22 Moyennes mobiles
Cette page va couvrir deux méthodes pour calculer et visualiser les moyennes mobiles :
- Calculer avec le paquet slider.
- Calculer dans une commande
ggplot()avec le paquet tidyquant.
22.1 Préparation
Chargement des paquets
Ce morceau de code montre le chargement des paquets nécessaires aux analyses. Dans ce manuel, nous mettons l’accent sur p_load() de pacman, qui installe le paquet si nécessaire et le charge pour l’utiliser. Vous pouvez également charger les paquets installés avec library() de base R. Voir la page sur bases de R pour plus d’informations sur les paquets R.
pacman::p_load(
tidyverse, # pour la gestion des données et le viz
slider, # pour le calcul des moyennes mobiles
tidyquant # pour le calcul des moyennes mobiles dans ggplot
)Importer des données
Nous importons le jeu de données des cas d’une épidémie d’Ebola simulée. Si vous voulez suivre, cliquez pour télécharger la liste de lignes “propre” (en tant que fichier .rds). Importez des données avec la fonction import() du paquet rio (elle gère de nombreux types de fichiers comme .xlsx, .csv, .rds - voir la page Importation et exportation pour plus de détails).
# Importez la liste de cas
linelist <- import("linelist_cleaned.xlsx")Les 50 premières lignes de la linelist sont affichées ci-dessous.
22.2 Calculer avec slider
Utilisez cette approche pour calculer une moyenne mobile dans un cadre de données avant de tracer.
Le paquet slider fournit plusieurs fonctions de “fenêtre glissante” pour calculer des moyennes glissantes, des sommes cumulatives, des régressions glissantes, etc. Il traite un cadre de données comme un vecteur de lignes, permettant une itération par ligne sur un cadre de données.
Voici quelques-unes des fonctions les plus courantes :
-
slide_dbl()- itère à travers une colonne numérique (“_dbl”) en effectuant une opération utilisant une fenêtre glissante.-
slide_sum()- fonction de raccourci de la somme glissante pourslide_dbl().
-
slide_mean()- fonction de raccourci de la moyenne glissante pourslide_dbl().
-
-
slide_index_dbl()- applique la fenêtre glissante sur une colonne numérique en utilisant une colonne séparée pour indexer la progression de la fenêtre (utile si la fenêtre est glissante par date et que certaines dates sont absentes).-
slide_index_sum()- fonction de raccourci de la somme roulante avec indexation.
-
slide_index_mean()- fonction de raccourci de la moyenne mobile avec indexation.
-
Le paquet slider possède de nombreuses autres fonctions qui sont couvertes dans la section Ressources de cette page. Nous abordons brièvement les plus courantes.
Arguments de base
-
.x, le premier argument par défaut, est le vecteur sur lequel il faut itérer et auquel il faut appliquer la fonction.
-
.i =pour les versions “index” des fonctions slider - fournir une colonne pour “indexer” le rouleau (voir section ci-dessous)
-
.f =, le deuxième argument par défaut, soit :- Une fonction, écrite sans parenthèses, comme
mean, ou bien
- Une formule, qui sera convertie en fonction. Par exemple
~ .x - mean(.x)retournera le résultat de la valeur courante moins la moyenne de la valeur de la fenêtre.
- Une fonction, écrite sans parenthèses, comme
- Pour plus de détails, voir ce matériel de référence
Taille de la fenêtre
Spécifiez la taille de la fenêtre en utilisant soit .before, soit .after, soit les deux arguments :
-
.before =- Fournir un nombre entier
-
.after =- Fournir un nombre entier
-
.complete =- Donnez-lui la valeurTRUEsi vous voulez que le calcul soit effectué uniquement sur des fenêtres complètes.
Par exemple, pour obtenir une fenêtre de 7 jours incluant la valeur actuelle et les six précédentes, utilisez .before = 6. Pour obtenir une fenêtre “centrée”, donnez le même nombre à .before = et .after =.
Par défaut, .complete = sera FAUX, donc si la fenêtre complète de lignes n’existe pas, les fonctions utiliseront les lignes disponibles pour effectuer le calcul. Si vous mettez la valeur TRUE, les calculs ne seront effectués que sur des fenêtres complètes.
