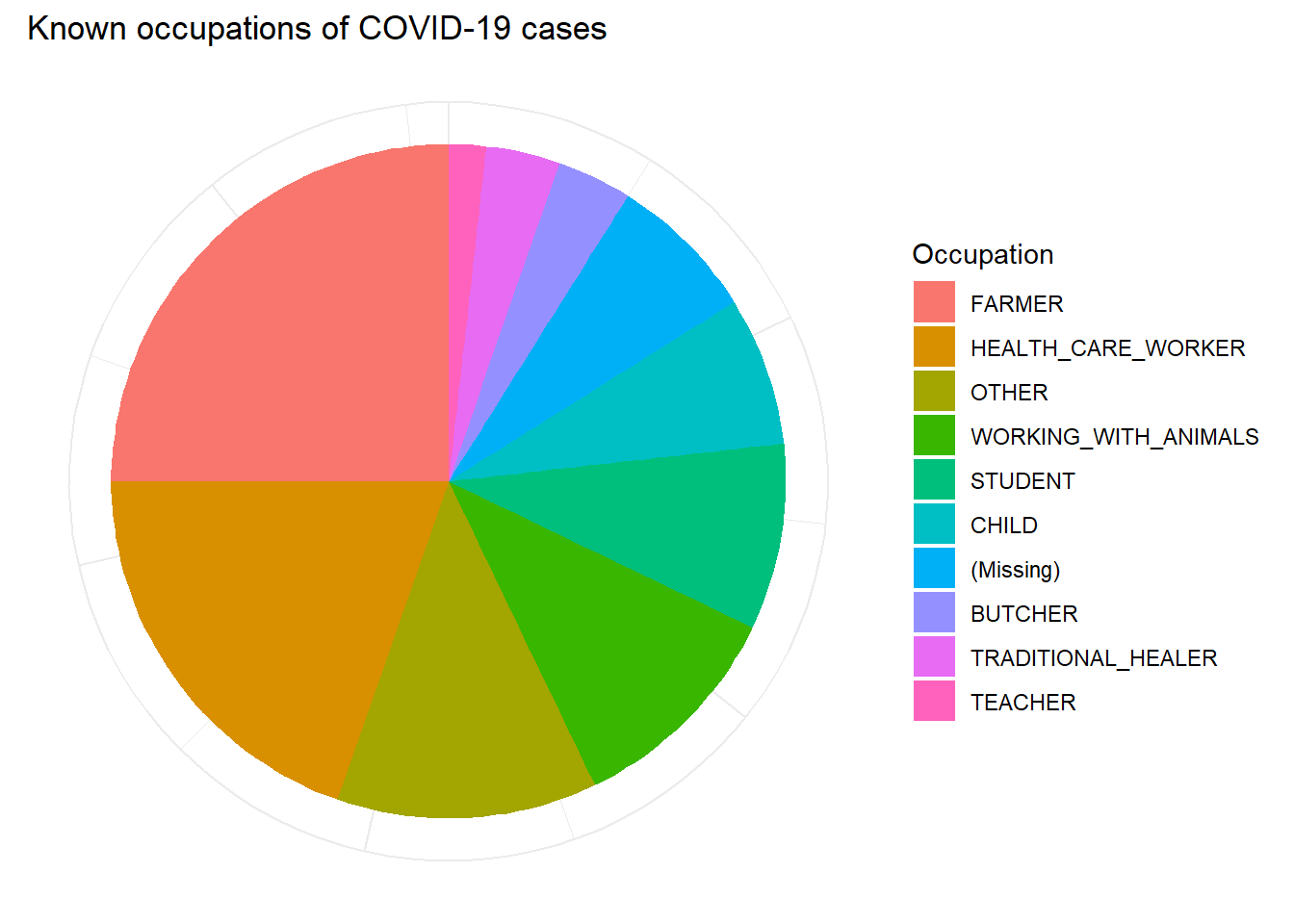
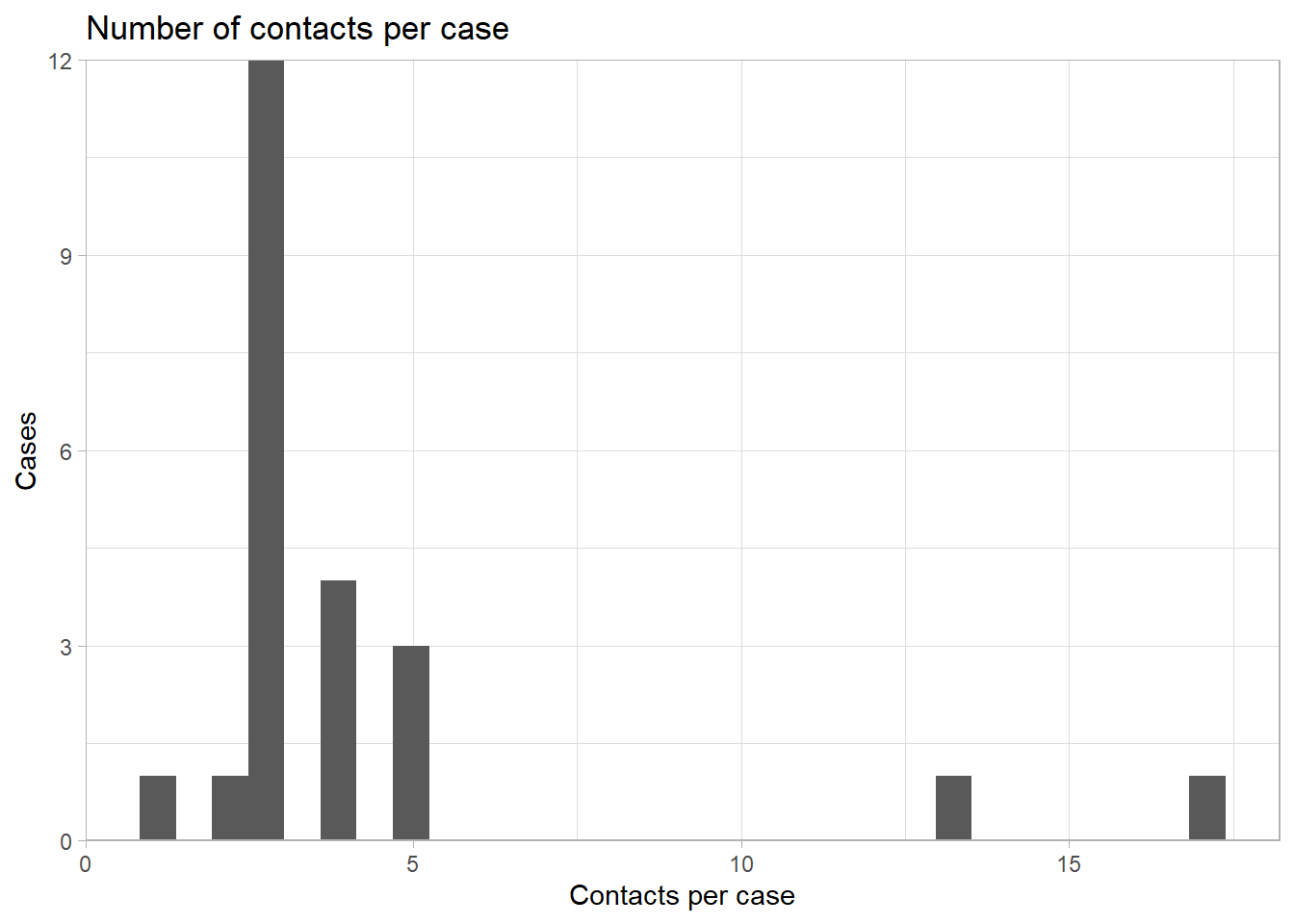
Số người tiếp xúc trên mỗi ca mắc
Số người tiếp xúc trên mỗi ca mắc có thể là một thước đo quan trọng để đánh giá chất lượng của việc điều tra số người tiếp xúc và mức độ tuân thủ của người dân với việc ứng phó sức khỏe cộng đồng.
Tùy thuộc vào cấu trúc dữ liệu của bạn, điều này có thể được đánh giá thông qua bộ dữ liệu chứa thông tin tất cả các ca mắc và những người tiếp xúc. Trong bộ dữ liệu Go.Data, liên kết giữa các ca mắc (“nguồn”) và những người tiếp xúc (“mục tiêu”) được lưu trữ trong bộ dữ liệu relationships.
Trong bộ dữ liệu này, mỗi hàng là một người tiếp xúc và trong đó có liệt kê ca mắc nguồn. Không có người tiếp xúc nào có mối quan hệ với nhiều ca mắc, nhưng nếu điều này tồn tại, bạn có thể cần tính toán những người đó trước khi vẽ biểu đồ (và khám phá chúng nữa!).
Chúng ta bắt đầu bằng cách đếm số hàng (người tiếp xúc) trên mỗi ca mắc nguồn. Kết quả này được lưu dưới dạng một data frame.
contacts_per_case <- relationships %>%
count(source_visualid)
contacts_per_case source_visualid n
1 CASE-2020-0001 13
2 CASE-2020-0002 5
3 CASE-2020-0003 2
4 CASE-2020-0004 4
5 CASE-2020-0005 5
6 CASE-2020-0006 3
7 CASE-2020-0008 3
8 CASE-2020-0009 3
9 CASE-2020-0010 3
10 CASE-2020-0012 3
11 CASE-2020-0013 5
12 CASE-2020-0014 3
13 CASE-2020-0016 3
14 CASE-2020-0018 4
15 CASE-2020-0022 3
16 CASE-2020-0023 4
17 CASE-2020-0030 3
18 CASE-2020-0031 3
19 CASE-2020-0034 4
20 CASE-2020-0036 1
21 CASE-2020-0037 3
22 CASE-2020-0045 3
23 <NA> 17Chúng ta sử dụng hàm geom_histogram() để vẽ các dữ liệu này dưới dạng biểu đồ histogram.
ggplot(data = contacts_per_case)+ # begin with count data frame created above
