Warning: package 'purrr' was built under R version 4.3.3
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.0 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
here() starts at C:/Users/ngulu864/AppData/Local/Temp/RtmpQXbGPz/file917c23dd694/epiRhandbook_eng
概要
データに空間情報があることで、アウトブレイクの状況について多くの洞察が得られ、次のような質問に答えることができます。
現在の疾病のホットスポットはどこか?
ホットスポットは時系列でどのように変化しているか?
医療施設へのアクセスはどうなっているか?改善が必要か?
この GIS の章では、疫学業務担当者がアウトブレイク対応において知りたいニーズに応えることを目的としています。ここでは、tmap と ggplot2 パッケージを使って、基本的な空間データの可視化方法を学びます。また、sf パッケージを使用して、基本的な空間データの管理とクエリの方法についても説明します。最後に、spdep パッケージを用いて、空間的関係、空間的自己相関、空間回帰など、空間統計 の概念に簡単に触れます。
重要な用語
ここでは、いくつかの重要な用語を紹介します。GIS と空間分析について詳しく知りたい方は、「リソース」節に掲載されている長いチュートリアルやコースをご覧になることをお勧めします。
GIS(Geographic Information System, 地理情報システム) - GIS とは、空間データを収集、管理、分析、視覚化するためのフレームワークまたは環境のことです。
GIS ソフトウェア
一般的な GIS ソフトウェアの中には、マウス操作で地図の作成や空間分析ができるものがあります。これらのツールには、コードを覚える必要がない、アイコンや機能を手動で選択して地図上に配置するのが簡単であるなどの利点があります。ここでは、人気のある2つのソフトウェアを紹介します。
ArcGIS - ESRI 社が開発した商用の GIS ソフトウェアで、非常に人気がありますますが、かなり高価です。
QGIS - フリーのオープンソース GIS ソフトウェアで、ArcGIS でできることもおおむねできます。ここでQGIS をダウンロードすることができます。
R を GIS として使用することは、「マウス操作」ではなく「コマンドライン・インターフェース」(目的の結果を得るためにはコーディングが必要)であるため、最初は敷居が高く感じられるかもしれません。しかし、繰り返し地図を作成したり、再現性のある分析を行う必要がある場合には、これは大きな利点となります。
空間データ
GIS で使用される空間データには、主にベクトルデータとラスターデータの 2 種類があります。
ベクトルデータ - GIS で使用される空間データの最も一般的な形式です。ベクトルデータは、頂点とパスの幾何学的なフィーチャ (feature; 「地物」とも訳される) で構成されています。ベクトルの空間データは、さらに3つの広く使用されるタイプに分類されます。
点 - 点は、座標系における特定の位置を表す座標ペア(x,y)で構成されます。点は空間データの最も基本的な形態であり、地図上の症例(例:患者の家)や場所(例:病院)を表すのに使用されます。
線 - 線は、2つの接続された点で構成されます。線には長さがあり、道路や川などを表すのに使われます。
ポリゴン - ポリゴンは、点で接続された少なくとも3つの線分で構成されています。ポリゴンのフィーチャは、面積だけでなく、長さ(すなわち、面の外周の長さ)を持っています。ポリゴンは、地域(例:村)や構造(例:病院の実際の面積)を示すときに使用されます。
ラスターデータ - 空間データの代替フォーマットであるラスターデータは、セル(ピクセルなど)のマトリックスで、各セルには高さ、温度、傾斜、森林被覆などの情報が含まれています。これは、航空写真や衛星画像などでよく見られます。ラスターデータは、ベクトルデータの下の「基図」としても使用されます。
空間データの可視化
GIS ソフトウェアでは、空間データを地図上に視覚的に表現するために、それぞれのフィーチャがどこにあるのか、お互いの関係について十分な情報を提供する必要があります。ベクトルデータを使用している場合、ほとんどのユース症例では、この情報は通常シェープファイルに保存されます。
シェープファイル - シェープファイルは、線、点、ポリゴンで構成される「ベクトル」空間データを保存するための一般的なデータフォーマットです。1つのシェープファイルは、実際には少なくとも3つのファイル(.shp、.shx、.dbf)の集合体です。シェープファイルを読み取るためには、これらのサブコンポーネントファイルがすべて同一のディレクトリ(フォルダ)に存在する必要があります。これらの関連ファイルは、ZIPフォルダに圧縮してメールで送信したり、ウェブサイトからダウンロードすることができます。
シェープファイルには、フィーチャ自体の情報だけでなく、地球の表面のどこにあるかという情報も含まれています。空間データをどのように「平面化」するかは、地図の見た目や解釈に大きな影響を与えるため、重要なポイントとなります。
座標参照系 (Coordinate Reference Systems, CRS) - CRS とは、地球上の地理的フィーチャを特定するために使用される座標ベースのシステムです。CRSにはいくつかの重要な要素があります。
座標系 (Coordinate System) - 非常にたくさんの座標系があるため、自分が使用する座標がどの座標系を用いているのかを必ず確認してください。緯度/経度の度数を用いたものは一般的ですが、UTM 座標が利用されていることもあります。