Extension de la fenêtre
Pour réaliser des opérations cumulatives, définissez l’argument .before = à Inf. Ceci effectuera l’opération sur la valeur courante et toutes celles qui la précèdent.
Rouler par date
Le cas le plus probable d’utilisation d’un calcul glissant en épidémiologie appliquée est d’examiner une métrique dans le temps. Par exemple, une mesure continue de l’incidence des cas, basée sur le nombre de cas quotidiens.
Si vous avez des séries temporelles propres avec des valeurs pour chaque date, vous pouvez utiliser slide_dbl(), comme démontré ici dans la page Série chronologique et détection des épidémies.
Cependant, dans de nombreuses circonstances d’épidémiologie appliquée, vous pouvez avoir des dates absentes de vos données, où il n’y a aucun événement enregistré. Dans ces cas, il est préférable d’utiliser les versions “index” des fonctions slider.
Données indexées
Ci-dessous, nous montrons un exemple d’utilisation de slide_index_dbl() sur la liste de cas. Disons que notre objectif est de calculer une incidence glissante sur 7 jours - la somme des cas utilisant une fenêtre glissante de 7 jours. Si vous cherchez un exemple de moyenne glissante, consultez la section ci-dessous sur le roulement groupé.
Pour commencer, le jeu de données daily_counts est créé pour refléter le nombre de cas quotidiens de la linelist, tel que calculé avec count() de dplyr.
# créez un jeu de données des comptages quotidiens
daily_counts <- linelist %>%
count(date_hospitalisation, name = "new_cases")Voici le cadre de données daily_counts - il y a nrow(daily_counts) lignes, chaque jour est représenté par une ligne, mais surtout au début de l’épidémie certains jours ne sont pas présents (il n’y avait pas de cas admis ces jours-là).
Il est crucial de reconnaître qu’une fonction de roulement standard (comme slide_dbl() utiliserait une fenêtre de 7 lignes, et non de 7 jours. Ainsi, s’il y a des dates absentes, certaines fenêtres s’étendront en fait sur plus de 7 jours calendaires !
Une fenêtre déroulante “intelligente” peut être obtenue avec slide_index_dbl(). L’“index” signifie que la fonction utilise une colonne séparée comme “index” pour la fenêtre de roulement. La fenêtre n’est pas simplement basée sur les lignes du cadre de données.
Si la colonne d’index est une date, vous avez la possibilité supplémentaire de spécifier l’étendue de la fenêtre à .before = et/ou .after = en unités de lubridate days() ou months(). Si vous faites ces choses, la fonction inclura les jours absents dans les fenêtres comme s’ils étaient là (comme des valeurs NA).
Montrons une comparaison. Ci-dessous, nous calculons l’incidence des cas sur 7 jours glissants avec des fenêtres régulières et indexées.
rolling <- daily_counts %>%
mutate( # créer de nouvelles colonnes
# Utiliser slide_dbl()
###################
reg_7day = slide_dbl(
new_cases, # calculer sur les new_cases
.f = ~sum(.x, na.rm = T), # la fonction est sum() avec les valeurs manquantes supprimées
.before = 6), # la fenêtre est le ROW et 6 ROWS précédents
# Utilisation de slide_index_dbl()
#########################
indexed_7day = slide_index_dbl(
new_cases, # calculer sur les new_cases
.i = date_hospitalisation, # indexé avec date_onset
.f = ~sum(.x, na.rm = TRUE), # la fonction est sum() avec les valeurs manquantes supprimées
.before = days(6)) # la fenêtre est le JOUR et les 6 JOURS précédents
)Observez comment, dans la colonne normale, pour les 7 premières lignes, le nombre augmente régulièrement malgré le fait que les lignes ne sont pas à moins de 7 jours les unes des autres! La colonne adjacente “indexée” tient compte de ces jours calendaires absents, de sorte que ses sommes sur 7 jours sont beaucoup plus faibles, du moins à cette période de l’épidémie où les cas sont plus espacés.