geom_histogram(mapping = aes(x = n))+ # print histogram of number of contacts per case
scale_y_continuous(expand = c(0,0))+ # remove excess space below 0 on y-axis
theme_light()+ # simplify background
labs(
title = "Number of contacts per case",
y = "Cases",
x = "Contacts per case"
)
25.3 Theo dõi người tiếp xúc
Dữ liệu truy vết tiếp xúc thường chứa dữ liệu “theo dõi”, dữ liệu này ghi lại kết quả kiểm tra triệu chứng hàng ngày của những người trong diện cách ly. Phân tích dữ liệu này có thể xác định chiến lược ứng phó, xác định những người tiếp xúc có nguy cơ mất theo dõi hoặc có nguy cơ phát triển bệnh.
Làm sạch dữ liệu
Những dữ liệu này có thể tồn tại ở nhiều định dạng khác nhau. Chúng có thể tồn tại dưới dạng trang tính Excel định dạng “ngang” với một hàng cho mỗi người tiếp xúc và một cột cho mỗi “ngày” theo dõi. Xem chương Xoay trục dữ liệu để hiểu về mô tả dữ liệu “dọc” và “ngang”, và cả cách xoay trục dữ liệu sang định dạng ngang hoặc dọc.
Trong ví dụ Go.Data của chúng tôi, những dữ liệu này được lưu trữ trong data frame followups, data frame này có định dạng “dọc” với một hàng cho mỗi tương tác theo dõi. 50 hàng đầu tiên như sau:
CẨN TRỌNG: Cẩn thận với các bản trùng lặp khi xử lý dữ liệu theo dõi; vì có thể có một vài lần theo dõi sai sót trong cùng một ngày cho một người tiếp xúc nhất định. Nó dường như có vẻ là một lỗi nhưng lại phản ánh đúng thực tế - ví dụ: người theo dõi trường hợp tiếp xúc có thể gửi biểu mẫu theo dõi từ sớm trong ngày dù họ chưa liên hệ được với người tiếp xúc và gửi biểu mẫu thứ hai khi họ đã liên hệ được sau đó. Việc này sẽ phụ thuộc vào quy trình thực hiện hoạt động đối với cách bạn muốn xử lý các bản trùng lặp - chỉ cần đảm bảo ghi lại cách tiếp cận của bạn một cách rõ ràng.