単位 (Units) - 座標系の単位を知ることができます(例:小数点で表された度、メートル)。
測地系 (Datum) - 地球上の特定のモデルの、特定のバージョンを指します。測地系は長年にわたって改訂されてきたので、地図として表示されるレイヤー(マップレイヤー)が同じ測地系を使用していることを確認してください。
投影 (Projection) - 実際には丸い地球を平らな表面(地図)に投影するために使用された数式への参照。
以下に示すマッピングツールを使用しなくても、空間データを要約することができることも覚えておいてください。地域別(例:地区、国など)のシンプルな表があれば十分なこともあります。
訳注: 日本で主に利用されている CRS は次のような ものがあります。
平面直角座標系(世界測地系)I〜XIII EPSG: 2443-2455
JGD2000 GRS80楕円体 EPSG:4612
JGD2011 GRS80楕円体 EPSG:6668 (東日本大震災以降の大規模地殻変動を反映)
はじめての GIS
地図を作るためには、以下の通り、いくつかの重要な要素について、考え、また入手しなければありません。
データセット - これは空間データ形式(上述のようにシェープファイルなど)の場合もあれば、空間形式ではない場合もあります(例えば、単なる csv など)。
データセットが空間フォーマットでない場合は、参照データ も必要です。参照データは、データの空間表現と関連する属性 で構成されており、特定のフィーチャの位置情報やアドレス情報を含む資料などがあります。
事前に定義された地理的境界線(例えば、行政区域)を扱う場合、参照シェープファイルは、政府機関やデータ共有組織から自由にダウンロードできることが多いです。迷ったときは、「[地域名] shapefile」とグーグルで検索してみるとよいでしょう。
住所情報はあっても緯度・経度がないような場合は、 ジオコーディング・エンジン (geocoding engine )を使ってデータの空間参照データを取得する必要があるかもしれません。
データセットの情報を対象者に、どのように見せたいか というアイデア。地図には様々な種類がありますが、どの種類の地図が自分のニーズに最も適しているかを考えることが重要です。
訳注:日本の主なGISデータ: * 国勢調査 * 国土数値地図 * 国土地理院基盤地図 * G空間情報センター
データを可視化するための地図のタイプ
色分け(Choropleth)地図 - 主題図の一種で、色、濃淡、またはパターンを使って、ある属性の値に関連して地理的な地域を表現するもの。例えば、大きな値は小さな値よりも濃い色で示されます。このタイプの地図は、ある変数と、それが定義された地域や地政学的エリアでどのように変化するかを視覚化する場合に特に便利です。
症例密度ヒートマップ - 主題図の一種で、値の強さを色で表しますが、データをグループ化するために定義された地域や地政学的な境界線は使用しません。このタイプの地図は、一般的に「ホットスポット」や、点が高密度または集中しているエリアを示すために使用されます。
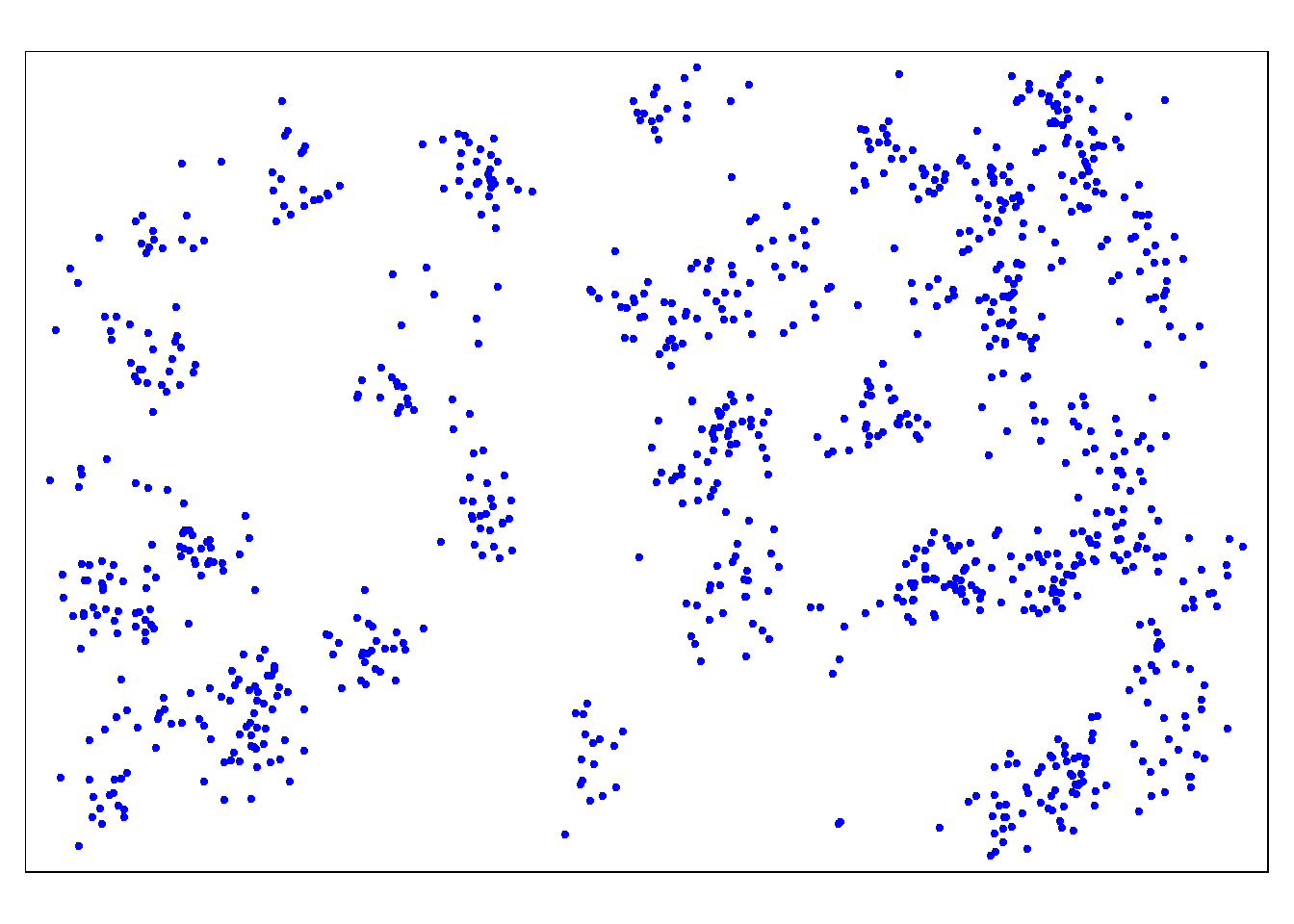
点密度マップ - は、データの属性値をドットで表現する主題図タイプです。このタイプのマップは、データの散らばりを視覚化し、クラスターを視覚的にスキャンするのに適しています。
等級シンボルマップ(段階のあるシンボルマップ) - 色分け地図に似ている主題図ですが、属性の値を色で表すのではなく、その値に対応するシンボル(通常は円)を使用します。例えば、大きな値は小さな値よりも大きなシンボルで示されます。このタイプの地図は、地域ごとのデータの大きさや量を視覚化したい場合に最適です。
また、複数の異なるタイプの視覚化を組み合わせて、複雑な地理的パターンを示すこともできます。例えば、下の地図の症例(点)は、最も近い医療施設に応じて色分けされています(凡例参照)。大きな赤い円は、一定の半径を持つ医療施設のキャッチメントエリア を示し、赤色の症例点は、キャッチメントの範囲外にある症例を示しています。
注:この GIS の章の主な焦点は、現場でのアウトブレイク対応の状況に基づいています。そのため、この章の内容は、基本的な空間データの操作、視覚化、および分析をカバーしています。
準備
パッケージを読み込む
以下のコードを実行すると、分析に必要なパッケージが読み込まれます。このハンドブックでは、パッケージを読み込むために、pacman パッケージの p_load() を主に使用しています。p_load() は、必要に応じてパッケージをインストールし、現在の R セッションで使用するためにパッケージを読み込む関数です。また、すでにインストールされたパッケージは、R の基本パッケージである base (以下、base R)の library() を使用して読み込むこともできます。R のパッケージに関する詳細はR の基礎 の章をご覧ください。
:: p_load (# データをインポート # ファイルの位置を探す # データを処理、プロット (ggplot2 パッケージを含む) # Simple Featureフォーマットによる空間データの管理 # シンプルな地図を作成、インタラクティブな地図と静的な地図の両方に対応 # 列名のクリーニング # ggplot map に OSM 基図を追加 # 空間統計
CRAN “Spatial Task View” では、空間データを扱うすべての R パッケージの概要を見ることができます。
症例データサンプル
ここでは分かりやすくするため、シミュレーションされたエボラ出血熱の linelist データフレームから1000件のランダムなサンプルを使って作業します(計算上、少ない件数で作業すると、このハンドブックでの表示が容易になります)。続いて、「前処理された」ラインリスト(linelist) をクリックしてダウンロードできます(.rdsファイル)。