Vous pouvez maintenant tracer ces données avec ggplot() :
ggplot(data = rolling)+
geom_line(mapping = aes(x = date_hospitalisation, y = indexed_7day), size = 1)Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.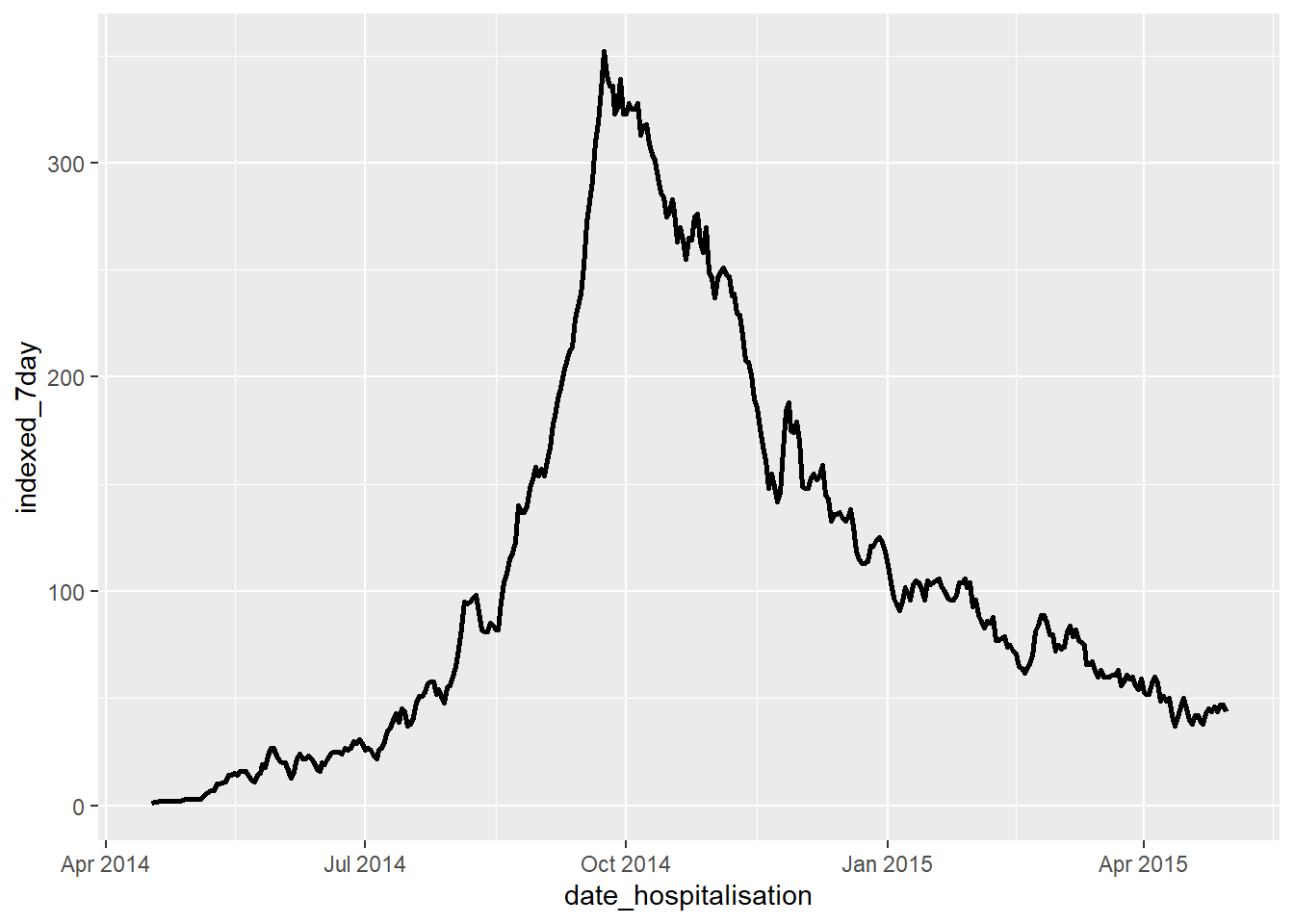
Rouler par groupe
Si vous regroupez vos données avant d’utiliser une fonction slider, les fenêtres de glissement seront appliquées par groupe. Veillez à disposer vos lignes dans l’ordre souhaité par groupe.
