24 Modélisation des épidémies
24.1 Overview
Il existe un nombre croissant d’outils pour la modélisation des épidémies qui nous permettent de mener des analyses assez complexes avec un effort minimal.Cette section fournira une aperçu sur la façon d’utiliser ces outils pour :
- estimer le nombre de reproduction effectif Rt et les statistiques connexes. telles que le temps de doublement
- produire des projections à court terme de l’incidence future.
Il ne s’agit pas d’un aperçu des méthodologies et des méthodes statistiques qui sous-tendent ces outils. Veuillez donc vous référer à l’onglet Ressources pour des liens vers des documents traitant de ce sujet. Assurez-vous d’avoir une bonne compréhension des les méthodes avant d’utiliser ces outils ; cela vous permettra d’interpréter correctement leurs résultats.
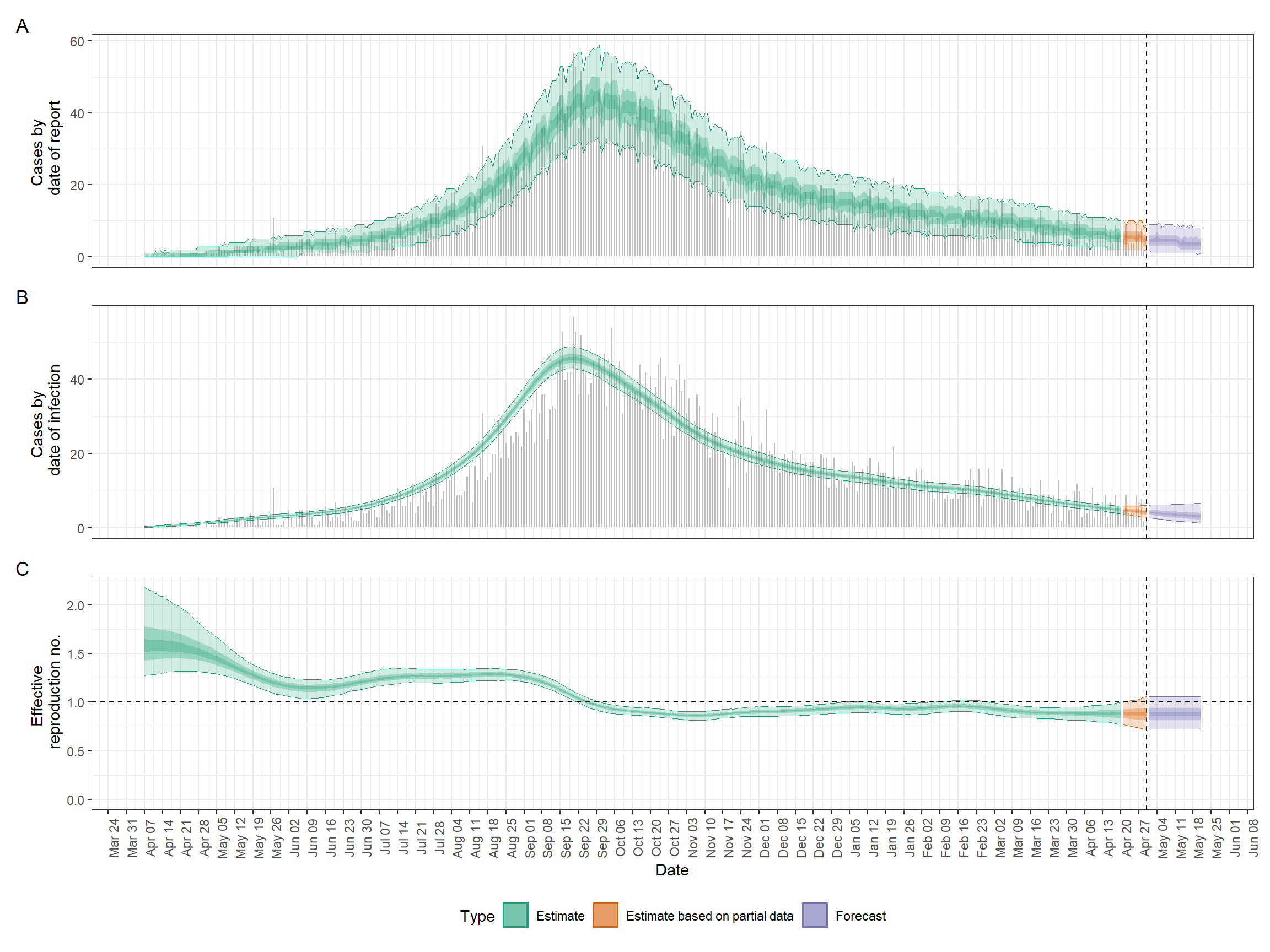
Voici un exemple de l’un des résultats que nous produirons dans cette section.
24.2 Préparation
Nous allons utiliser deux méthodes et packages différents pour l’estimation Rt, à savoir EpiNow et EpiEstim, ainsi que le package projections pour la prévision de l’incidence des cas.
Ce fragment de code montre le chargement des paquets nécessaires aux analyses. Dans ce manuel, nous mettons l’accent sur p_load() de pacman, qui installe le paquet si nécessaire et le charge pour l’utiliser. Vous pouvez également charger les paquets installés avec library() de base R. Voir la page sur R basics pour plus d’informations sur les paquets R.
pacman::p_load(
rio, # Importation de fichiers
here, # Localisation de fichiers
tidyverse, # Gestion des données + graphiques ggplot2
epicontacts, # Analyse des réseaux de transmission
EpiNow2, # Estimation de Rt
EpiEstim, # Estimation Rt
projections, # Projections d'incidence
incidence2, # Traitement des données d'incidence
epitrix, # Fonctions epi utiles
distcrete # Distributions discrètes des délais
)Nous utiliserons la linelist de cas nettoyée pour toutes les analyses de cette section. Si vous voulez suivre, cliquez pour télécharger la linelist “propre” (en tant que fichier .rds). Consultez la page Télécharger le manuel et les données pour télécharger tous les exemples de données utilisés dans ce manuel.
# Importez la liste de cas nettoyée
linelist <- import("linelist_cleaned.rds")24.3 Estimation de Rt
EpiNow2 vs. EpiEstim
Le taux de reproduction R est une mesure de la transmissibilité d’une maladie, et est défini comme le nombre attendu de cas secondaires par cas infecté. Dans une population totalement sensible, cette valeur représente le nombre de reproduction de base, R0. Cependant, comme le nombre d’individus sensibles dans une population évolue au cours d’une épidémie ou d’une pandémie, et que diverses mesures de réponse sont mises en œuvre, la mesure la plus couramment utilisée de la transmissibilité est le taux de reproduction effectif, Rt ; il est défini défini comme le nombre attendu de cas secondaires par cas infecté à un moment, t.
Le paquet EpiNow2 fournit le cadre le plus sophistiqué pour l’estimation de Rt. Il présente deux avantages essentiels par rapport à l’autre paquet couramment utilisé, EpiEstim :
- Il tient compte des délais de déclaration et peut donc estimer Rt même lorsque les données récentes sont incomplètes.
- Il estime Rt sur les dates d’infection plutôt que sur les dates de début de déclaration, ce qui signifie que l’effet d’une intervention sera immédiatement reflété dans un changement de Rt, plutôt qu’avec un delai.
Cependant, elle présente également deux inconvénients majeurs :
- Elle nécessite la connaissance de la distribution des temps de génération (c’est-à-dire la distribution des délais entre l’infection d’un cas primaire et d’un cas secondaire), la distribution de la période d’incubation (c’est-à-dire la distribution des délais entre l’infection et l’apparition des symptômes) et toute autre distribution de délai pertinente pour vos données (par exemple, si vous avez des dates de déclaration, vous avez besoin de la distribution des délais entre l’apparition des symptômes et la déclaration, ou la période d’incubation). Bien que cela permette une estimation plus précise de Rt, EpiEstim ne requiert que la distribution de l’intervalle sériel (c’est-à-dire la distribution des délais entre l’apparition des symptômes d’un cas primaire et d’un cas secondaire), qui peut être la seule distribution disponible pour vous.
- EpiNow2 est significativement plus lent que EpiEstim, de manière anecdotique par un facteur de 100 à 1000 ! Par exemple, l’estimation de Rt pour l’échantillon de foyers considéré dans cette section prend environ quatre heures (ceci a été exécuté pour un grand d’itérations pour garantir une grande précision et pourrait probablement être réduite si nécessaire) mais il n’en reste pas moins que l’algorithme est lent en général. Cela peut être irréalisable si vous mettez régulièrement à jour votre base de données pour Rt.
Le paquet que vous choisirez d’utiliser dépendra donc des données, du temps et des ressources informatiques dont vous disposez.
EpiNow2
24.3.0.1 Estimation des distributions de retard
Les distributions de retard requises pour exécuter EpiNow2 dépendent des données dont vous disposez. Essentiellement, vous devez être en mesure de décrire le délai entre la date d’infection à la date de l’événement que vous voulez utiliser pour estimer Rt. Si vous utilisez les dates d’apparition, il s’agit simplement de la distribution de la période d’incubation. Si vous utilisez les dates de déclaration, vous avez besoin du délai entre l’infection et la déclaration. Comme il est peu probable que cette distribution soit connue directement, EpiNow2 vous permet d’enchaîner plusieurs distributions de délai ; dans ce cas, le délai entre l’infection et la déclaration est le même.