ここではランダムにサンプルを取っているので、実際にコードを実行してみると、ここに表示されている結果とは若干異なる結果になるかもしれません。
データを rio パッケージの import() を使ってインポートします(rio パッケージは、.xlsx、.csv、.rds など様々な種類のファイルを扱えるパッケージです。詳細はデータのインポート・エクスポート の章を参照してください)。
# import clean case linelist <- import ("linelist_cleaned.rds" )
次に、base R の sample() を使って 1000 行のランダムなサンプルを抽出します。
# ラインリストの行数から1000個のランダムな行番号を生成 <- sample (nrow (linelist), 1000 )# サンプル行の全ての列だけを保持するラインリストにサブセットする <- linelist[sample_rows,]
そして、データフレーム型である linelist を “sf”(空間フィーチャ)型のオブジェクトに変換していきます。この ラインリストには、各症例の居住地の経度と緯度を表す “lon” と “lat” の2つの列があるので、これは簡単です。
ここでは、sf (空間的フィーチャ)パッケージとその関数、 st_as_sf() を使用して、linelist_sf という新しいオブジェクトを作成します。この新しいオブジェクトは、基本的には linelist と同じですが、列 lon と lat を座標列として指定し、点を表示する際の座標参照系 (CRS) を割り当てています。4326では、GPS座標の標準である World Geodetic System 1984 (WGS84) に基づいた座標が指定されています。
# sfオブジェクトを生成 <- linelist %>% :: st_as_sf (coords = c ("lon" , "lat" ), crs = 4326 )
これがオリジナルの linelist データフレームの中身です。このデモでは、date_onset と geometry(上記の経度と緯度のフィールドから作成されたもので、データフレームの最後の列)の列のみを使用します。
:: datatable (head (linelist_sf, 10 ), rownames = FALSE , options = list (pageLength = 5 , scrollX= T), class = 'white-space: nowrap' )
行政境界シェープファイル
シエラレオネ (Sierra Leone): 行政境界シェープファイル
事前に、Humanitarian Data Exchange (HDX) ウェブサイト からシエラレオネのすべての行政(admin)境界データをダウンロードしておきました。あるいは、ハンドブックとデータのダウンロード の章で説明しているように、私たちの R パッケージを介して、このデータやその他のサンプルデータをダウンロードすることもできます。
では、いよいよ Admin Level 3 のシェープファイルを R に保存するために、以下の作業を行います。
シェープファイルをインポートする
列名を加工する
興味のある地域だけを残すために行を抽出する
シェープファイルをインポートするには、sf パッケージの read_sf() を使います。ファイルのパスは here() で与えられます。- 今回の場合、ファイルはRプロジェクトの “data”、“gis”、“shp” というサブフォルダに “sle_adm3.shp” として格納されています(詳細は データのインポート・エクスポート と R プロジェクトの設定 の章を参照してください)。独自のファイルパスを設定してください。
次に、janitor パッケージの clean_names() を使って、シェープファイルの列名を標準化します。また、filter() を使って、admin2name が “Western Area Urban” または “Western Area Rural” の行だけを残します。
# ADM3 level clean <- sle_adm3_raw %>% :: clean_names () %>% # 列名の標準化 :: filter (admin2name %in% c ("Western Area Urban" , "Western Area Rural" )) # 特定の地域を残してフィルター
下の表は、インポートし、クリーニングした後のシェープファイルの様子です。右側にスクロールして、admin レベル 0(国)、admin レベル 1、admin レベル 2、そして最後に admin レベル 3 の列があることがわかります。それぞれのレベルには、キャラクター名と固有の識別子 “pcode” があります。たとえば、SL(Sierra Leone) → 04(Western) → L0410(Western Area Rural)→ L0040101(Koya Rural)のように、pcode は admin レベルが上がるごとに拡張されます。
人口データ
シエラレオネ: ADM3 ごとの人口
これらのデータは、HDX からダウンロードすることもできますし(リンクはこちら )、この章ハンドブックとデータのダウンロード で説明しているように、epirhandbook パッケージを介してダウンロードすることもできます。.csv ファイルの読み込みには、import() を使用します。また、インポートしたファイルを clean_names() に渡して列名の構文を標準化します。