Chaque fois qu’un nouveau groupe commence, la fenêtre coulissante recommence. Par conséquent, une nuance à prendre en compte est que si vos données sont groupées et que vous avez défini .complete = TRUE, vous aurez des valeurs vides à chaque transition entre les groupes. Au fur et à mesure que la fonction se déplace vers le bas dans les lignes, chaque transition dans la colonne de regroupement redémarre l’accumulation de la taille minimale de la fenêtre pour permettre un calcul.
Voir la page du manuel sur le Regroupement des données pour plus de détails sur le regroupement des données.
Ci-dessous, nous comptons les cas de la linelist par date et par hôpital. Ensuite, nous classons les lignes par ordre croissant, d’abord par hôpital, puis par date. Ensuite, nous définissons group_by(). Nous pouvons alors créer notre nouvelle moyenne mobile.
grouped_roll <- linelist %>%
count(hospital, date_hospitalisation, name = "new_cases") %>%
arrange(hospital, date_hospitalisation) %>% # arranger les lignes par hôpital puis par date
group_by(hospital) %>% # groupage par hôpital
mutate( # moyenne mobile
mean_7day_hosp = slide_index_dbl(
.x = new_cases, # le nombre de cas par jour d'hospitalisation
.i = date_hospitalisation, # indice sur la date d'admission
.f = mean, # utiliser mean()
.before = days(6) # utilise le jour et les 6 jours précédents
)
)Voici le nouvel ensemble de données :
Nous pouvons maintenant tracer les moyennes mobiles, en affichant les données par groupe en spécifiant ~ hospital à facet_wrap() dans ggplot(). Pour le plaisir, nous traçons deux géométries - un geom_col() montrant le nombre de cas quotidiens et un geom_line() montrant la moyenne mobile sur 7 jours.
ggplot(data = grouped_roll)+