Comme nous disposons des dates d’apparition des symptômes pour tous nos cas dans la liste d’exemples, nous n’aurons besoin que de la distribution de la période d’incubation pour déterminer le délai d’apparition des symptômes.Nous pouvons soit estimer cette distribution à partir des données ou utiliser les valeurs de la littérature.
Une estimation de la période d’incubation d’Ebola dans la littérature (tirée de cet article) avec une moyenne de 9,1, un écart-type de 7,3 et une valeur maximale de 30, serait spécifiée comme suit :
incubation_period_lit <- list(
mean = log(9.1),
mean_sd = log(0.1),
sd = log(7.3),
sd_sd = log(0.1),
max = 30
)Notez que EpiNow2 exige que ces distributions de délais soient fournies sur une échelle log d’où l’appel log autour de chaque valeur (sauf le paramètre max qui doit être fourni sur une échelle naturelle). Les paramètres mean_sd et sd_sd définissent l’écart type des estimations de la moyenne. Comme ceux-ci ne sont pas connus dans ce cas, nous choisissons la valeur assez arbitraire de 0.1.
Dans cette analyse, nous estimons plutôt la distribution de la période d’incubation à partir de la linelist elle-même en utilisant la fonction bootstrapped_dist_fit, ce qui va une distribution lognormale aux délais observés entre l’infection et l’apparition de la maladie.
## Estimation de la période d'incubation
incubation_period <- bootstrapped_dist_fit(
linelist$date_onset - linelist$date_infection,
dist = "lognormal",
max_value = 100,
bootstraps = 1
)L’autre distribution dont nous avons besoin est le temps de génération. Comme nous avons des données sur les temps d’infection et les liens de transmission, nous pouvons estimer cette distribution à partir de la liste de liens en calculant le délai entre les temps d’infection des paires infecteur-infecte. Pour ce faire, nous utilisons la fonction pratique get_pairwise du paquet epicontacts, qui nous permet de calculer les différences par paire des propriétés de la linelist entre les paires de transmission. Nous créons d’abord un objet epicontacts (voir la page Chaînes de transmission pour plus de détails) :
## générer des contacts
contacts <- linelist %>%
transmute(
from = infector,
to = case_id
) %>%
drop_na()
## générer un objet epicontacts
epic <- make_epicontacts(
linelist = linelist,
contacts = contacts,
directed = TRUE
)Nous ajustons ensuite la différence de temps d’infection entre les paires de transmission, calculée en utilisant get_pairwise, à une distribution gamma :
## estimation du temps de génération gamma
generation_time <- bootstrapped_dist_fit(
get_pairwise(epic, "date_infection"),
dist = "gamma",
max_value = 20,
bootstraps = 1
)Exécution de EpiNow2
Maintenant, il ne nous reste plus qu’à calculer l’incidence journalière à partir de la liste linéaire, ce que nous pouvons faire facilement avec les fonctions dplyr group_by() et n(). Notez que EpiNow2 exige que les noms des colonnes soient date et confirm.
## Obtenir l'incidence à partir des dates d'apparition
cases <- linelist %>%
group_by(date = date_onset) %>%
summarise(confirm = n())Nous pouvons ensuite estimer Rt en utilisant la fonction epinow. Quelques remarques sur les entrées :
- Nous pouvons fournir n’importe quel nombre de distributions de délais “enchaînés” à l’argument
delays. Nous les insérons simplement à côté de l’objetincubation_perioddans la fonctiondelay_opts. -
return_outputpermet de s’assurer que la sortie est retournée dans R et pas seulement un fichier. -
verbosespécifie que nous voulons une lecture de la progression. -
horizonindique pour combien de jours nous voulons projeter l’incidence future. - Nous passons des options supplémentaires à l’argument
stanpour spécifier combien de temps nous voulons exécuter l’inférence pour. L’augmentation desampleset dechainsvous donnera une estimation plus précise qui caractérisera mieux l’incertitude.
Cependant, l’exécution sera plus longue.
## exécuter epinow
epinow_res <- epinow(
reported_cases = cases,
generation_time = generation_time,
delays = delay_opts(incubation_period),
return_output = TRUE,
verbose = TRUE,
horizon = 21,
stan = stan_opts(samples = 750, chains = 4)
)Analyser les sorties
Une fois l’exécution du code terminée, nous pouvons tracer un résumé très facilement comme suit. Faites défiler l’image pour voir l’étendue complète.
## Tracer la figure récapitulative
plot(epinow_res)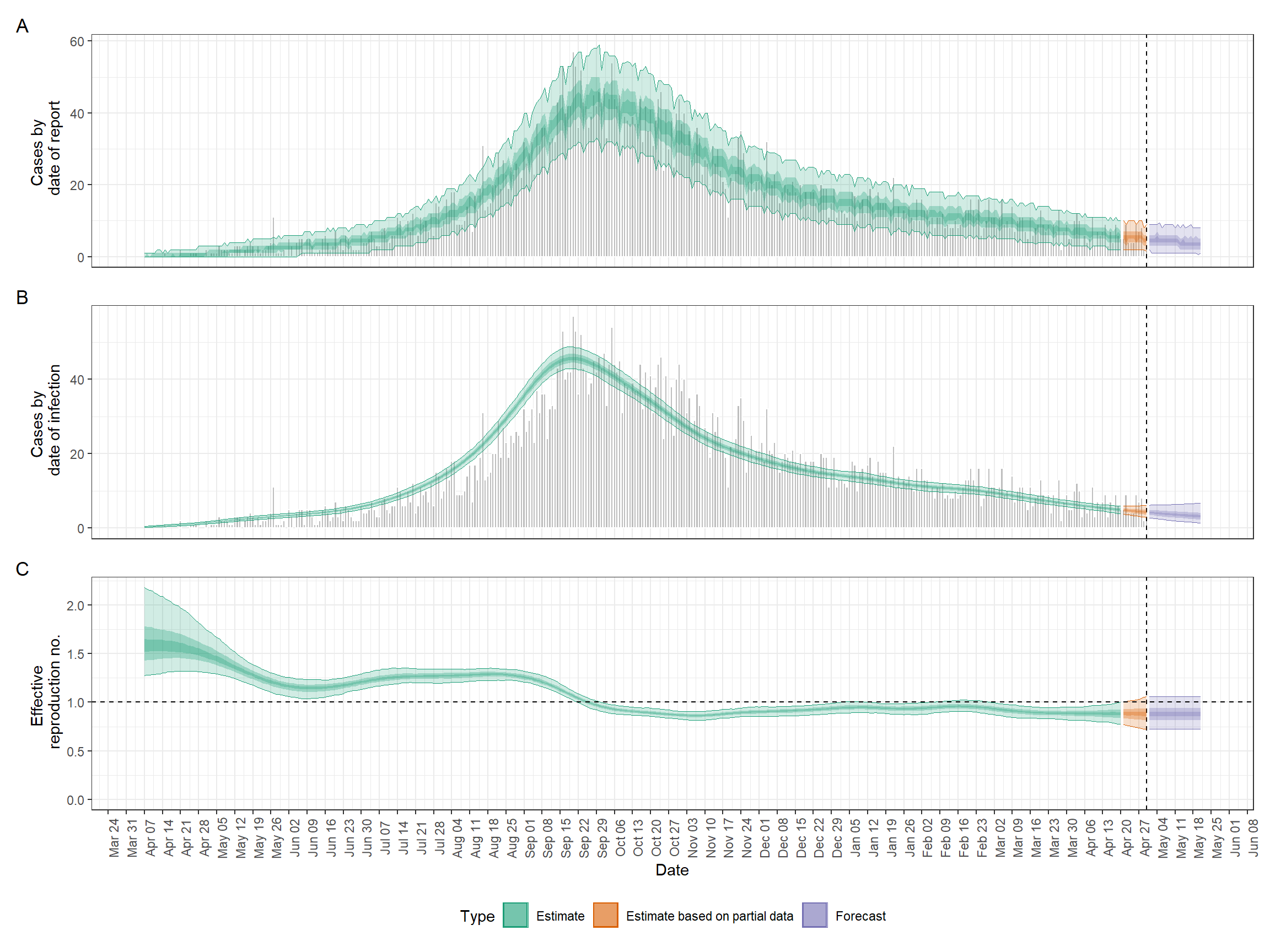
Nous pouvons également examiner diverses statistiques sommaires :
## tableau récapitulatif
epinow_res$summary measure estimate
<char> <char>
1: New confirmed cases by infection date 4 (2 -- 6)
2: Expected change in daily cases Unsure
3: Effective reproduction no. 0.88 (0.73 -- 1.1)
4: Rate of growth -0.012 (-0.028 -- 0.0052)
5: Doubling/halving time (days) -60 (130 -- -25)
numeric_estimate
<list>
1: <data.table[1x9]>
2: 0.56
3: <data.table[1x9]>
4: <data.table[1x9]>
5: <data.table[1x9]>Pour des analyses plus approfondies et des tracés personnalisés, vous pouvez accéder aux estimations quotidiennes résumées via $estimates$summarised. Nous allons convertir le tableau par défaut data.table en un tibble pour faciliter l’utilisation avec dplyr.