# ADM3 ごとの人口 <- import (here ("data" , "gis" , "population" , "sle_admpop_adm3_2020.csv" )) %>% :: clean_names ()
人口ファイルはこのようになっています。右にスクロールすると、各行政区域に male、female、total の列があり、さらに年齢層別の列に人口の内訳が表示されています。
医療施設
シエラレオネ: OpenStreetMap からの医療施設
今回も HDX から医療施設の位置情報をダウンロードしました。こちら または ハンドブックとデータのダウンロード の章の指示に従ってください。
施設の位置を示す点のシェープファイルを read_sf() でインポートし、列名をクリーニングしてから、病院(“hospital”)、診療所(“clinic”)、医師(“doctor”) のいずれかのタグが付けられた点だけを残すように抽出しました。
# OSM 医療施設の shapefile <- sf:: read_sf (here ("data" , "gis" , "shp" , "sle_hf.shp" )) %>% :: clean_names () %>% :: filter (amenity %in% c ("hospital" , "clinic" , "doctors" ))
右にスクロールする と、施設名と geometry 座標が表示されます。
座標のプロット
X-Y座標(経度・緯度で表される点)をプロットする最も簡単な方法は、今回の場合、準備編で作成した linelist_sf オブジェクトから直接、点として描画することです。
tmap パッケージ は、わずか数行のコードで、静的(“plot” モード)とインタラクティブ(“view” モード)の両方に対応したシンプルなマッピング機能を提供します。tmap パッケージ の構文は ggplot2 パッケージ と似ていて、コマンド同士を + で追加していきます。詳しくはこの vignette をご覧ください。
tmap モードを設定。ここでは plot モードを使い、静的なアウトプットを作成します。
tmap_mode ("plot" ) # "view" または "plot" を選択
以下では、点を単独でプロットしています。tm_shape() は、linelist_sf オブジェクトとともに提供されます。次に、tm_dots() でサイズと色を指定して点を追加します。linelist_sf は sf オブジェクトなので、緯度・経度座標と座標系(CRS)を格納する2つの列はすでに指定されています。
# 症例(点)のみ tm_shape (linelist_sf) + tm_dots (size= 0.08 , col= 'blue' )
点だけでは、あまり意味がありません。そこで、行政境界もマッピングする必要があります。
ここでも tm_shape() を使いますが(documentation 参照)、症例の点のシェープファイルを提供する代わりに、行政境界のシェープファイル(ポリゴン)を提供します。
bbox = の引数(bbox は “bounding box” の略)で、座標の境界を指定することができます。まず bbox なしの地図表示を行い、次に bbox ありの地図表示を行います。
# 行政境界(ポリゴン)のみ tm_shape (sle_adm3) + # 行政境界のシェープファイル tm_polygons (col = "#F7F7F7" )+ # ポリゴンを薄い灰色で表示 tm_borders (col = "#000000" , # 境界を色と線の太さで表示 lwd = 2 ) + tm_text ("admin3name" ) # 各ポリゴンについて表示する列テキスト # 上と同様、ただしバウンディングボックス引数から縮尺を指定 tm_shape (sle_adm3,bbox = c (- 13.3 , 8.43 , # 角 - 13.2 , 8.5 )) + # 角 tm_polygons (col = "#F7F7F7" ) + tm_borders (col = "#000000" , lwd = 2 ) + tm_text ("admin3name" )
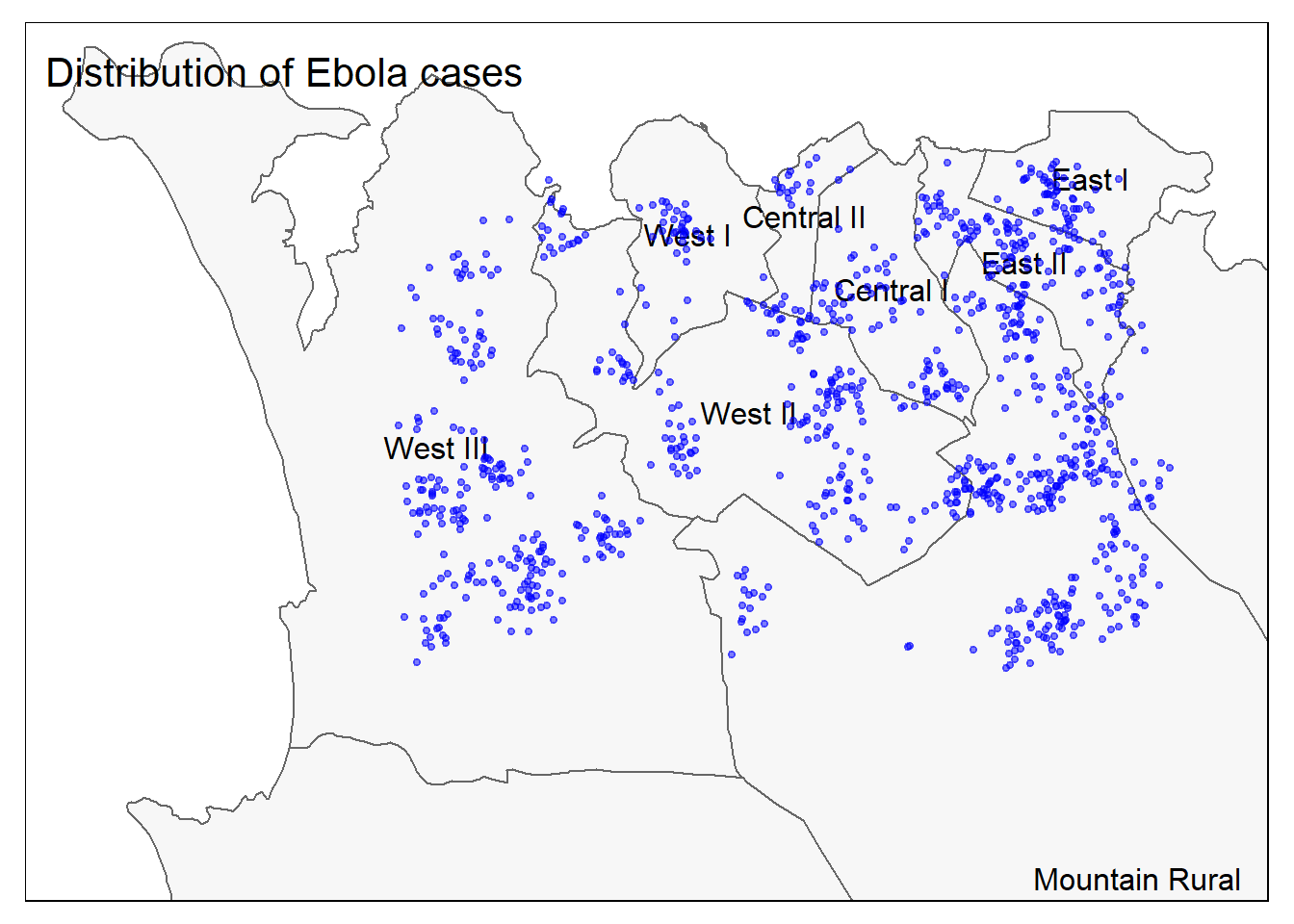
そして、今度は点とポリゴンの両方を一緒に表示します。
# すべてまとめる tm_shape (sle_adm3, bbox = c (- 13.3 , 8.43 , - 13.2 , 8.5 )) + # tm_polygons (col = "#F7F7F7" ) + tm_borders (col = "#000000" , lwd = 2 ) + tm_text ("admin3name" )+ tm_shape (linelist_sf) + tm_dots (size= 0.08 , col= 'blue' , alpha = 0.5 ) + tm_layout (title = "Distribution of Ebola cases" ) # 地図にタイトルを付ける
R でのマッピングオプションの比較については、こちらの ブログ記事 をご覧ください。
空間結合
データセットと別のデータセットを 結合 することについては知っているでしょう。いくつかの方法は、このハンドブックのデータの結合 の章で説明しています。空間結合は、同様の目的を持ちますが、空間的な関係を利用します。観測値を正しく一致させるために列の共通の値に頼るのではなく、あるフィーチャが他のフィーチャの中に入っているとか、他のフィーチャに最近傍 であるとか、他のフィーチャから一定の半径のバッファ 内にあるなど、空間的な関係を利用することができます。
sf パッケージには、空間結合のための様々なメソッドが用意されています。st_join メソッドや空間結合の種類については、こちらの参考資料 に詳しい説明があります。