geom_col( # Trace le nombre de cas de daly sous forme de barres grises
mapping = aes(
x = date_hospitalisation,
y = new_cases),
fill = "grey",
width = 1)+
geom_line( # tracer la moyenne mobile sous forme de ligne colorée par hôpital
mapping = aes(
x = date_hospitalisation,
y = mean_7day_hosp,
color = hospital),
size = 1)+
facet_wrap(~hospital, ncol = 2)+ # créer des mini-plots par hôpital
theme_classic()+ # simplifie le fond d'écran
theme(legend.position = "none")+ # supprimer la légende
labs( # ajout d'étiquettes pour les graphiques
title = "7-day rolling average of daily case incidence",
x = "Date of admission",
y = "Case incidence")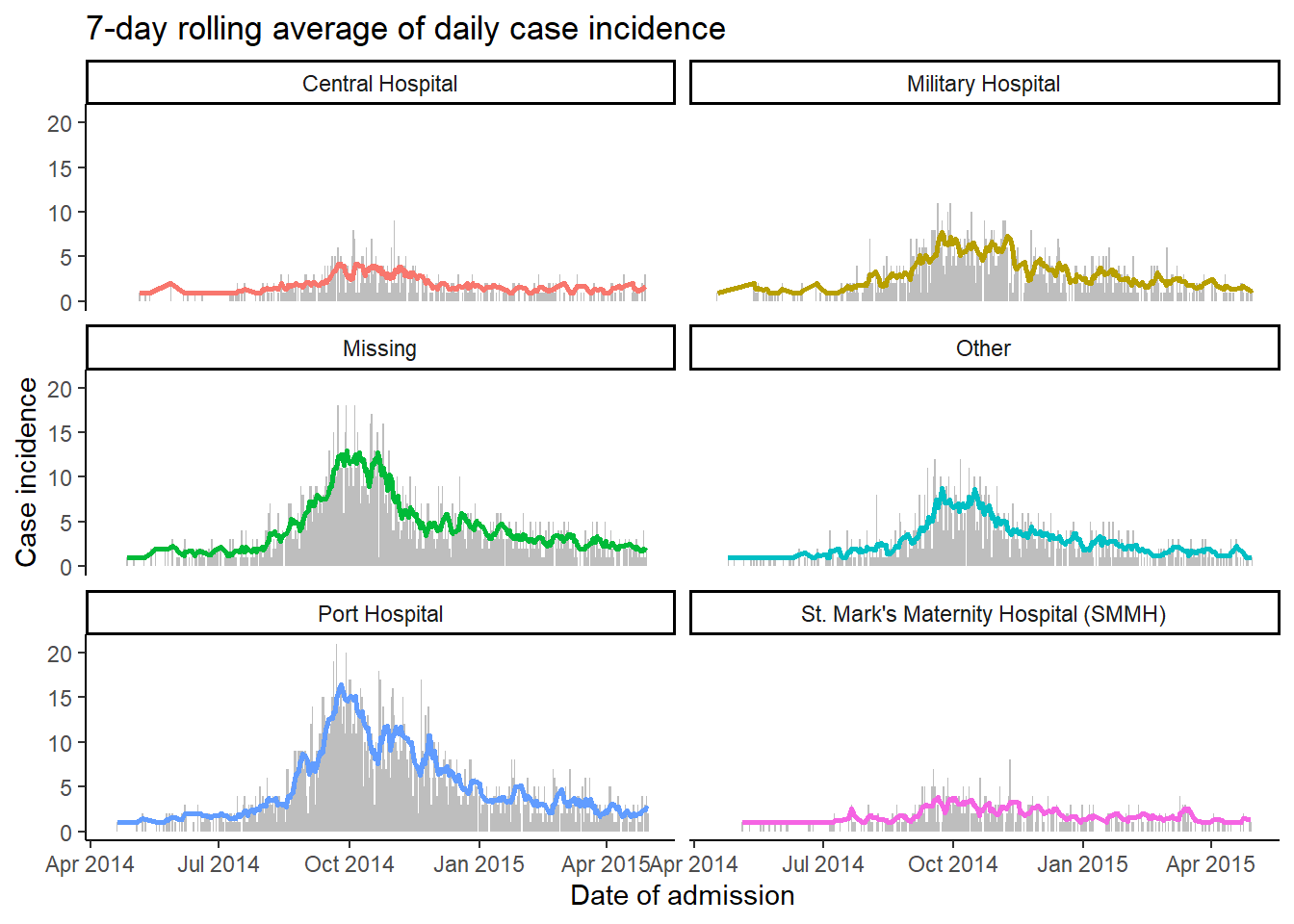
**ATTENTION:_** Si vous obtenez une erreur disant “slide() was deprecated in tsibble 0.9.0 and is now defunct. Please use slider::slide() instead.”, cela signifie que la fonction slide() du paquet tsibble masque la fonction slide() du paquet slider. Corrigez cela en spécifiant le package dans la commande, comme slider::slide_dbl()..
Vous pouvez regrouper les données avant d’utiliser une fonction slider. Par exemple, si vous voulez calculer la même somme glissante de 7 jours que ci-dessus, mais par hôpital. ci-dessus le délai moyen glissant entre l’apparition des symptômes et l’admission à l’hôpital (colonne days_onset_hosp). –>
22.3 Calculer avec tidyquant dans ggplot()
Le paquet tidyquant offre une autre approche du calcul des moyennes mobiles - cette fois-ci à partir dans une commande ggplot() elle-même.
En dessous de la linelist, les données sont comptées par date d’apparition et sont représentées par une ligne fondue (alpha < 1). La ligne superposée est créée avec geom_ma() du paquet tidyquant, avec une fenêtre de 7 jours (n = 7) avec une couleur et une épaisseur spécifiées.