## extraire le résumé et le convertir en tibble
estimates <- as_tibble(epinow_res$estimates$summarised)
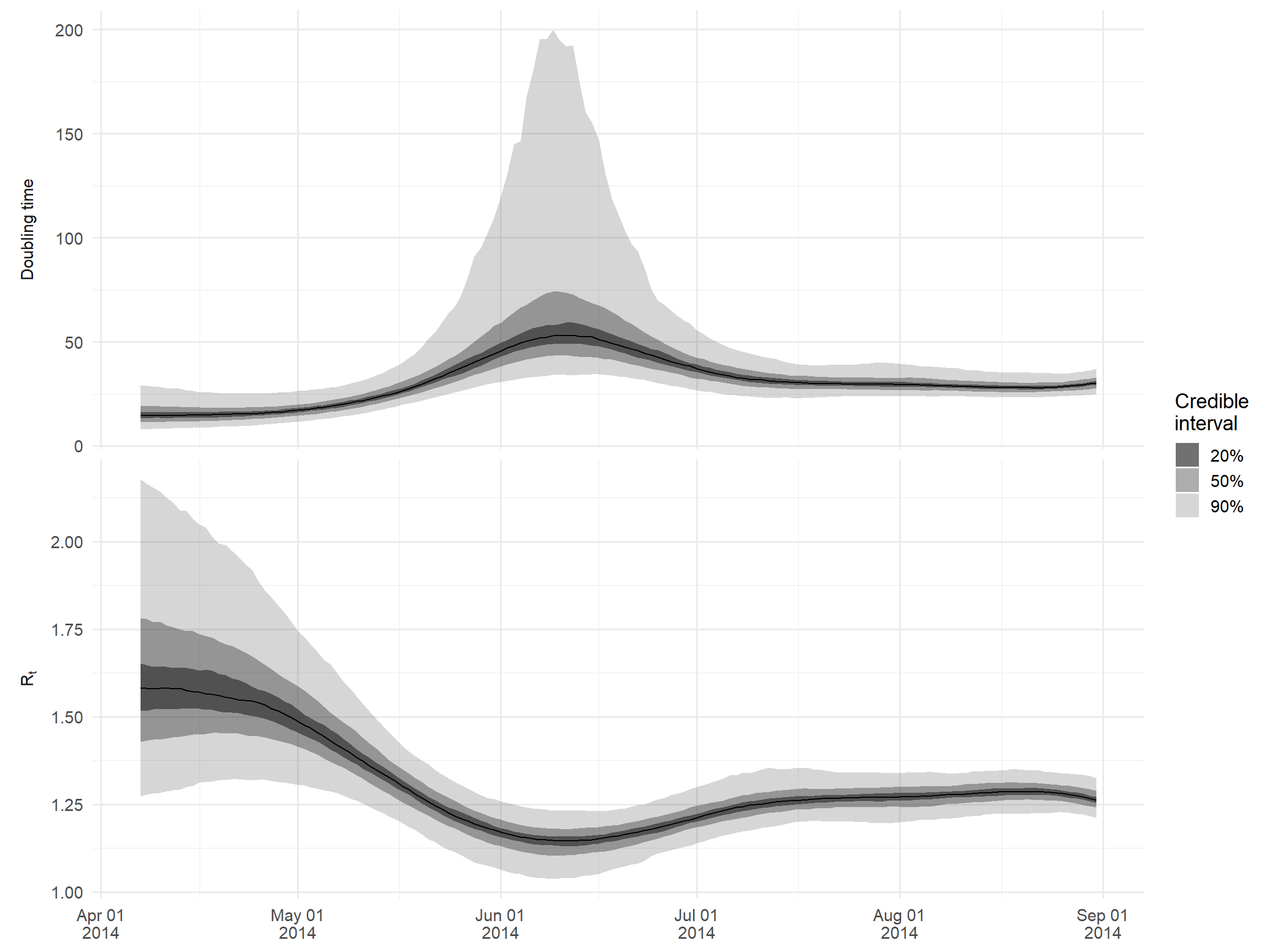
estimatesA titre d’exemple, faisons un graphique du temps de doublement et de Rt. Nous n’examinerons que les premiers mois de l’épidémie, lorsque Rt est largement supérieur à un, pour éviter de tracer des temps de doublement extrêmement élevés.
Nous utilisons la formule log(2)/taux de croissance pour calculer le temps de doublement à partir du taux de croissance estimé.
## faire des df larges pour le tracé de la médiane
df_wide <- estimates %>%
filter(
variable %in% c("growth_rate", "R"),
date < as.Date("2014-09-01")
) %>%
## convertir les taux de croissance en temps de doublement
mutate(
across(
c(median, lower_90:upper_90),
~ case_when(
variable == "growth_rate" ~ log(2)/.x,
TRUE ~ .x
)
),
## renommer la variable pour refléter la transformation
variable = replace(variable, variable == "growth_rate", "doubling_time")
)
## créer des df longs pour le tracé des quantiles
df_long <- df_wide %>%
## ici, nous faisons correspondre les quantiles (par exemple, lower_90 à upper_90)
pivot_longer(
lower_90:upper_90,
names_to = c(".value", "quantile"),
names_pattern = "(.+)_(.+)"
)
## créer un graphique
ggplot() +
geom_ribbon(
data = df_long,
aes(x = date, ymin = lower, ymax = upper, alpha = quantile),
color = NA
) +
geom_line(
data = df_wide,
aes(x = date, y = median)
) +
## utiliser label_parsed pour permettre l'utilisation d'une étiquette en indice
facet_wrap(
~ variable,
ncol = 1,
scales = "free_y",
labeller = as_labeller(c(R = "R[t]", doubling_time = "Doubling~time"), label_parsed),
strip.position = 'left'
) +
## définir manuellement la transparence des quantiles
scale_alpha_manual(
values = c(`20` = 0.7, `50` = 0.4, `90` = 0.2),
labels = function(x) paste0(x, "%")
) +
labs(
x = NULL,
y = NULL,
alpha = "Credible\ninterval"
) +
scale_x_date(
date_breaks = "1 month",
date_labels = "%b %d\n%Y"
) +
theme_minimal(base_size = 14) +
theme(
strip.background = element_blank(),
strip.placement = 'outside'
)
EpiEstim
Pour exécuter EpiEstim, nous devons fournir des données sur l’incidence journalière et spécifier l’intervalle sériel (c’est-à-dire la distribution des délais entre l’apparition des symptômes des cas primaires et secondaires).
Les données d’incidence peuvent être fournies à EpiEstim sous la forme d’un vecteur, d’un cadre de données ou d’un objet incidence provenant du paquetage original incidence. Vous pouvez même faire la distinction entre les importations et les infections acquises localement ; voir la documentation de ?estimate_R pour plus de détails.
Nous allons créer l’entrée en utilisant incidence2. Voir la page sur Epidemic curves pour plus d’exemples avec le paquet incidence2. Comme il y a eu des mises à jour du paquet incidence2 qui ne correspondent pas complètement à l’entrée attendue de estimateR(), quelques étapes supplémentaires mineures sont nécessaires. L’objet incidence consiste en un tibble avec des dates et leurs nombres de cas respectifs. Nous utilisons complete() de tidyr pour nous assurer que toutes les dates sont incluses (même celles sans cas), puis nous rename() les colonnes pour les aligner avec ce qui est attendu par estimate_R() dans une étape ultérieure.
## Obtenir l'incidence à partir de la date d'apparition
cases <- incidence2::incidence(linelist, date_index = "date_onset") %>% # obtient le nombre de cas par jour
tidyr::complete(date_index = seq.Date( # s'assurer que toutes les dates sont représentées
from = min(date_index, na.rm = T),
to = max(date_index, na.rm=T),
by = "day"),
fill = list(count = 0)) %>% # convertit les comptes NA en 0
rename(I = count, # renomme aux noms attendus par estimateR
dates = date_index)Le paquetage fournit plusieurs options pour spécifier l’intervalle sériel, dont les détails sont fournis dans la documentation de ?estimate_R.
Utiliser des estimations d’intervalles sériels issues de la littérature
En utilisant l’option method = "parametric_si", nous pouvons spécifier manuellement la moyenne et l’écart type de l’intervalle sériel dans la littérature ou dans un objet config créé à l’aide de la fonction make_config. Nous utilisons une moyenne et un écart-type de 12.0 et 5.2, respectivement, définis dans cet article :
## créer config
config_lit <- make_config(
mean_si = 12.0,
std_si = 5.2
)Nous pouvons ensuite estimer Rt avec la fonction estimate_R :
cases <- cases %>%
filter(!is.na(date))
#créer un cadre de données pour la fonction estimate_R()
cases_incidence <- data.frame(dates = seq.Date(from = min(cases$dates),
to = max(cases$dates),
by = 1))
cases_incidence <- left_join(cases_incidence, cases) %>%
select(dates, I) %>%
mutate(I = ifelse(is.na(I), 0, I))Joining with `by = join_by(dates)`epiestim_res_lit <- estimate_R(
incid = cases_incidence,
method = "parametric_si",
config = config_lit
)Default config will estimate R on weekly sliding windows.