ポリゴン内の点
症例に行政単位を空間割当て
ここで興味深い問題があります。症例のラインリストには、症例の admin 単位に関する情報が含まれていません。このような情報は、最初のデータ収集段階で収集するのが理想的ですが、空間的な関係(つまり、点がポリゴンと交差する)に基づいて、個々の症例に admin 単位を割り当てることもできます。
以下では、症例の位置(点)と ADM3 の境界(ポリゴン)を空間的に交差させます。
linelist(点)から始める
結合のタイプを “st_intersects” に設定して、境界線に空間的に結合する
select() を使用して、新しい行政境界列のうち特定のものだけを残す
<- linelist_sf %>% # 空間交差に基づいて行政境界を linelist に結合 :: st_join (sle_adm3, join = st_intersects)
sle_adms のすべての列がラインリストに追加されました!各症例には、該当する行政区域レベルの詳細を示す列が追加されました。この例では、新しい列のうち 2 つ(admin レベル3)だけを残したいので、古い列名を select() して、追加したい2つだけを選択します。
<- linelist_sf %>% # 空間交差に基づいて、行政境界ファイルをラインリストに結合 :: st_join (sle_adm3, join = st_intersects) %>% # 古い列名はそのままに、新たに2つの admin の列名を追加 select (names (linelist_sf), admin3name, admin3pcod)
下の図は、最初の10件と、ポリゴン図形と空間的に交差する点に基づいて付けられた admin レベル3(ADM3)の行政境界を表示しています。
# これで、各症例に ADM3 名がついたことが確認できます。 %>% select (case_id, admin3name, admin3pcod)
Simple feature collection with 1000 features and 3 fields
Geometry type: POINT
Dimension: XY
Bounding box: xmin: -13.27082 ymin: 8.447887 xmax: -13.20613 ymax: 8.490183
Geodetic CRS: WGS 84
First 10 features:
case_id admin3name admin3pcod geometry
5115 7c6980 West III SL040208 POINT (-13.2542 8.46062)
1445 f36729 East I SL040203 POINT (-13.21813 8.488549)
2176 ae7509 West III SL040208 POINT (-13.26777 8.469171)
4564 ea0bce Mountain Rural SL040102 POINT (-13.24133 8.452799)
1117 659025 West I SL040206 POINT (-13.24585 8.484111)
4209 986e99 West II SL040207 POINT (-13.23599 8.472323)
1254 7cb7a0 West III SL040208 POINT (-13.26215 8.464815)
5506 9b3ec6 Mountain Rural SL040102 POINT (-13.21181 8.464505)
4943 31b710 Mountain Rural SL040102 POINT (-13.22187 8.478279)
1549 2965bd West II SL040207 POINT (-13.23606 8.459655)
空間結合の前にはできなかった、行政単位での症例の表現が可能になりました。
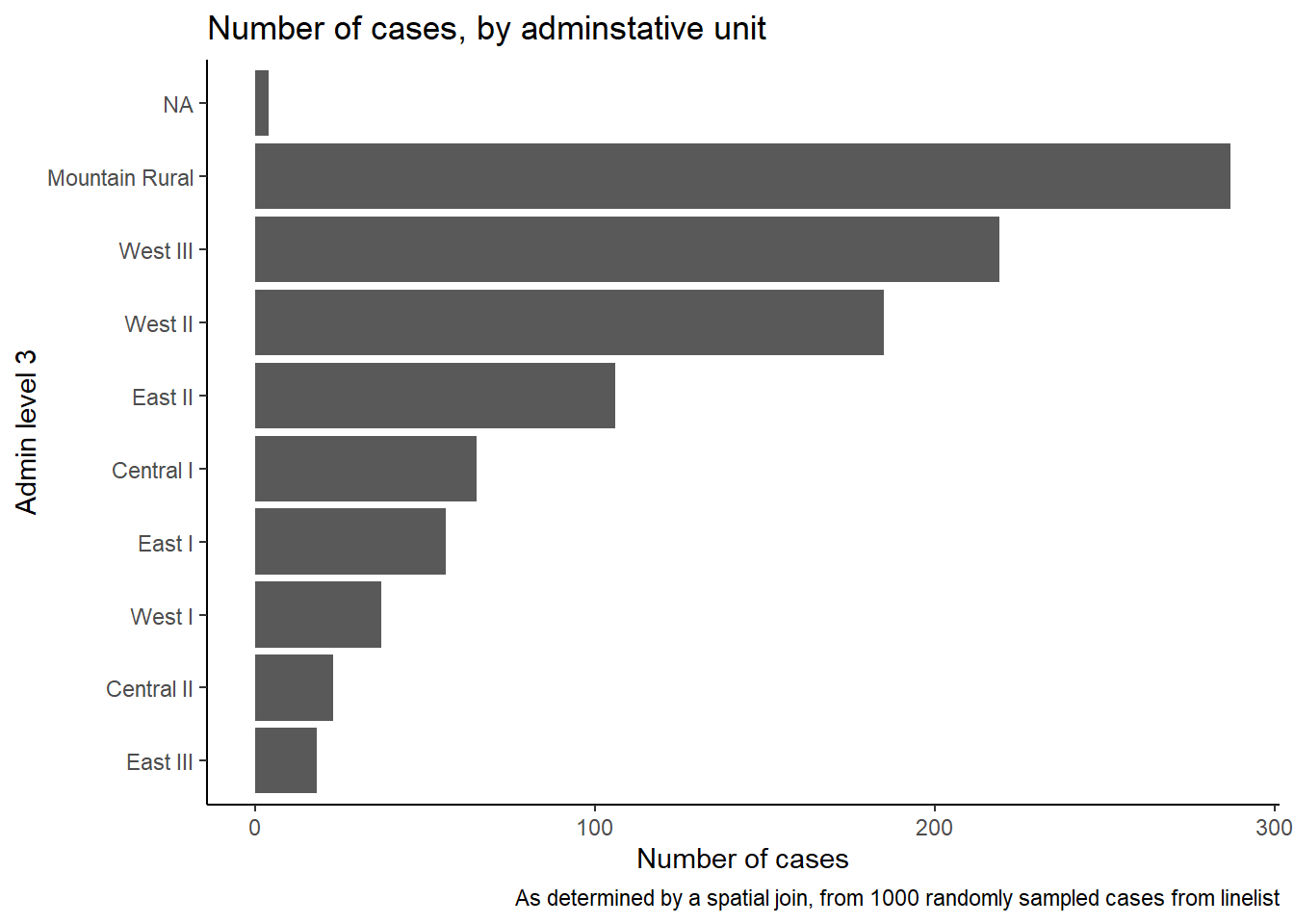
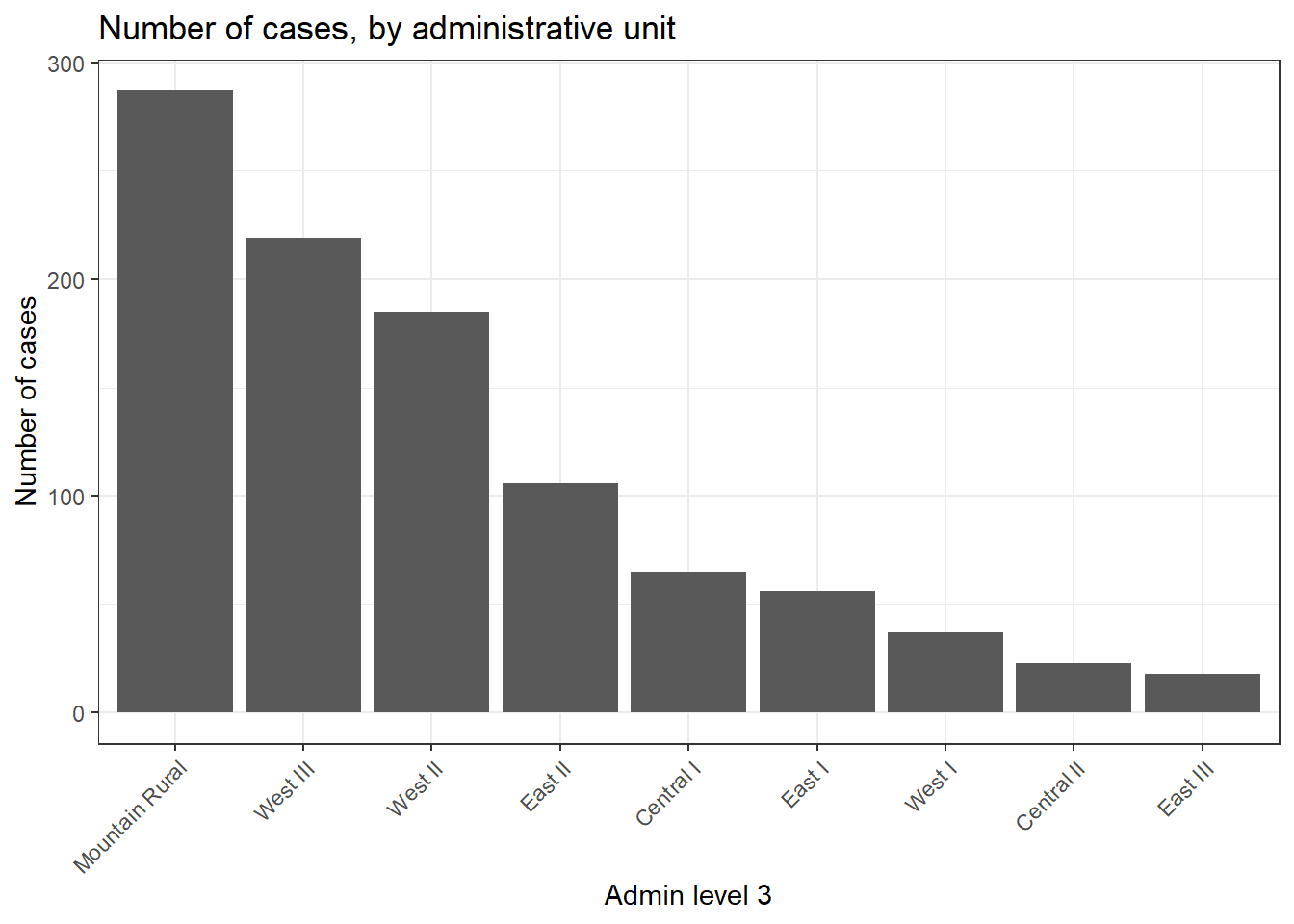
# 行政単位ごとに症例の数を含むデータフレームを新規作成 <- linelist_adm %>% # 新しい admin 列を含むラインリストで始める as_tibble () %>% # 見やすいように tibble に変換 group_by (admin3pcod, admin3name) %>% # 名前と pcode で行政単位をグループ化 summarise (cases = n ()) %>% # 要約と行数のカウント arrange (desc (cases)) # 下り順に並べ替え
# A tibble: 10 × 3
# Groups: admin3pcod [10]
admin3pcod admin3name cases
<chr> <chr> <int>
1 SL040102 Mountain Rural 287
2 SL040208 West III 219
3 SL040207 West II 185
4 SL040204 East II 106
5 SL040201 Central I 65
6 SL040203 East I 56
7 SL040206 West I 37
8 SL040202 Central II 23
9 SL040205 East III 18
10 <NA> <NA> 4
また、行政単位ごとの症例数の棒グラフを作成することもできます。
この例では、ggplot() を linelist_adm で始めているので、頻度で棒グラフを並べる fct_infreq() などの因子型のための関数を適用することができます(ヒントは 因子(ファクタ)型データ の章を参照してください)。