Par défaut, geom_ma() utilise une moyenne mobile simple (ma_fun = "SMA"), mais d’autres types peuvent être spécifiés, tels que :
- “EMA” - moyenne mobile exponentielle (plus de poids aux observations récentes)
- “WMA” - moyenne mobile pondérée (
wtssont utilisés pour pondérer les observations dans la moyenne mobile)
- D’autres peuvent être trouvées dans la documentation de la fonction
linelist %>%
count(date_onset) %>% # compte les cas par jour
drop_na(date_onset) %>% # Suppression des cas pour lesquels la date d'apparition est manquante
ggplot(aes(x = date_onset, y = n))+ # démarrer ggplot
geom_line( # tracer les valeurs brutes
size = 1,
alpha = 0.2 # ligne semi-transparente
)+
tidyquant::geom_ma( # tracer la moyenne mobile
n = 7,
size = 1,
color = "blue")+
theme_minimal() # fond simpleWarning: Using the `size` aesthetic in this geom was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` in the `default_aes` field and elsewhere instead.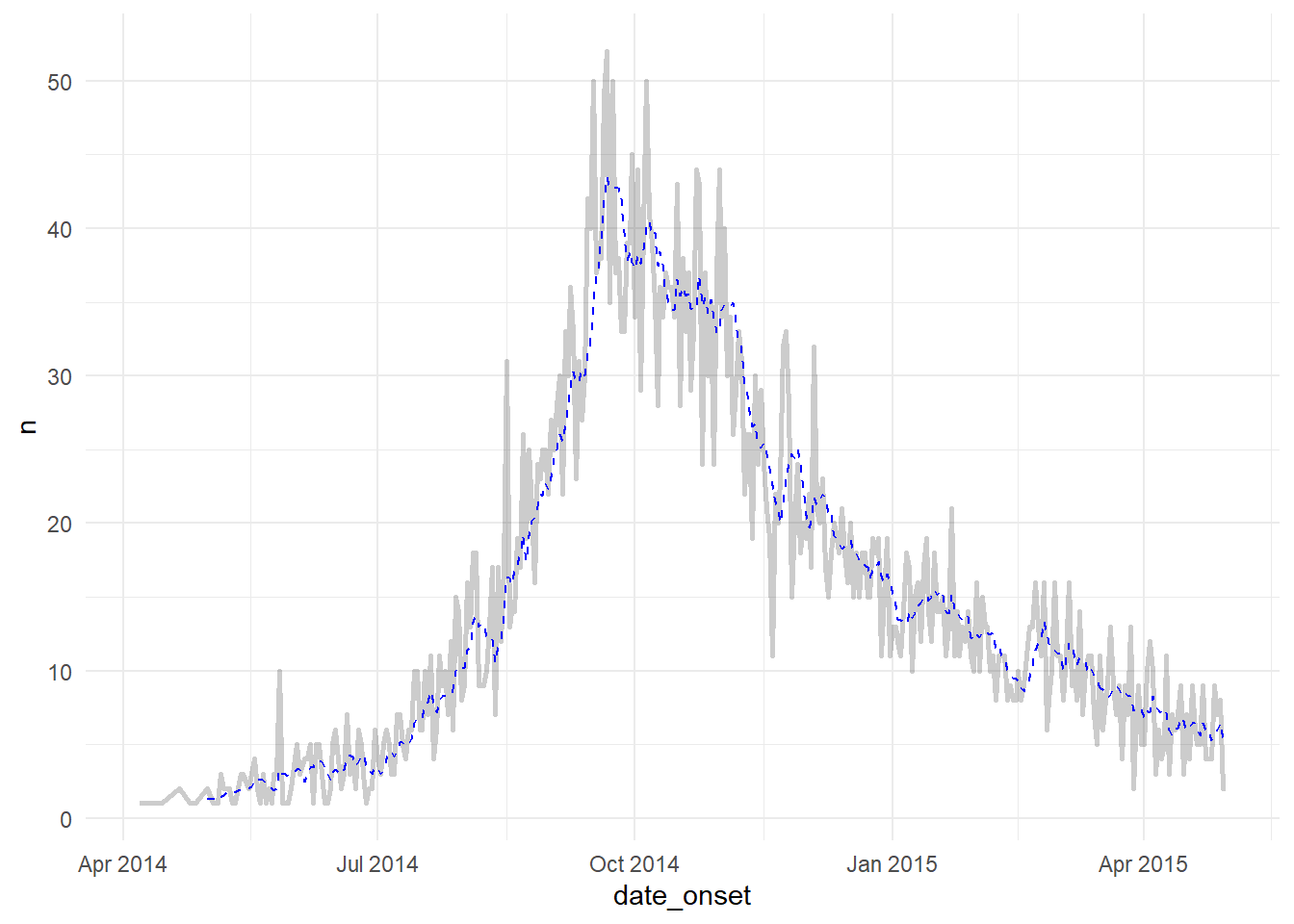
Voir cette vignette pour plus de détails sur les options disponibles dans tidyquant.
22.4 Ressources
Voir la vignette en ligne utile pour le paquet slider.
La page slider github
Une slider vignette
Si votre cas d’utilisation exige que vous “passiez” les week-ends et même les jours fériés, vous aimerez peut-être le paquet almanac.