Hãy xem chúng ta có bao nhiêu trường hợp hàng “trùng lặp”:
followups %>%
count(contact_id, date_of_followup) %>% # get unique contact_days
filter(n > 1) # view records where count is more than 1 contact_id date_of_followup n
1 <NA> 2020-09-03 2
2 <NA> 2020-09-04 2
3 <NA> 2020-09-05 2Trong dữ liệu ví dụ của chúng ta, các bản ghi duy nhất áp dụng điều này là những bản ghi missing ID! Chúng ta có thể loại bỏ chúng. Tuy nhiên, với mục đích diễn giải, chúng ta sẽ trình bày các bước nhằm loại bỏ trùng lặp để mỗi người tiếp xúc chỉ có một lần theo dõi truy vết mỗi ngày. Xem chương Loại bỏ trùng lặp để biết thêm chi tiết. Chúng ta sẽ giả định rằng bản ghi cuộc gọi truy vết mới nhất là bản ghi chính xác. Chúng ta cũng tận dụng cơ hội để làm sạch cột followup_number (“ngày” theo dõi sẽ nằm trong khoảng 1 - 14).
followups_clean <- followups %>%
# De-duplicate
group_by(contact_id, date_of_followup) %>% # group rows per contact-day
arrange(contact_id, desc(date_of_followup)) %>% # arrange rows, per contact-day, by date of follow-up (most recent at top)
slice_head() %>% # keep only the first row per unique contact id
ungroup() %>%
# Other cleaning
mutate(followup_number = replace(followup_number, followup_number > 14, NA)) %>% # clean erroneous data
drop_na(contact_id) # remove rows with missing contact_idĐối với mỗi cuộc gọi truy vết tiếp theo, chúng ta có một trạng thái theo dõi (chẳng hạn như cuộc gọi truy vết có xảy ra hay không và nếu có, người tiếp xúc có triệu chứng hay không). Để xem tất cả các giá trị, chúng ta có thể chạy nhanh lệnh tabyl() (từ janitor) hoặc table() (từ base R) (xem chương Bảng mô tả) bằng followup_status để xem tần suất của từng kết quả.
Trong bộ dữ liệu này, “seen_not_ok” có nghĩa là “được thấy có triệu chứng” và “seen_ok” có nghĩa là “được thấy không có triệu chứng”.
followups_clean %>%
tabyl(followup_status) followup_status n percent
missed 10 0.02325581
not_attempted 5 0.01162791
not_performed 319 0.74186047
seen_not_ok 6 0.01395349
seen_ok 90 0.20930233Vẽ biểu đồ theo thời gian