ggplot (data = linelist_adm, # admin unit 情報を含むラインリストで始める mapping = aes (x = fct_rev (fct_infreq (admin3name))))+ # x軸は行政単位、件数で並べ替え geom_bar ()+ # 帽を作成、高さは行数 coord_flip ()+ # adm を読みやすくするためにXとYを入れ替える theme_classic ()+ # 背景を単純に labs ( # タイトルとラベル x = "Admin level 3" ,y = "Number of cases" ,title = "Number of cases, by adminstative unit" ,caption = "As determined by a spatial join, from 1000 randomly sampled cases from linelist"
最近傍
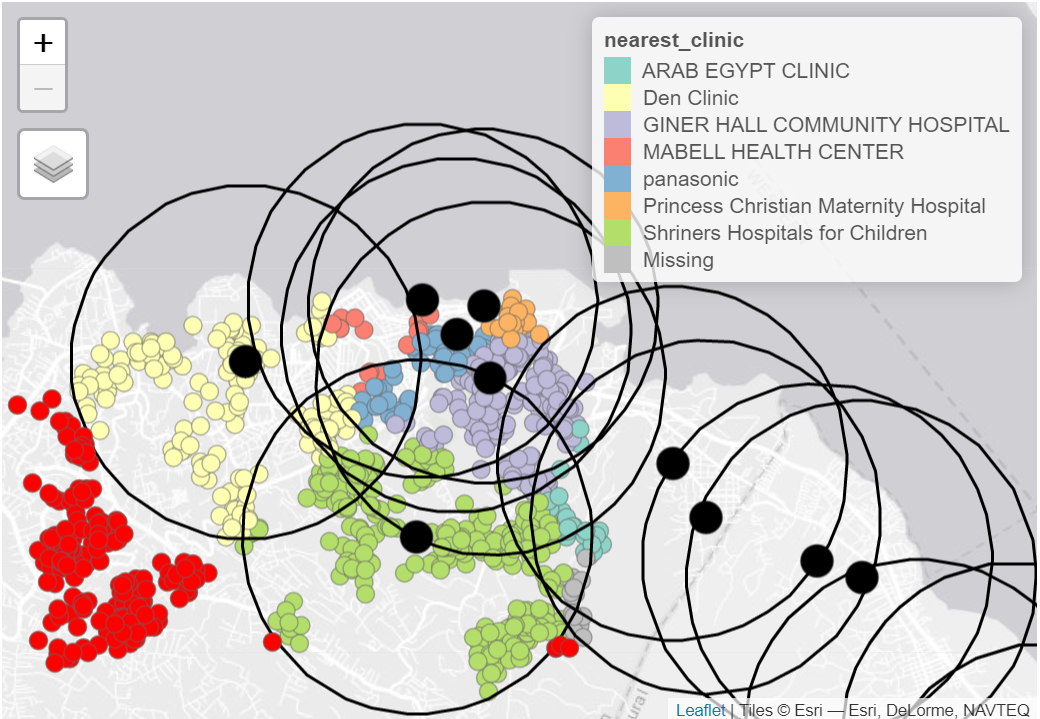
最寄の医療施設/集客エリアを探す
病気のホットスポットに関連して、医療施設がどこにあるかを知っておくと便利かもしれません。
ここでは、st_join() (sf パッケージ)の st_nearest_feature 結合メソッドを使って、個々の症例に最も近い医療施設を可視化することができます。
まず、シェープファイルのラインリスト linelist_sf を用意します。
保健施設や診療所の位置(点)である sle_hf と空間的に結合します。
# 各症例に最も近い医療施設 <- linelist_sf %>% # linelist shapefile で始める st_join (sle_hf, join = st_nearest_feature) %>% # 症例データから最も近い診療所からのデータ select (case_id, osm_id, name, amenity) %>% # 残しておくべき列、例えば id, name, type, と医療施設の位置情報 rename ("nearest_clinic" = "name" ) # 分かりやすいように名前を変更
以下(最初の50行)のように、それぞれの症例には最寄りの診療所や病院のデータがあることがわかります。
約30%の症例で “Den Clinic” が最も近い医療機関であることがわかります。
# 医療施設ごとに症例を数える <- linelist_sf_hf %>% # 最寄りの診療所データを含むラインリストで始める as.data.frame () %>% # shapefile をデータフレームに変換 count (nearest_clinic, # (診療所の)"name" で行を数える name = "case_n" ) %>% # 数えたデータの列に "case_n" と命名 arrange (desc (case_n)) # 下がり順で並べ替え # console に表示
nearest_clinic case_n
1 Den Clinic 362
2 Shriners Hospitals for Children 343
3 GINER HALL COMMUNITY HOSPITAL 161
4 panasonic 51
5 Princess Christian Maternity Hospital 33
6 ARAB EGYPT CLINIC 22
7 <NA> 15
8 MABELL HEALTH CENTER 13
結果を可視化するために、tmap パッケージ を使用することができます。
tmap_mode ("view" ) # tmap モードをインタラクティブに設定 # 症例と診療所の点をプロット tm_shape (linelist_sf_hf) + # 症例をプロット tm_dots (size= 0.08 , # 最も近い診療所で症例を色分け col= 'nearest_clinic' ) + tm_shape (sle_hf) + # 診療所を大きい黒い点でプロット tm_dots (size= 0.3 , col= 'black' , alpha = 0.4 ) + tm_text ("name" ) + # 施設名でオーバーレイ tm_view (set.view = c (- 13.2284 , 8.4699 , 13 ), # 縮尺を調整 (中心座標, zoom) set.zoom.limits = c (13 ,14 ))+ tm_layout (title = "Cases, colored by nearest clinic" )
バッファ
また、最も近い医療施設から徒歩2.5km(約30分)以内にある症例がどれくらいあるかを調べることもできます。
注: より正確な距離を計算するためには、UTM(地球を平面に投影したもの)などの各地域の地図投影系に sf オブジェクトを再投影するのがよいでしょう。この例では、簡単にするために、世界測地系(WGS84)の地理的座標系(地球は球状/円形の表面で表現され、そのため単位は10進法の度数)にしておきます。ここでは、一般的な換算として、1度=約111kmとします。
地図投影法と座標系については、こちらのesriの記事 をご覧ください。こちらのブログ では、様々なタイプの地図投影について、また、興味のある分野や地図・分析の文脈に応じて、どのように適切な投影を選ぶことができるかについて述べられています。
まず 、各医療施設の周囲に半径約2.5kmの円形バッファを作成します。これは tmap パッケージ の st_buffer() で行います。地図の単位は緯度・経度の10進法であるため、“0.02” は度数として解釈されます。地図の座標系がメートル単位の場合は、数値もメートル単位で指定する必要があります。