To change this change the t_start and t_end arguments. et tracer un résumé des résultats :
plot(epiestim_res_lit)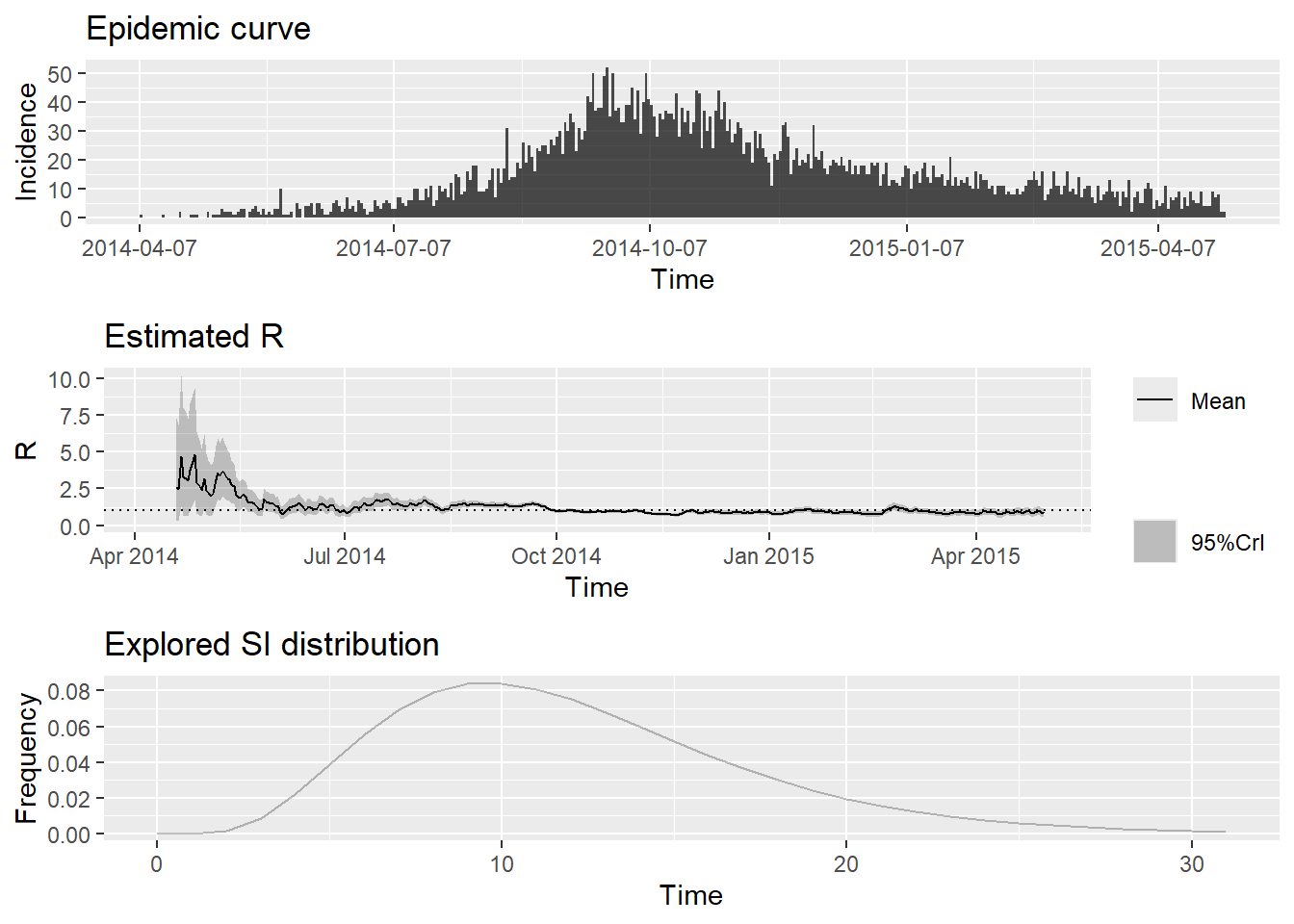
Utilisation d’estimations d’intervalles en série à partir des données
Comme nous avons des données sur les dates d’apparition des symptômes et les liens de transmission, nous pouvons également estimer l’intervalle sériel à partir de la liste de liens en calculant le délai entre les dates d’apparition des symptômes des paires infecteur-infecté. Comme nous l’avons fait dans la section EpiNow2 nous allons utiliser la fonction get_pairwise du paquet epicontacts qui nous permet de calculer les différences par paires des propriétés de la liste de liens entre les paires de transmission. Nous créons d’abord un objet epicontacts (voir la page Chaînes de transmission pour plus de détails) :
## générer des contacts
contacts <- linelist %>%
transmute(
from = infector,
to = case_id
) %>%
drop_na()
## générer un objet epicontacts
epic <- make_epicontacts(
linelist = linelist,
contacts = contacts,
directed = TRUE
)Nous ajustons ensuite la différence de dates d’apparition entre les paires de transmissions, calculée en utilisant get_pairwise, à une distribution gamma. Nous utilisons l’outil pratique fit_disc_gamma du paquet epitrix pour cette procédure d’ajustement, car nous avons besoin d’une distribution discrète.
## Estimation de l'intervalle sériel gamma
serial_interval <- fit_disc_gamma(get_pairwise(epic, "date_onset"))Nous passons ensuite ces informations à l’objet config, exécutons EpiEstim et traçons les résultats :
## faire le config
config_emp <- make_config(
mean_si = serial_interval$mu,
std_si = serial_interval$sd
)
## Exécuter epiestim
epiestim_res_emp <- estimate_R(
incid = cases_incidence,
method = "parametric_si",
config = config_emp
)Default config will estimate R on weekly sliding windows.
To change this change the t_start and t_end arguments. ## tracer les résultats
plot(epiestim_res_emp)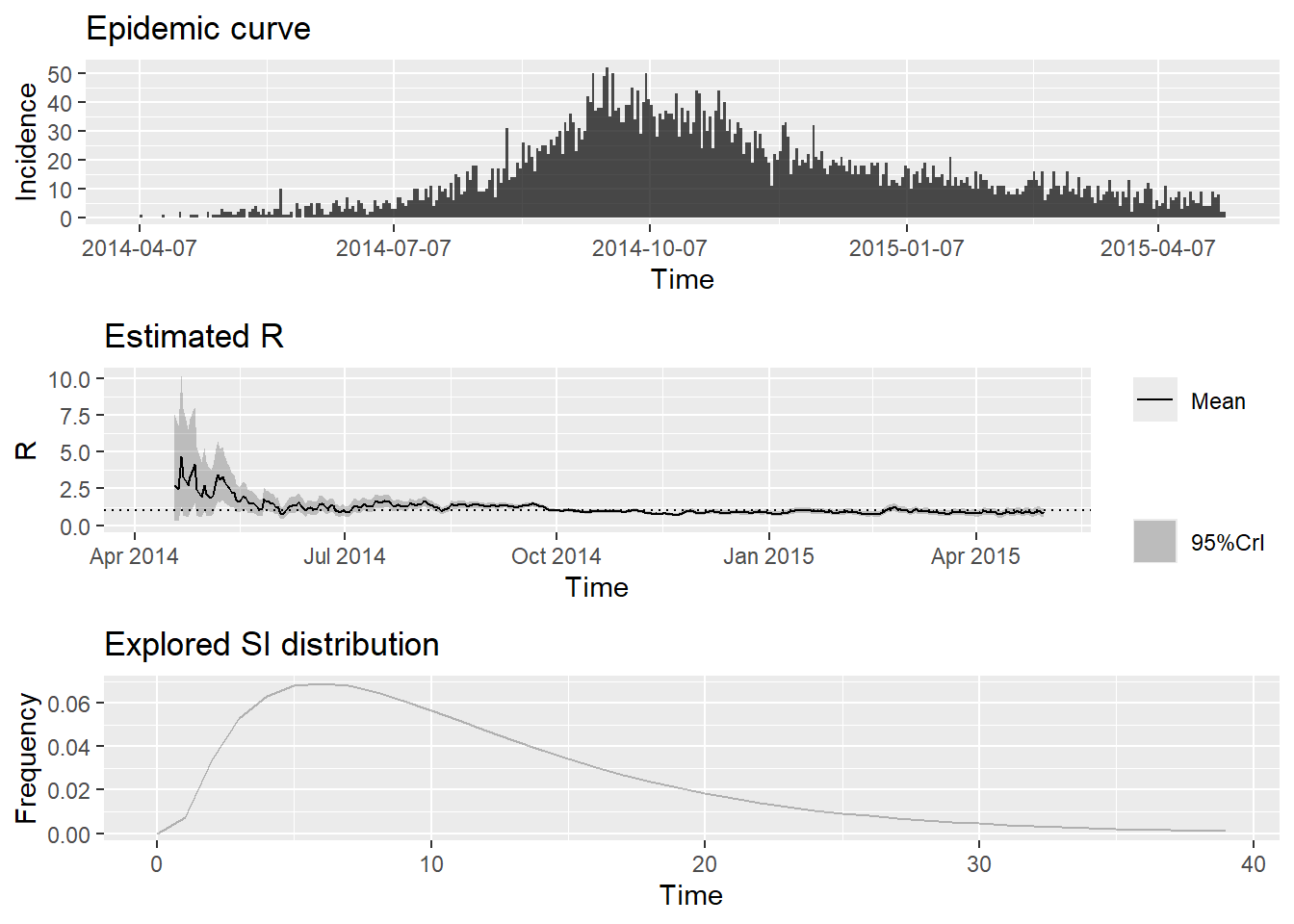
Spécification des fenêtres temporelles d’estimation
Ces options par défaut fournissent une estimation hebdomadaire glissante et peuvent servir d’avertissement si vous estimez Rt trop tôt dans l’épidémie pour une estimation précise.Vous pouvez changer cela en fixant une date de début ultérieure pour l’estimation de Rt, comme indiqué ci-dessous.