Vì dữ liệu ngày là liên tục, chúng ta sẽ sử dụng biểu đồ histogram để vẽ chúng với biến date_of_followup được gán cho trục x. Chúng ta có thể vẽ được biểu đồ histogram “xếp chồng” bằng cách chỉ định đối số fill = trong aes(), đối số mà chúng ta gán cho cột followup_status. Do đó, bạn có thể thiết lập chú thích bằng cách sử dụng đối số fill = của labs().
Chúng ta có thể thấy rằng những người tiếp xúc được xác định theo từng đợt (có lẽ là tương ứng với các đợt dịch) và việc hoàn thành theo dõi dường như không cải thiện trong suốt đợt dịch.
ggplot(data = followups_clean)+
geom_histogram(mapping = aes(x = date_of_followup, fill = followup_status)) +
scale_fill_discrete(drop = FALSE)+ # show all factor levels (followup_status) in the legend, even those not used
theme_classic() +
labs(
x = "",
y = "Number of contacts",
title = "Daily Contact Followup Status",
fill = "Followup Status",
subtitle = str_glue("Data as of {max(followups$date_of_followup, na.rm=T)}")) # dynamic subtitle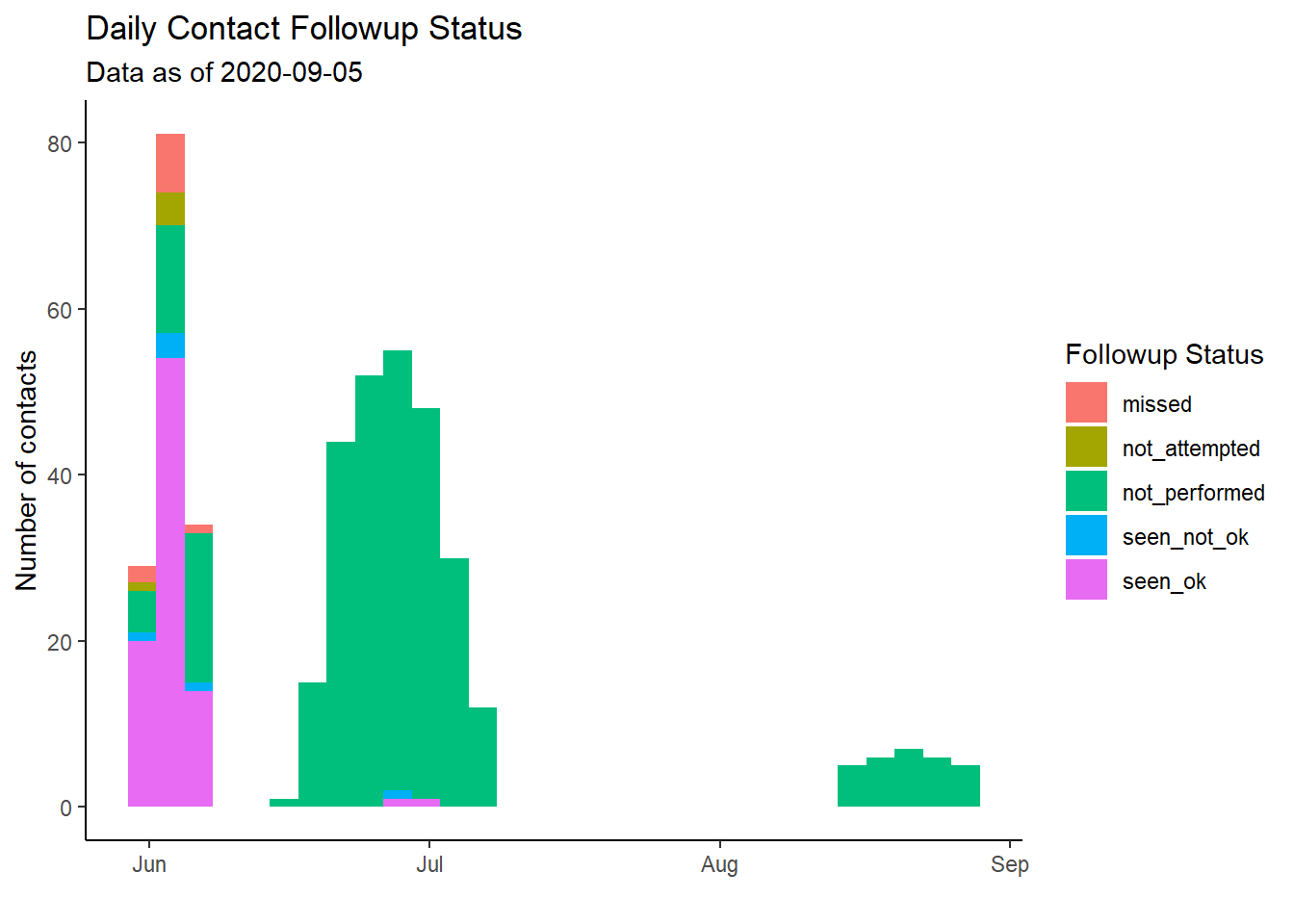
CẨN TRỌNG: Nếu bạn đang chuẩn bị nhiều biểu đồ (ví dụ: cho nhiều khu vực pháp lý), bạn sẽ muốn các chú thích xuất hiện giống hệt nhau ngay cả với các mức độ hoàn thiện dữ liệu hoặc thành phần dữ liệu khác nhau. Có thể có những biểu đồ mà không phải tất cả các trạng thái theo dõi đều có trong dữ liệu, nhưng bạn vẫn muốn các danh mục đó xuất hiện trong chú thích. Trong ggplots (như trên), bạn có thể chỉ định đối số drop = FALSE của hàm scale_fill_discrete(). Trong bảng, hãy sử dụng tabyl() để hiển thị số lượng cho tất cả các thực bậc của factor hoặc nếu sử dụng count() từ dplyr, hãy thêm đối số .drop = FALSE để bao gồm số lượng của tất cả các thứ bậc factors.
Theo dõi cá nhân hàng ngày
Nếu sự bùng phát dịch của bạn đủ nhỏ, bạn có thể muốn xem xét từng người tiếp xúc và xem trạng thái của họ trong suốt quá trình theo dõi. May mắn rằng, bộ dữ liệu followups này đã chứa sẵn một cột với “số” ngày theo dõi (1-14). Nếu cột này không tồn tại trong dữ liệu của bạn, bạn có thể tạo ra nó bằng cách tính toán sự khác biệt giữa ngày truy vết và ngày dự định bắt đầu theo dõi người tiếp xúc.
Một cơ chế trực quan hóa thuận tiện (nếu số lượng ca mắc không quá lớn) có thể là một biểu đồ nhiệt, được tạo bằng geom_tile(). Xem thêm chi tiết trong chương Biểu đồ nhiệt.