<- sle_hf %>% st_buffer (dist= 0.02 ) # 約2.5kmに度数を変換
以下のように、バッファゾーン自体を作ります:
tmap_mode ("plot" )# 円バッファを作成 tm_shape (sle_hf_2k) + tm_borders (col = "black" , lwd = 2 )+ tm_shape (sle_hf) + # 診療所を大きい赤丸でプロット tm_dots (size= 0.3 , col= 'black' )
次に 、st_join() の st_intersects 結合タイプを使って、これらのバッファと症例(点)を交差させます。
# バッファで症例を交差 <- linelist_sf_hf %>% st_join (sle_hf_2k, join = st_intersects, left = TRUE ) %>% filter (osm_id.x== osm_id.y | is.na (osm_id.y)) %>% select (case_id, osm_id.x, nearest_clinic, amenity.x, osm_id.y)
これによって結果を数えることができます。1000件のうち1000件は、どのバッファとも交差していない(値が欠けている)ので、最寄りの医療施設から徒歩30分以上の場所に住んでいることになります。
# どの医療施設バッファとも交差しなかった症例 %>% filter (is.na (osm_id.y)) %>% nrow ()
その結果、どのバッファとも交わらなかった症例が赤で表示されるように可視化されます。
tmap_mode ("view" )# まず症例を点で表示 tm_shape (linelist_sf_hf) + tm_dots (size= 0.08 , col= 'nearest_clinic' ) + # 診療所を大きい黒点でプロット tm_shape (sle_hf) + tm_dots (size= 0.3 , col= 'black' )+ # 医療施設バッファをポリラインで重ねる tm_shape (sle_hf_2k) + tm_borders (col = "black" , lwd = 2 ) + # どの医療施設バッファにもない症例を赤点で強調 tm_shape (linelist_sf_hf_2k %>% filter (is.na (osm_id.y))) + tm_dots (size= 0.1 , col= 'red' ) + tm_view (set.view = c (- 13.2284 ,8.4699 , 13 ), set.zoom.limits = c (13 ,14 ))+ # タイトルを追加 tm_layout (title = "Cases by clinic catchment area" )
他の空間結合
joinの引数は、このほかに以下の値をとります。 (ドキュメント より)
st_contains_properly
st_contains
st_covered_by
st_covers
st_crosses
st_disjoint
st_equals_exact
st_equals
st_is_within_distance
st_nearest_feature
st_overlaps
st_touches
st_within
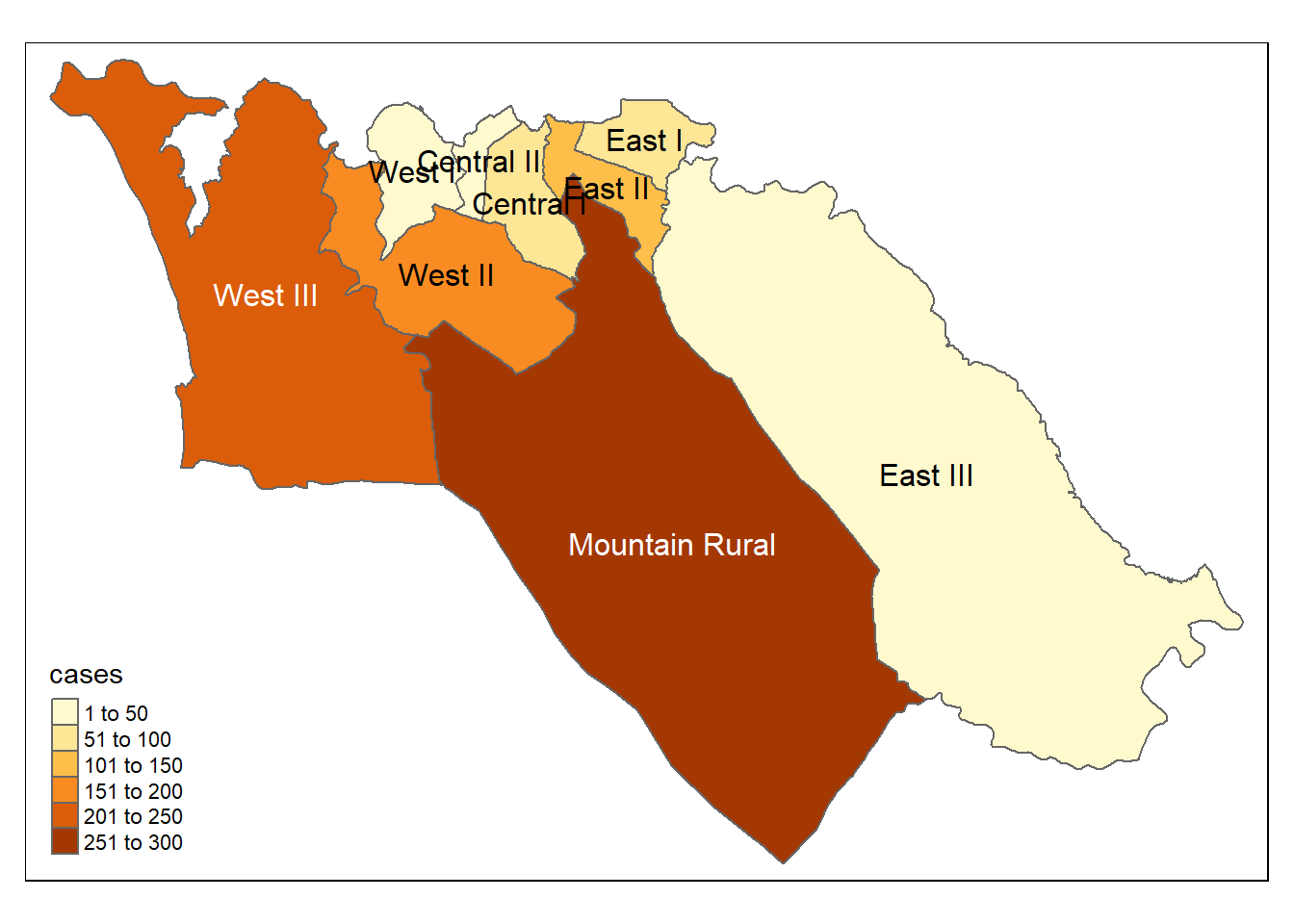
色分け(Choropleth)地図
色分け地図は、あらかじめ定義されたエリア(通常は行政単位や保健エリア)ごとにデータを視覚化するのに役立ちます。例えば、感染発生対応では、発生率の高い特定の地域にリソースを割り当てる際に役立ちます。
すべての症例に行政単位名が割り当てられたので(上記の「空間結合」のセクションを参照)、症例数をエリア別にマッピングすることができます(色分け地図)。
ADM3 ごとの人口データもあるので、この情報を先に作成した case_adm3 テーブルに追加することができます。
まず、前のステップで作成したデータフレーム case_adm3 から始めます。これは、各行政単位とその症例数の要約表です。
人口データ sle_adm3_pop は、dplyr パッケージ の left_join() を用いて、case_adm3 データフレームの admin3pcod 列と sle_adm3_pop データフレームの adm_pcode 列に共通する値に基づいて結合されています。データの結合 の章を参照)。
select() を新しいデータフレームに適用して、有用な列だけを残す - total は総人口です。
mutate() を用いて、人口 10,000 人あたりの症例数を新しい列として計算します。
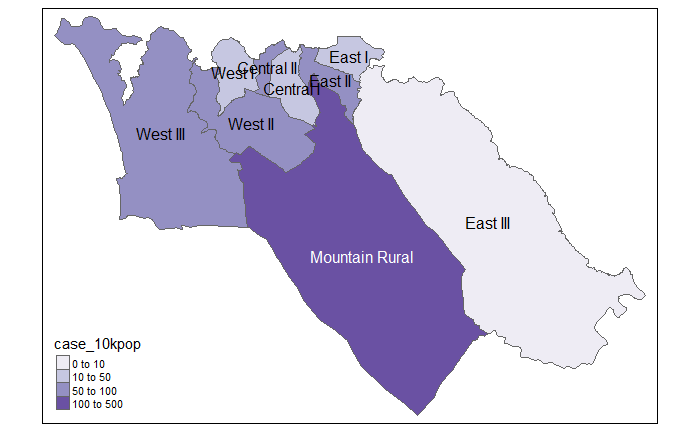
# 人口データを追加し、1万人当たりの症例数を計算 <- case_adm3 %>% left_join (sle_adm3_pop, # 人口データから列を追加 by = c ("admin3pcod" = "adm3_pcode" )) %>% # 二つの列の共通の値に基づく結合 select (names (case_adm3), total) %>% # 重要な列のみ保持、総人口など mutate (case_10kpop = round (cases/ total * 10000 , 3 )) # 10000あたりの症例数の列を作成、小数点以下3桁で四捨五入 # console に表示
# A tibble: 10 × 5
# Groups: admin3pcod [10]
admin3pcod admin3name cases total case_10kpop
<chr> <chr> <int> <int> <dbl>
1 SL040102 Mountain Rural 287 33993 84.4