Malheureusement, EpiEstim n’offre qu’une façon très maladroite de spécifier ces temps d’estimation, en ce sens que vous devez fournir un vecteur d’entiers __ se référant aux dates de début et de fin de chaque fenêtre temporelle.
## définir un vecteur de dates commençant le 1er juin
start_dates <- seq.Date(
as.Date("2014-06-01"),
max(cases$dates) - 7,
by = 1
) %>%
## soustraire la date de départ pour la convertir en numérique
`-`(min(cases$dates)) %>%
## convertir en entier
as.integer()
## ajouter six jours pour une fenêtre glissante d'une semaine
end_dates <- start_dates + 6
## faire la configuration
config_partial <- make_config(
mean_si = 12.0,
std_si = 5.2,
t_start = start_dates,
t_end = end_dates
)Maintenant, nous réexécutons EpiEstim et nous pouvons voir que les estimations ne commencent qu’à partir de juin :
## exécuter epiestim
epiestim_res_partial <- estimate_R(
incid = cases_incidence,
method = "parametric_si",
config = config_partial
)
## tracer les résultats
plot(epiestim_res_partial)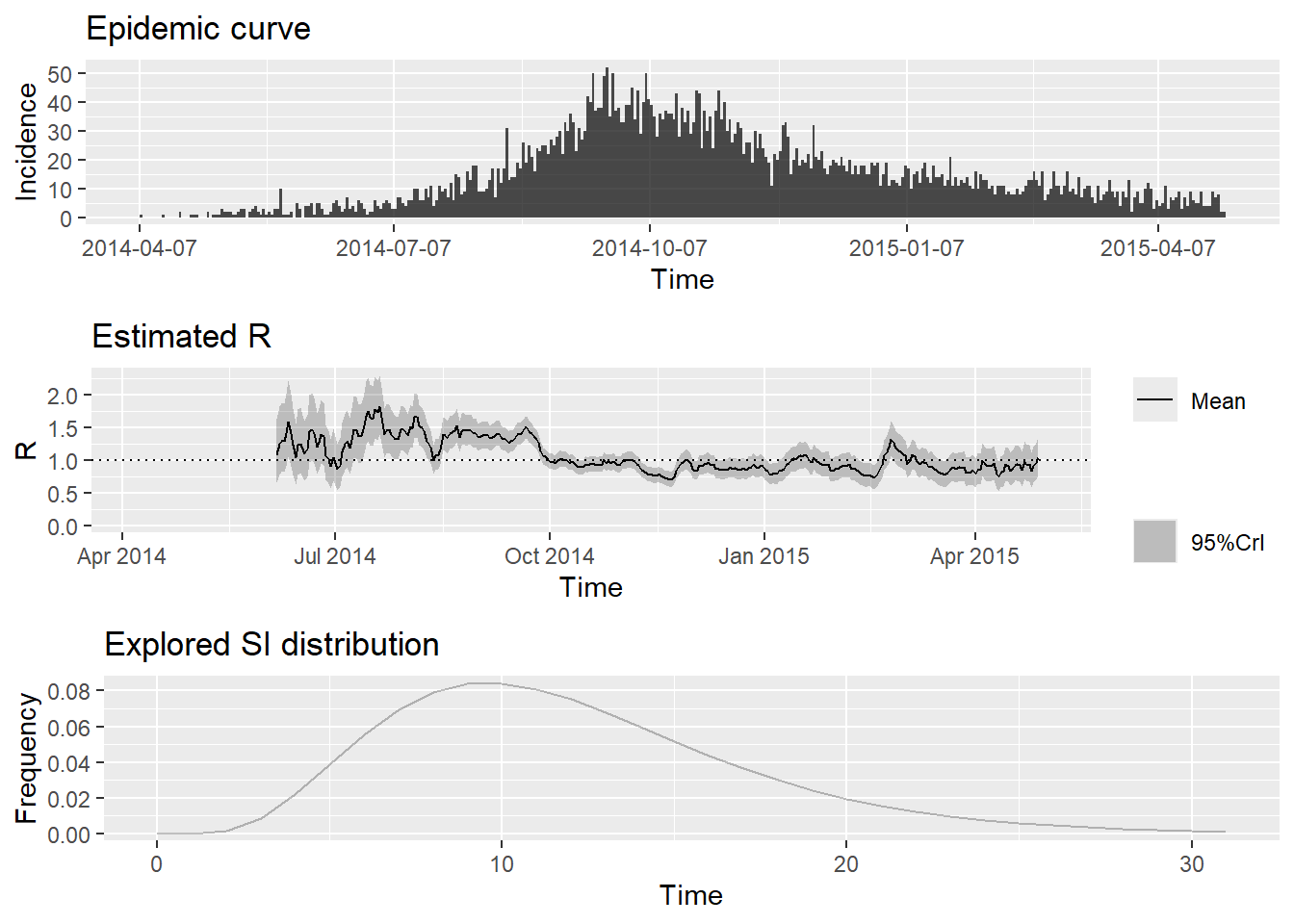
Analyser les sorties
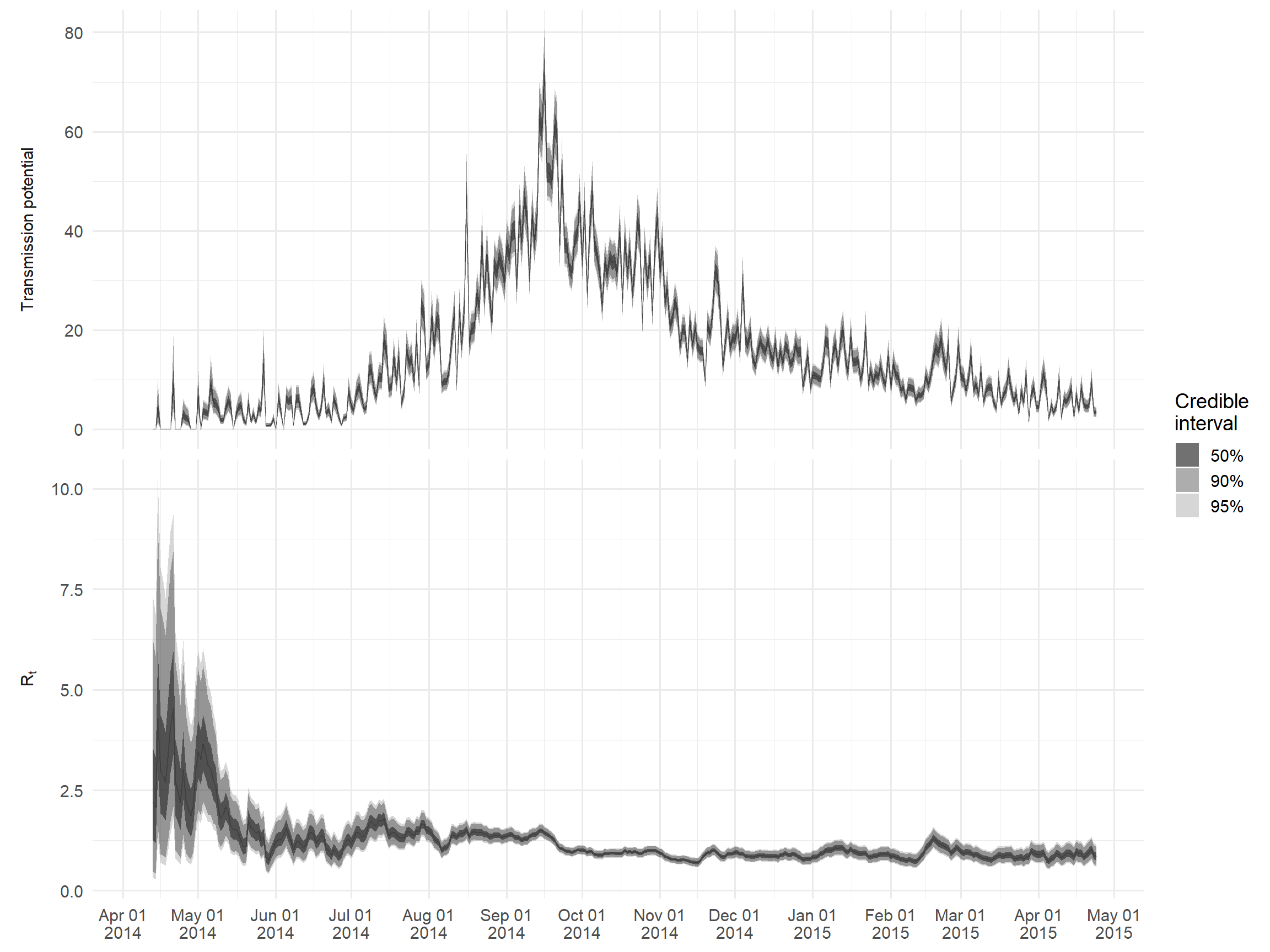
Les principales sorties sont accessibles via $R. A titre d’exemple, nous allons créer un graphe de Rt et une mesure de “potentiel de transmission” donnée par le produit de Rt et du nombre de cas signalés ce jour-là ; cela représente le nombre attendu de cas dans la prochaine génération d’infection.