ggplot(data = followups_clean)+
geom_tile(mapping = aes(x = followup_number, y = contact_id, fill = followup_status),
color = "grey")+ # grey gridlines
scale_fill_manual( values = c("yellow", "grey", "orange", "darkred", "darkgreen"))+
theme_minimal()+
scale_x_continuous(breaks = seq(from = 1, to = 14, by = 1))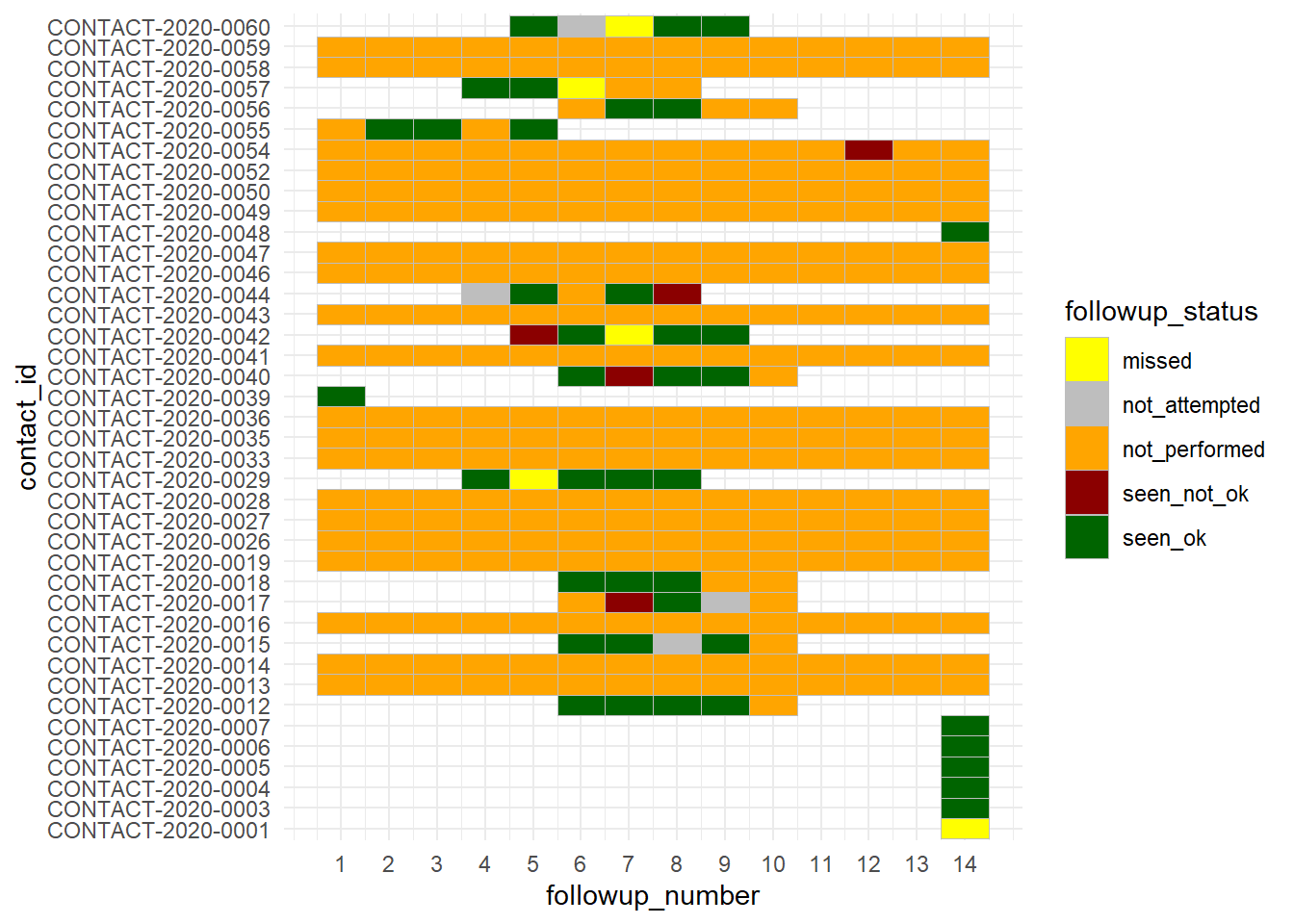
Phân tích theo nhóm
Có lẽ những dữ liệu theo dõi này đang được kiểm tra hàng ngày hoặc hàng tuần để đưa ra quyết định hành động. Bạn có thể muốn những phân tách có ý nghĩa hơn theo khu vực địa lý hoặc theo nhóm truy vết tiếp xúc. Chúng ta có thể làm điều này bằng cách điều chỉnh các cột được cung cấp tới hàm group_by().
plot_by_region <- followups_clean %>% # begin with follow-up dataset
count(admin_1_name, admin_2_name, followup_status) %>% # get counts by unique region-status (creates column 'n' with counts)
# begin ggplot()
ggplot( # begin ggplot
mapping = aes(x = reorder(admin_2_name, n), # reorder admin factor levels by the numeric values in column 'n'
y = n, # heights of bar from column 'n'
fill = followup_status, # color stacked bars by their status
label = n))+ # to pass to geom_label()
geom_col()+ # stacked bars, mapping inherited from above
geom_text( # add text, mapping inherited from above
size = 3,
position = position_stack(vjust = 0.5),
color = "white",
check_overlap = TRUE,
fontface = "bold")+
coord_flip()+
labs(
x = "",
y = "Number of contacts",
title = "Contact Followup Status, by Region",
fill = "Followup Status",
subtitle = str_glue("Data as of {max(followups_clean$date_of_followup, na.rm=T)}")) +
theme_classic()+ # Simplify background
facet_wrap(~admin_1_name, strip.position = "right", scales = "free_y", ncol = 1) # introduce facets
plot_by_region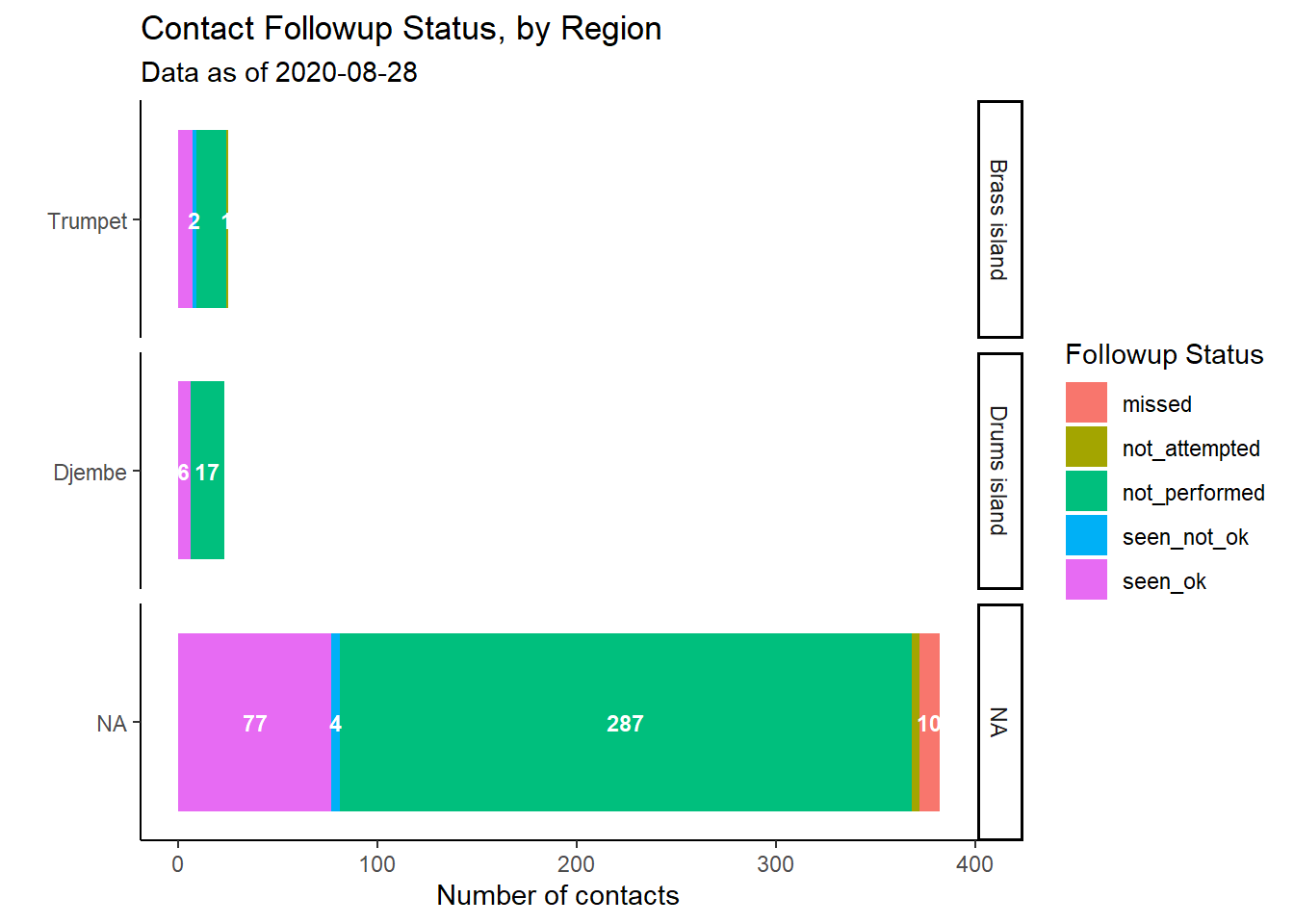
25.4 Bảng KPI
Có một số Chỉ Số Đánh Giá Hiệu Quả Công Việc (KPI) khác nhau có thể được tính toán và theo dõi ở các mức độ phân tách khác nhau và trong những khoảng thời gian khác nhau để theo dõi hiệu suất thực hiện truy vết tiếp xúc. Khi bạn đã tính toán xong và có định dạng bảng cơ bản; khá dễ dàng để hoán đổi các KPI khác nhau.
Có nhiều nguồn KPI truy vết tiếp xúc, chẳng hạn như nguồn này từ ResolveToSaveLives.org. Phần lớn công việc sẽ là xem xét cấu trúc dữ liệu và suy nghĩ về tất cả các tiêu chí bao gồm/loại trừ. Chúng tôi đưa ra một vài ví dụ dưới đây; sử dụng cấu trúc siêu dữ liệu Go.Data:
| Danh mục | Chỉ số | Tử số Go.Data | Mẫu số Go.Data |
|---|---|---|---|
| Chỉ Số Quy Trình - Tốc Độ Truy Vết Tiếp Xúc | % các trường hợp được phỏng vấn và cách ly trong vòng 24 giờ kể từ khi báo cáo ca mắc | ĐẾM case_id MÀ (date_of_reporting - date_of_data_entry) < 1 ngày VÀ (isolation_startdate - date_of_data_entry) < 1 ngày |
ĐẾM case_id
|
| Chỉ Số Quy Trình - Tốc Độ Truy Vết Tiếp Xúc | % những người tiếp xúc được thông báo và cách ly trong vòng 24 giờ kể từ khi được tìm thấy | ĐẾM contact_id MÀ followup_status == “SEEN_NOT_OK” HOẶC “SEEN_OK” VÀ date_of_followup - date_of_reporting < 1 ngày |
ĐẾM contact_id
|
| Chỉ Số Quy Trình - Tính Hoàn chỉnh của Việc Kiểm Tra | % các ca mắc có triệu chứng mới được kiểm tra và phỏng vấn trong vòng 3 ngày kể từ khi bắt đầu có triệu chứng | ĐẾM case_id MÀ (date_of_reporting - date_of_onset) < =3 ngày |
ĐẾM case_id
|
| Chỉ Số Kết quả - Tổng Kết | % các ca mắc mới trong danh sách liên hệ hiện có | ĐẾM case_id MÀ was_contact == “TRUE” |
ĐẾM case_id
|
Sau đây chúng tôi sẽ giới thiệu một bài tập mẫu về cách tạo bảng đẹp mắt để hiển thị thông tin theo dõi người tiếp xúc trên các khu vực hành chính. Cho tới bước cuối cùng, chúng tôi sẽ tạo bảng phù hợp để trình bày với package formattable (nhưng bạn có thể sử dụng các package khác như flextable - xem chương Trình bày bảng).
Cách bạn tạo một bảng như thế nào sẽ phụ thuộc vào cấu trúc của dữ liệu truy vết tiếp xúc của bạn. Sử dụng chương Bảng mô tả để tìm hiểu cách tóm tắt dữ liệu bằng các hàm dplyr.
Chúng tôi sẽ tạo một bảng động và thay đổi khi dữ liệu thay đổi. Để làm cho kết quả thú vị, chúng tôi sẽ thiết lập report_date nhằm cho phép chúng tôi mô phỏng việc chạy bảng vào một ngày nhất định (chúng tôi chọn ngày 10 tháng 6 năm 2020). Dữ liệu được lọc cho ngày đó.
# Set "Report date" to simulate running the report with data "as of" this date
report_date <- as.Date("2020-06-10")
# Create follow-up data to reflect the report date.
table_data <- followups_clean %>%
filter(date_of_followup <= report_date)Bây giờ, dựa trên cấu trúc dữ liệu, chúng ta sẽ làm như sau:
- Bắt đầu với dữ liệu
followupsvà tóm tắt nó để chứa cho mỗi liên hệ duy nhất:
- Ngày của bản ghi gần nhất (bất kể tình trạng của truy vết)
- Ngày truy vết gần nhất mà người tiếp xúc được “seen”
- Trạng thái truy vết ở lần truy vết “seen” cuối cùng (ví dụ: có triệu chứng, không có triệu chứng)
- Nối dữ liệu này với dữ liệu người tiếp xúc, dữ liệu mà chứa các thông tin khác như trạng thái tổng thể của người tiếp xúc, ngày tiếp xúc cuối với một ca mắc, v.v. Ngoài ra, chúng ta sẽ tính toán các số liệu được quan tâm cho mỗi người tiếp xúc, chẳng hạn như số ngày kể từ lần phơi nhiễm cuối
- Chúng ta nhóm dữ liệu người tiếp xúc nâng cao theo vùng địa lý (
admin_2_name) và tính toán tóm tắt thống kê cho mỗi khu vực
- Cuối cùng, chúng ta định dạng bảng thích hợp để trình bày
Đầu tiên, chúng ta tóm tắt dữ liệu theo dõi để có được thông tin quan tâm:
followup_info <- table_data %>%
group_by(contact_id) %>%
summarise(
date_last_record = max(date_of_followup, na.rm=T),
date_last_seen = max(date_of_followup[followup_status %in% c("seen_ok", "seen_not_ok")], na.rm=T),
status_last_record = followup_status[which(date_of_followup == date_last_record)]) %>%
ungroup()Đây là cách những dữ liệu này được nhìn thấy:
Bây giờ chúng ta sẽ thêm thông tin này vào bộ dữ liệu contacts và tính toán một số cột bổ sung.
contacts_info <- followup_info %>%
right_join(contacts, by = "contact_id") %>%
mutate(
database_date = max(date_last_record, na.rm=T),
days_since_seen = database_date - date_last_seen,
days_since_exposure = database_date - date_of_last_exposure
)Đây là cách những dữ liệu này được nhìn thấy. Lưu ý cột contacts nằm ở bên phải và cột mới được tính toán nằm ở ngoài cùng bên phải.