## créer un cadre de données large pour la médiane
df_wide <- epiestim_res_lit$R %>%
rename_all(clean_labels) %>%
rename(
lower_95_r = quantile_0_025_r,
lower_90_r = quantile_0_05_r,
lower_50_r = quantile_0_25_r,
upper_50_r = quantile_0_75_r,
upper_90_r = quantile_0_95_r,
upper_95_r = quantile_0_975_r,
) %>%
mutate(
## extraire la date médiane de t_start et t_end
dates = epiestim_res_emp$dates[round(map2_dbl(t_start, t_end, median))],
var = "R[t]"
) %>%
## fusionner les données d'incidence quotidienne
left_join(cases, "dates") %>%
## calculer le risque pour toutes les estimations r
mutate(
across(
lower_95_r:upper_95_r,
~ .x*I,
.names = "{str_replace(.col, '_r', '_risk')}"
)
) %>%
## séparer les estimations de r et les estimations de risque
pivot_longer(
contains("median"),
names_to = c(".value", "variable"),
names_pattern = "(.+)_(.+)"
) %>%
## Assigner des niveaux de facteurs
mutate(variable = factor(variable, c("risk", "r")))
## créer un cadre de données long à partir des quantiles
df_long <- df_wide %>%
select(-variable, -median) %>%
## séparer les estimations de r/risque et les niveaux de quantile
pivot_longer(
contains(c("lower", "upper")),
names_to = c(".value", "quantile", "variable"),
names_pattern = "(.+)_(.+)_(.+)"
) %>%
mutate(variable = factor(variable, c("risk", "r")))
## créer un graphique
ggplot() +
geom_ribbon(
data = df_long,
aes(x = dates, ymin = lower, ymax = upper, alpha = quantile),
color = NA
) +
geom_line(
data = df_wide,
aes(x = dates, y = median),
alpha = 0.2
) +
## utiliser label_parsed pour permettre l'utilisation d'une étiquette en indice
facet_wrap(
~ variable,
ncol = 1,
scales = "free_y",
labeller = as_labeller(c(r = "R[t]", risk = "Transmission~potential"), label_parsed),
strip.position = 'left'
) +
## définir manuellement la transparence des quantiles
scale_alpha_manual(
values = c(`50` = 0.7, `90` = 0.4, `95` = 0.2),
labels = function(x) paste0(x, "%")
) +
labs(
x = NULL,
y = NULL,
alpha = "Credible\ninterval"
) +
scale_x_date(
date_breaks = "1 month",
date_labels = "%b %d\n%Y"
) +
theme_minimal(base_size = 14) +
theme(
strip.background = element_blank(),
strip.placement = 'outside'
)
24.4 Projection de l’incidence
EpiNow2
En plus de l’estimation de Rt, EpiNow2 permet également la prévision de Rt et les projections du nombre de cas par l’intégration avec le paquet EpiSoon sous le capot. Tout ce que vous avez à faire est de spécifier l’argument horizon dans votre appel de fonction epinow, indiquant le nombre de jours que vous voulez projeter dans le futur ; voir la section EpiNow2 sous la rubrique “Estimation Rt” pour plus de détails sur la façon de mettre en place EpiNow2. Dans cette section, nous allons simplement tracer les sorties de cette analyse, stockées dans le fichier l’objet epinow_res.
## définir la date minimale pour le tracé
min_date <- as.Date("2015-03-01")
## extraire les estimations résumées
estimates <- as_tibble(epinow_res$estimates$summarised)
## extraire les données brutes sur l'incidence des cas
observations <- as_tibble(epinow_res$estimates$observations) %>%
filter(date > min_date)
## extraire les estimations prévisionnelles du nombre de cas
df_wide <- estimates %>%
filter(
variable == "reported_cases",
type == "forecast",
date > min_date
)
## convertir en un format encore plus long pour le tracé des quantiles
df_long <- df_wide %>%
## ici nous faisons correspondre les quantiles (par exemple, lower_90 à upper_90)
pivot_longer(
lower_90:upper_90,
names_to = c(".value", "quantile"),
names_pattern = "(.+)_(.+)"
)
## créer un graphique
ggplot() +
geom_histogram(
data = observations,
aes(x = date, y = confirm),
stat = 'identity',
binwidth = 1
) +
geom_ribbon(
data = df_long,
aes(x = date, ymin = lower, ymax = upper, alpha = quantile),
color = NA
) +
geom_line(
data = df_wide,
aes(x = date, y = median)
) +
geom_vline(xintercept = min(df_long$date), linetype = 2) +
## Définir manuellement la transparence des quantiles
scale_alpha_manual(
values = c(`20` = 0.7, `50` = 0.4, `90` = 0.2),
labels = function(x) paste0(x, "%")
) +
labs(
x = NULL,
y = "Daily reported cases",
alpha = "Credible\ninterval"
) +
scale_x_date(
date_breaks = "1 month",
date_labels = "%b %d\n%Y"
) +
theme_minimal(base_size = 14)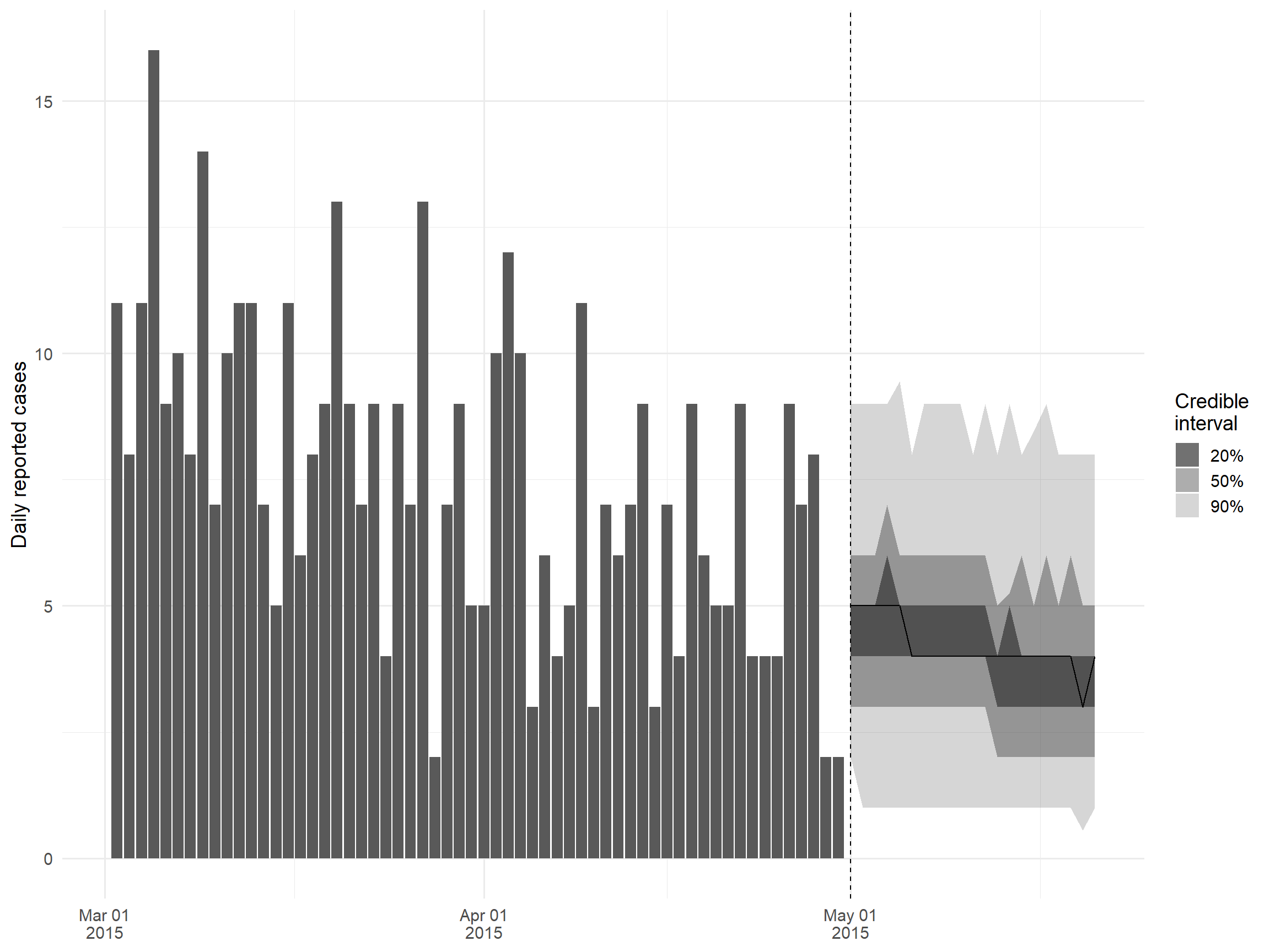
projections
Le paquet projections développé par RECON permet de faire très facilement des prévisions d’incidence à court terme, ne nécessitant que la connaissance du nombre de reproduction effectif de reproduction Rt et de l’intervalle de série. Nous verrons ici comment utiliser des estimations d’intervalle sériel de la littérature et comment utiliser nos propres estimations de la liste de diffusion.