Tiếp theo, chúng ta tổng hợp dữ liệu người tiếp xúc theo khu vực, để có một data frame ngắn gọn của các cột thống kê đã tóm tắt.
contacts_table <- contacts_info %>%
group_by(`Admin 2` = admin_2_name) %>%
summarise(
`Registered contacts` = n(),
`Active contacts` = sum(contact_status == "UNDER_FOLLOW_UP", na.rm=T),
`In first week` = sum(days_since_exposure < 8, na.rm=T),
`In second week` = sum(days_since_exposure >= 8 & days_since_exposure < 15, na.rm=T),
`Became case` = sum(contact_status == "BECAME_CASE", na.rm=T),
`Lost to follow up` = sum(days_since_seen >= 3, na.rm=T),
`Never seen` = sum(is.na(date_last_seen)),
`Followed up - signs` = sum(status_last_record == "Seen_not_ok" & date_last_record == database_date, na.rm=T),
`Followed up - no signs` = sum(status_last_record == "Seen_ok" & date_last_record == database_date, na.rm=T),
`Not Followed up` = sum(
(status_last_record == "NOT_ATTEMPTED" | status_last_record == "NOT_PERFORMED") &
date_last_record == database_date, na.rm=T)) %>%
arrange(desc(`Registered contacts`))Và bây giờ chúng ta áp dụng kiểu bảng từ các package formattable và knitr, bao gồm một chú thích cuối trang hiển thị “kể từ” ngày.
contacts_table %>%
mutate(
`Admin 2` = formatter("span", style = ~ formattable::style(
color = ifelse(`Admin 2` == NA, "red", "grey"),
font.weight = "bold",font.style = "italic"))(`Admin 2`),
`Followed up - signs`= color_tile("white", "orange")(`Followed up - signs`),
`Followed up - no signs`= color_tile("white", "#A0E2BD")(`Followed up - no signs`),
`Became case`= color_tile("white", "grey")(`Became case`),
`Lost to follow up`= color_tile("white", "grey")(`Lost to follow up`),
`Never seen`= color_tile("white", "red")(`Never seen`),
`Active contacts` = color_tile("white", "#81A4CE")(`Active contacts`)
) %>%
kable("html", escape = F, align =c("l","c","c","c","c","c","c","c","c","c","c")) %>%
kable_styling("hover", full_width = FALSE) %>%
add_header_above(c(" " = 3,
"Of contacts currently under follow up" = 5,
"Status of last visit" = 3)) %>%
kableExtra::footnote(general = str_glue("Data are current to {format(report_date, '%b %d %Y')}"))| Admin 2 | Registered contacts | Active contacts | In first week | In second week | Became case | Lost to follow up | Never seen | Followed up - signs | Followed up - no signs | Not Followed up |
|---|---|---|---|---|---|---|---|---|---|---|
| Djembe | 59 | 30 | 44 | 0 | 2 | 15 | 22 | 0 | 0 | 0 |
| Trumpet | 3 | 1 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Venu | 2 | 0 | 0 | 0 | 2 | 0 | 2 | 0 | 0 | 0 |
| Congas | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
| Cornet | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
| Note: | ||||||||||
| Data are current to Jun 10 2020 |
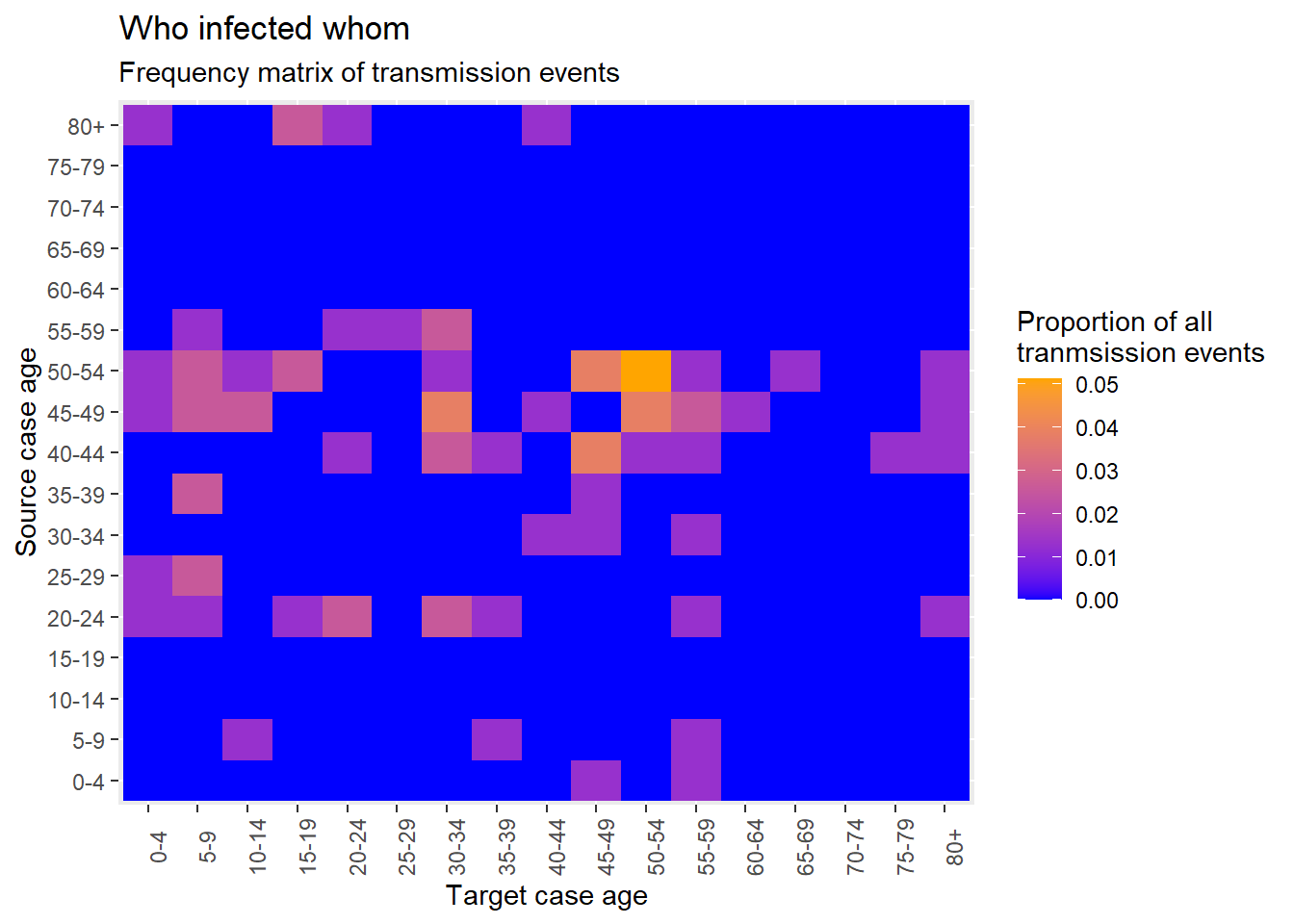
25.5 Ma trận lây truyền
Như đã thảo luận trong chương Biểu đồ nhiệt, bạn có thể tạo ma trận “ai đã lây nhiễm cho ai” bằng cách sử dụng hàm geom_tile().
Khi những ca tiếp xúc mới được tạo, Go.Data lưu trữ thông tin về mối quan hệ này tại điểm cuối API relationships; chúng ta có thể thấy 50 hàng đầu tiên của bộ dữ liệu này bên dưới. Điều này có nghĩa là chúng ta có thể tạo một biểu đồ nhiệt với một vài bước với mỗi tiếp điểm được nối với ca mắc nguồn của nó.
Như đã thực hiện ở trên đối với tháp tuổi so sánh các ca mắc và những người tiếp xúc, chúng ta có thể chọn một vài biến số chúng ta cần và tạo các cột nhóm tuổi được phân loại cho cả dữ liệu nguồn (ca mắc) và mục tiêu (người tiếp xúc).
heatmap_ages <- relationships %>%
select(source_age, target_age) %>%
mutate( # transmute is like mutate() but removes all other columns
source_age_class = epikit::age_categories(source_age, breakers = seq(0, 80, 5)),
target_age_class = epikit::age_categories(target_age, breakers = seq(0, 80, 5))) Như đã mô tả bên trên, chúng ta tạo bảng chéo;
cross_tab <- table(
source_cases = heatmap_ages$source_age_class,
target_cases = heatmap_ages$target_age_class)
cross_tab target_cases
source_cases 0-4 5-9 10-14 15-19 20-24 25-29 30-34 35-39 40-44 45-49 50-54
0-4 0 0 0 0 0 0 0 0 0 1 0
5-9 0 0 1 0 0 0 0 1 0 0 0
10-14 0 0 0 0 0 0 0 0 0 0 0
15-19 0 0 0 0 0 0 0 0 0 0 0
20-24 1 1 0 1 2 0 2 1 0 0 0
25-29 1 2 0 0 0 0 0 0 0 0 0
30-34 0 0 0 0 0 0 0 0 1 1 0
35-39 0 2 0 0 0 0 0 0 0 1 0
40-44 0 0 0 0 1 0 2 1 0 3 1
45-49 1 2 2 0 0 0 3 0 1 0 3
50-54 1 2 1 2 0 0 1 0 0 3 4
55-59 0 1 0 0 1 1 2 0 0 0 0
60-64 0 0 0 0 0 0 0 0 0 0 0
65-69 0 0 0 0 0 0 0 0 0 0 0
70-74 0 0 0 0 0 0 0 0 0 0 0
75-79 0 0 0 0 0 0 0 0 0 0 0
80+ 1 0 0 2 1 0 0 0 1 0 0
target_cases
source_cases 55-59 60-64 65-69 70-74 75-79 80+
0-4 1 0 0 0 0 0
5-9 1 0 0 0 0 0
10-14 0 0 0 0 0 0
15-19 0 0 0 0 0 0
20-24 1 0 0 0 0 1
25-29 0 0 0 0 0 0
30-34 1 0 0 0 0 0
35-39 0 0 0 0 0 0
40-44 1 0 0 0 1 1
45-49 2 1 0 0 0 1
50-54 1 0 1 0 0 1
55-59 0 0 0 0 0 0
60-64 0 0 0 0 0 0
65-69 0 0 0 0 0 0
70-74 0 0 0 0 0 0
75-79 0 0 0 0 0 0
80+ 0 0 0 0 0 0chuyển đổi thành định dạng dọc với những tỷ lệ;
long_prop <- data.frame(prop.table(cross_tab))và tạo biểu đồ nhiệt cho độ tuổi.
ggplot(data = long_prop)+ # use long data, with proportions as Freq
geom_tile( # visualize it in tiles
aes(
x = target_cases, # x-axis is case age
y = source_cases, # y-axis is infector age
fill = Freq))+ # color of the tile is the Freq column in the data
scale_fill_gradient( # adjust the fill color of the tiles
low = "blue",
high = "orange")+
theme(axis.text.x = element_text(angle = 90))+
labs( # labels
x = "Target case age",
y = "Source case age",
title = "Who infected whom",
subtitle = "Frequency matrix of transmission events",
fill = "Proportion of all\ntranmsission events" # legend title
)
25.6 Tài nguyên học liệu
https://github.com/WorldHealthOrganization/godata/tree/master/analytics/r-reporting