Utiliser les estimations d’intervalles sériels de la littérature
projections nécessite une distribution d’intervalle série discrétisée de la classe distcrete du paquet distcrete. Nous utiliserons une distribution gamma avec une moyenne de 12,0 et un écart-type de 5,2 définie dans cet article. Pour convertir ces valeurs en paramètres de forme et d’échelle requis pour une distribution gamma. nous utiliserons la fonction gamma_mucv2shapescale du paquet epitrix.
## obtenir les paramètres de forme et d'échelle à partir du mu moyen et du coefficient de
## variation (par exemple, le rapport entre l'écart type et la moyenne).
shapescale <- epitrix::gamma_mucv2shapescale(mu = 12.0, cv = 5.2/12)
## fabriquer un objet distcrete
serial_interval_lit <- distcrete::distcrete(
name = "gamma",
interval = 1,
shape = shapescale$shape,
scale = shapescale$scale
)Voici une vérification rapide pour s’assurer que l’intervalle de série est correct. Nous accédons à la densité de la distribution gamma que nous venons de définir par $d, ce qui revient à appeler dgamma :
## vérifiez que l'intervalle série est correct
qplot(
x = 0:50, y = serial_interval_lit$d(0:50), geom = "area",
xlab = "Serial interval", ylab = "Density"
)Warning: `qplot()` was deprecated in ggplot2 3.4.0.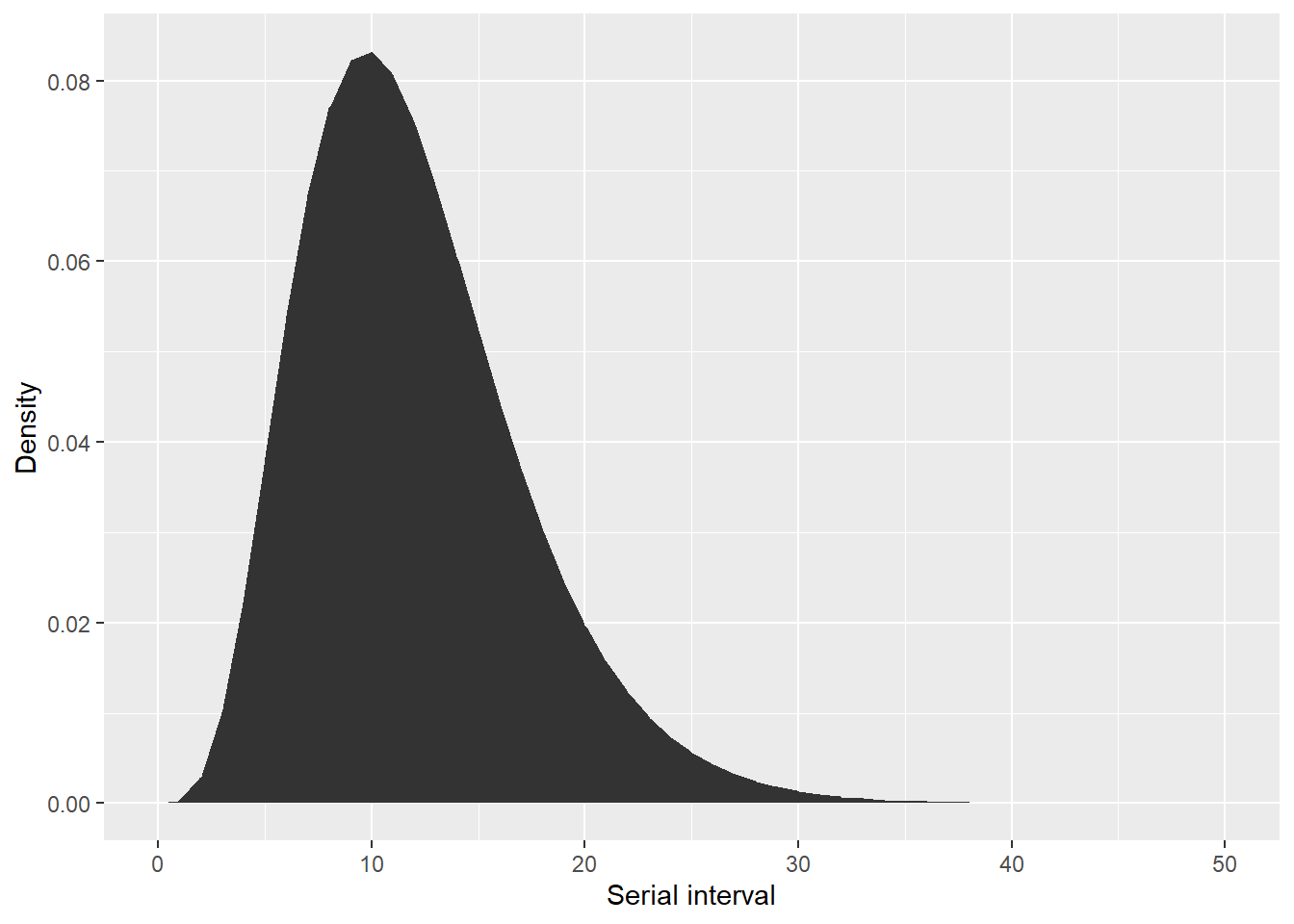
Utilisation des estimations d’intervalles sériels à partir des données
Comme nous avons des données sur les dates d’apparition des symptômes et les liens de transmission, nous pouvons également estimer l’intervalle sériel à partir de la liste de liens en calculant le délai entre les dates d’apparition des symptômes des paires infecteur-infecté. Comme nous l’avons fait dans la section EpiNow2, nous allons utiliser la fonction get_pairwise du paquet epicontacts qui nous permet de calculer les différences par paires des propriétés de la liste de liens entre les paires de transmission. Nous créons d’abord un objet epicontacts (voir la page Chaînes de transmission pour plus de détails) :
## générer des contacts
contacts <- linelist %>%
transmute(
from = infector,
to = case_id
) %>%
drop_na()
## générer un objet epicontacts
epic <- make_epicontacts(
linelist = linelist,
contacts = contacts,
directed = TRUE
)Nous ajustons ensuite la différence de dates d’apparition entre les paires de transmissions, calculée avec get_pairwise, à une distribution gamma. Nous utilisons l’outil pratique fit_disc_gamma du paquet epitrix pour cette procédure d’ajustement, car nous avons besoin d’une distribution discrète.
## Estimation de l'intervalle sériel gamma
serial_interval <- fit_disc_gamma(get_pairwise(epic, "date_onset"))
## inspecter l'estimation
serial_interval[c("mu", "sd")]$mu
[1] 11.51047
$sd
[1] 7.696056Projection de l’incidence
Pour projeter l’incidence future, nous devons fournir l’incidence historique sous la forme d’un objet incidence, ainsi qu’un échantillon de valeurs Rt plausibles. Nous générerons ces valeurs en utilisant les estimations Rt générées par EpiEstim dans la section précédente (sous “Estimation de la valeur de Rt”) et stockées dans l’objet epiestim_res_emp. Dans le code ci-dessous nous extrayons les estimations de la moyenne et de l’écart type de Rt pour la dernière fenêtre de temps de l’épidémie (en utilisant la fonction tail pour accéder au dernier élément d’un vecteur), et nous simulons 1000 valeurs à partir d’une distribution gamma en utilisant rgamma. Vous pouvez également fournir votre propre vecteur de valeurs Rt que vous souhaitez utiliser pour les projections.
## créer un objet d'incidence à partir des dates d'apparition des symptômes
inc <- incidence::incidence(linelist$date_onset)256 missing observations were removed.## extraire les valeurs r plausibles de l'estimation la plus récente
mean_r <- tail(epiestim_res_emp$R$`Mean(R)`, 1)
sd_r <- tail(epiestim_res_emp$R$`Std(R)`, 1)
shapescale <- gamma_mucv2shapescale(mu = mean_r, cv = sd_r/mean_r)
plausible_r <- rgamma(1000, shape = shapescale$shape, scale = shapescale$scale)
## vérifier la distribution
qplot(x = plausible_r, geom = "histogram", xlab = expression(R[t]), ylab = "Counts")`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.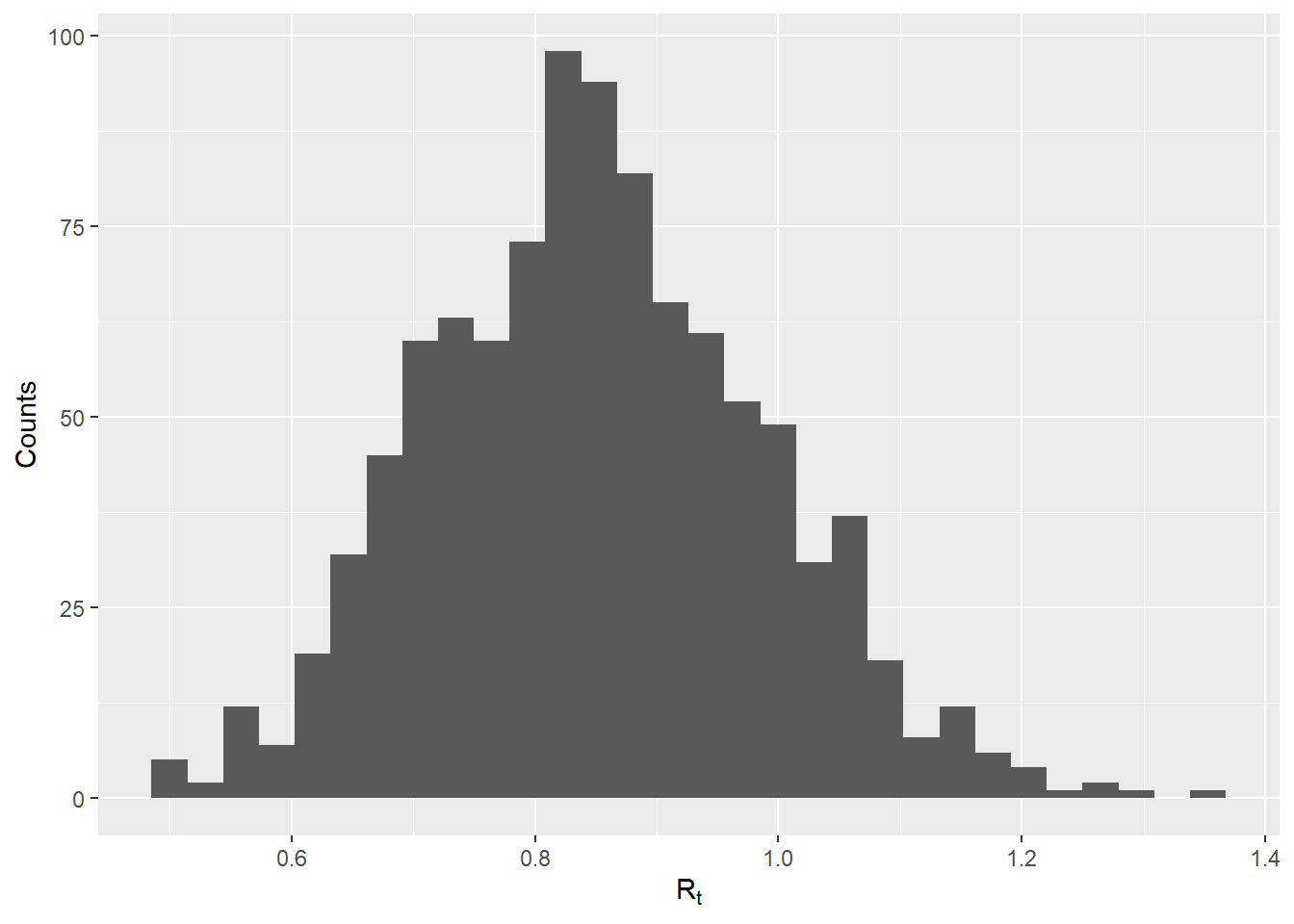
Nous utilisons ensuite la fonction project() pour effectuer la prévision réelle. Nous spécifions le nombre de jours pour lesquels nous voulons faire une projection via les arguments n_days, et nous spécifions le nombre de simulations en utilisant les arguments n_sim.
## faire une projection
proj <- project(
x = inc,
R = plausible_r,
si = serial_interval$distribution,
n_days = 21,
n_sim = 1000
)Nous pouvons alors facilement tracer l’incidence et les projections en utilisant les fonctions plot() et add_projections(). On peut facilement sous-évaluer l’objet incidence pour ne montrer que les cas les plus récents en utilisant l’opérateur de crochets.
## Tracer l'incidence et les projections
plot(inc[inc$dates > as.Date("2015-03-01")]) %>%
add_projections(proj)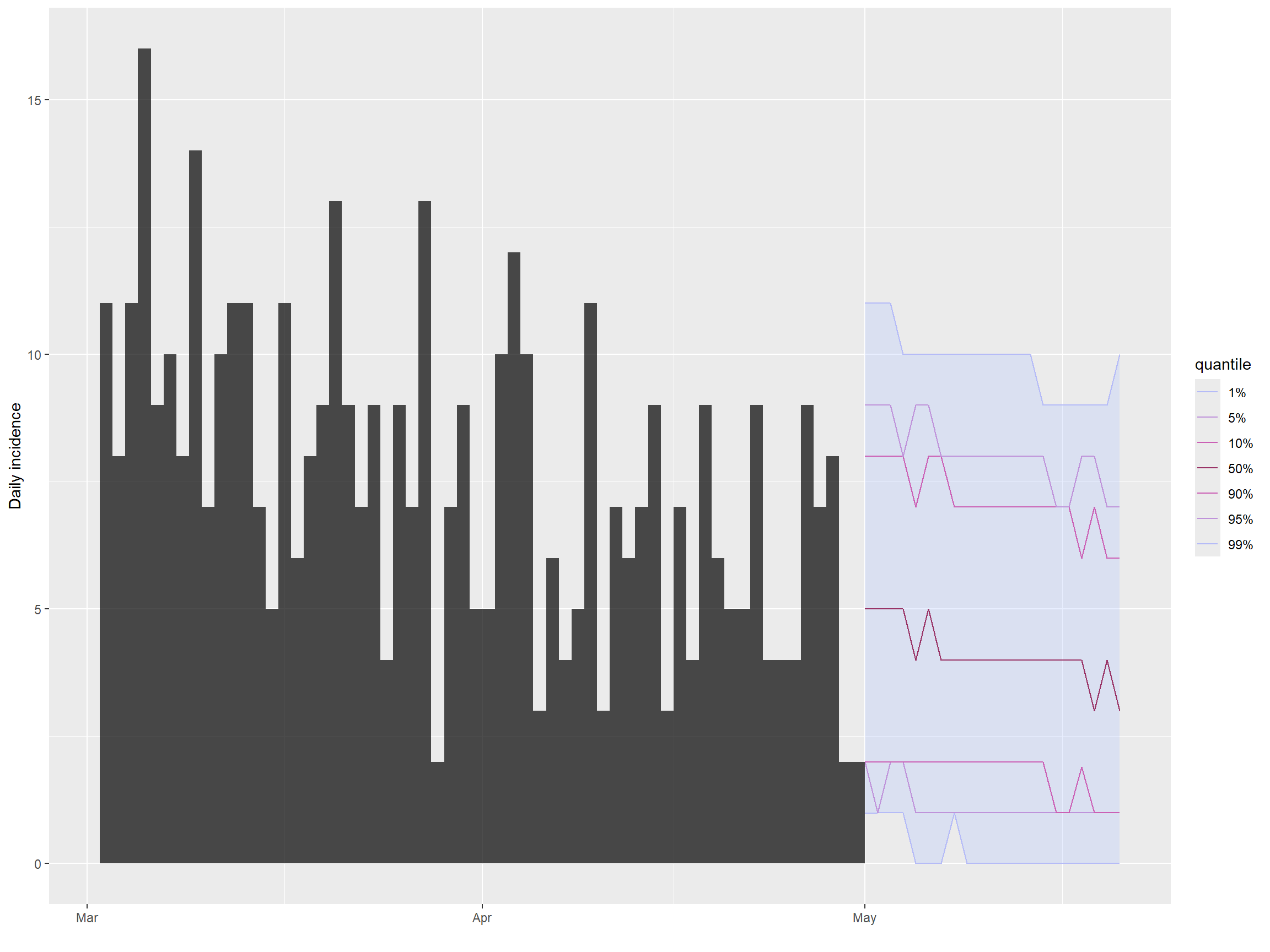
Vous pouvez également extraire facilement les estimations brutes du nombre de cas quotidiens en convertissant la sortie en un cadre de données.
## convertir en cadre de données pour les données brutes
proj_df <- as.data.frame(proj)
proj_df24.5 Ressources
Voici un article qui décrit la méthodologie mise en œuvre dans EpiEstim. Voici un article décrivant la méthodologie mise en œuvre dans EpiNow. Voici un article décrivant diverses considérations méthodologiques et pratiques pour l’estimation de Rt.