2 SL040208 West III 219 210252 10.4
3 SL040207 West II 185 145109 12.7
4 SL040204 East II 106 99821 10.6
5 SL040201 Central I 65 69683 9.33
6 SL040203 East I 56 68284 8.20
7 SL040206 West I 37 60186 6.15
8 SL040202 Central II 23 23874 9.63
9 SL040205 East III 18 500134 0.36
10 <NA> <NA> 4 NA NA
このテーブルを ADM3 のポリゴンシェープファイル と結合してマッピングします。
<- case_adm3 %>% # 行政単位での症例と感染率で始める left_join (sle_adm3, by= "admin3pcod" ) %>% # shapefile データと共通列で結合 select (objectid, admin3pcod, # 指定した列のみ保持 admin3name = admin3name.x, # 一つの列名をきれいにする %>% # プロットできるように座標を保持 drop_na (objectid) %>% # NA 行を取り除く st_as_sf () # shapefile に変換
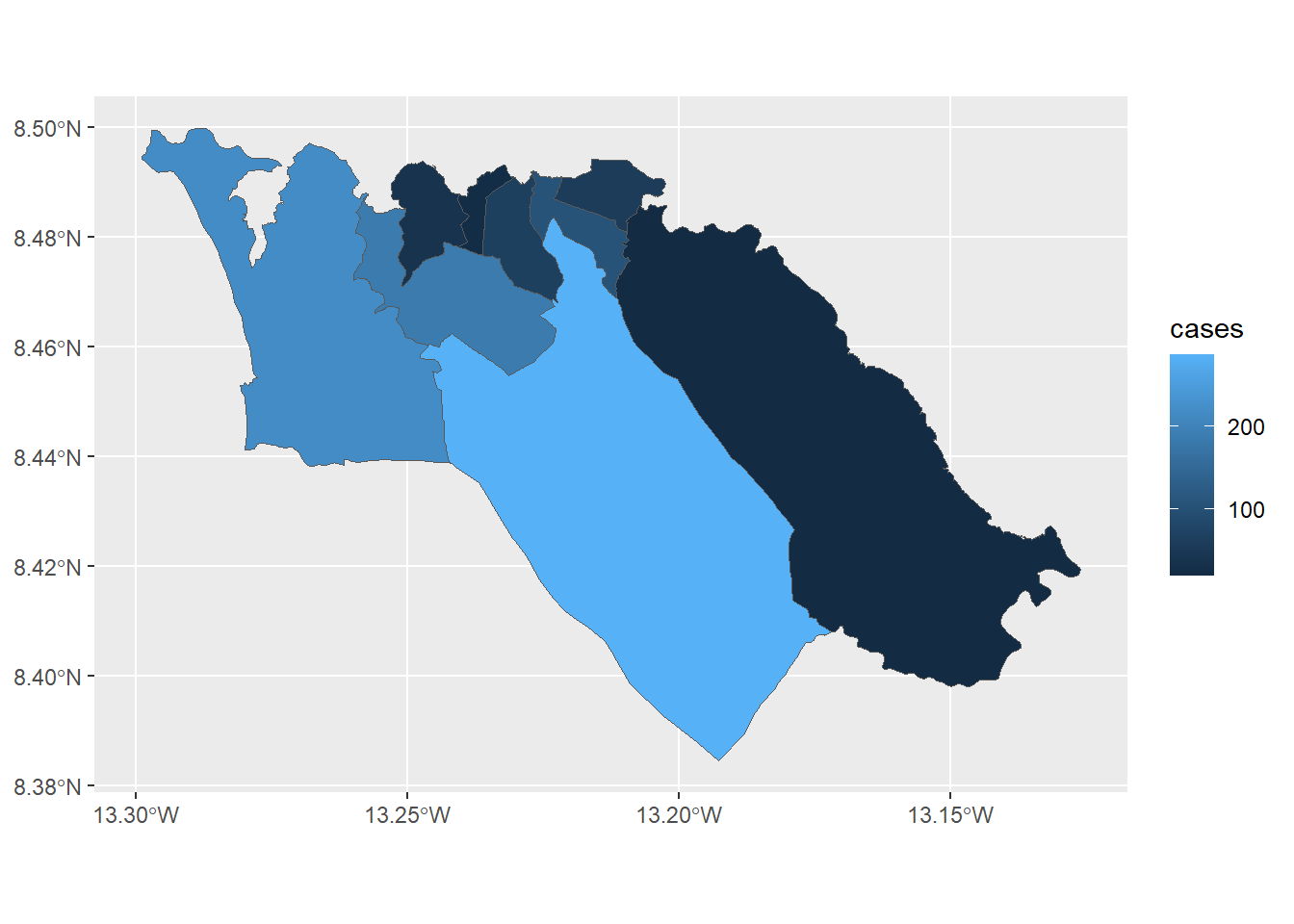
結果をマッピング。
<- na.omit (case_adm3_sf)# tmap mode tmap_mode ("plot" ) # 静的地図を表示 # ポリゴンをプロット tm_shape (case_adm3_sf) + tm_polygons ("cases" ) + # 症例数の列で色分け tm_text ("admin3name" ) # 表示に名前を付ける
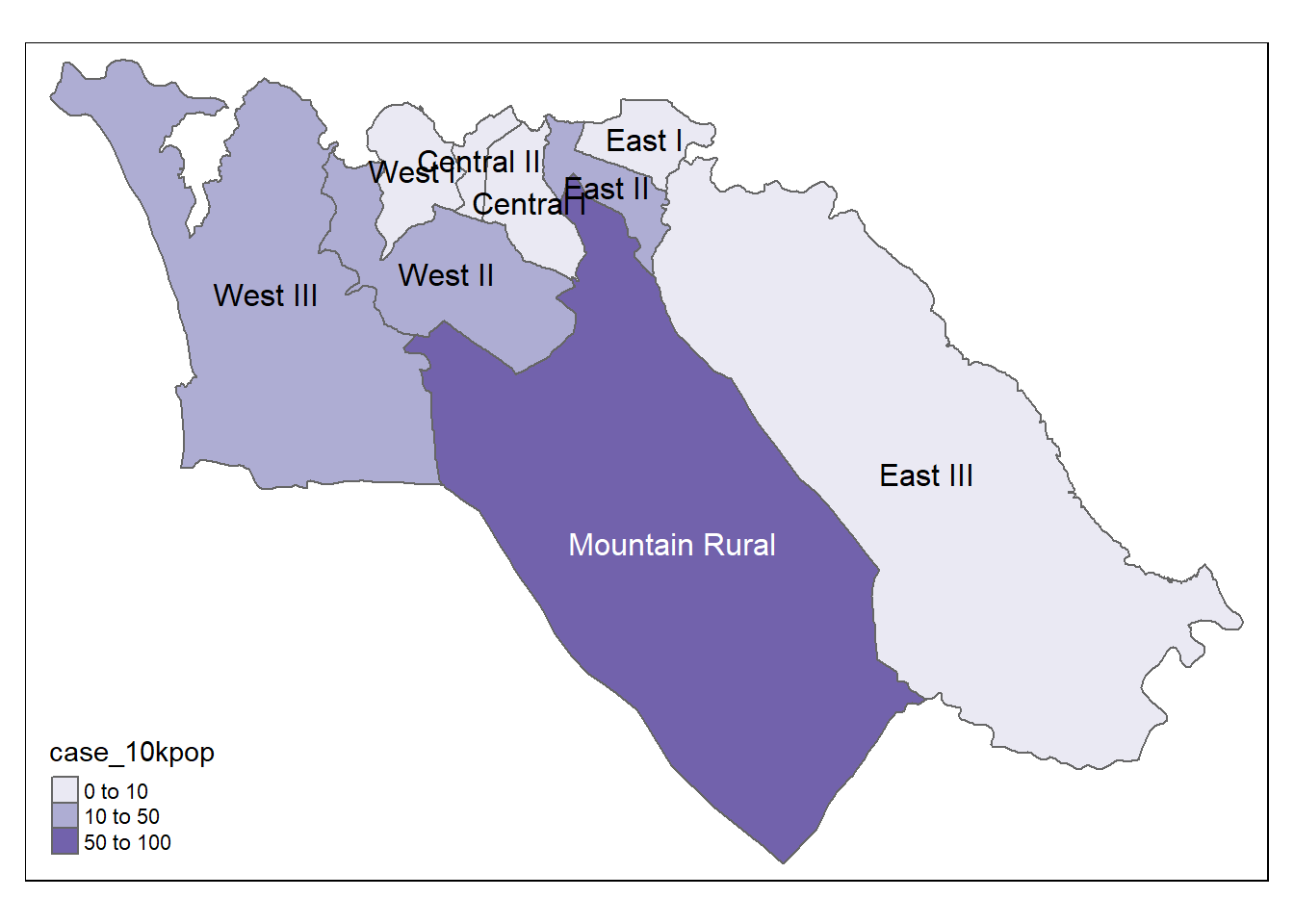
インシデンス率もまた地図にします。
# 1万人あたりの症例 tmap_mode ("plot" ) # 静的ビューモード # プロット tm_shape (case_adm3_sf) + # ポリゴンをプロット tm_polygons ("case_10kpop" , # 症例率を含む列で色分け breaks= c (0 , 10 , 50 , 100 ), # 色分けの値を定義 palette = "Purples" # 紫色のカラーパレットを使用 + tm_text ("admin3name" ) # テキストを表示
ggplot2 で地図作成
すでに ggplot2 パッケージ の使用に慣れている場合は、データの静的なマップを作成する代わりに、ggplot2 パッケージを使用することができます。geom_sf() は、データに含まれる特徴 (点、線、多角形) に応じて異なるオブジェクトを描画します。例えば、ポリゴンを含む sf データを使った ggplot() の中で geom_sf() を使うと、色分け地図を作ることができます。
これがどのように機能するかを説明するために、先ほど使用した ADM3 ポリゴンのシェープファイルから始めます。このポリゴンは、シエラレオネの Admin Level 3 の地域であることを思い出してください。
Simple feature collection with 12 features and 19 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -13.29894 ymin: 8.094272 xmax: -12.91333 ymax: 8.499809
Geodetic CRS: WGS 84
# A tibble: 12 × 20
objectid admin3name admin3pcod admin3ref_n admin2name admin2pcod admin1name
* <dbl> <chr> <chr> <chr> <chr> <chr> <chr>
1 155 Koya Rural SL040101 Koya Rural Western A… SL0401 Western
2 156 Mountain Ru… SL040102 Mountain R… Western A… SL0401 Western
3 157 Waterloo Ru… SL040103 Waterloo R… Western A… SL0401 Western
4 158 York Rural SL040104 York Rural Western A… SL0401 Western
5 159 Central I SL040201 Central I Western A… SL0402 Western
6 160 East I SL040203 East I Western A… SL0402 Western
7 161 East II SL040204 East II Western A… SL0402 Western
8 162 Central II SL040202 Central II Western A… SL0402 Western
9 163 West III SL040208 West III Western A… SL0402 Western
10 164 West I SL040206 West I Western A… SL0402 Western
11 165 West II SL040207 West II Western A… SL0402 Western
12 167 East III SL040205 East III Western A… SL0402 Western
# ℹ 13 more variables: admin1pcod <chr>, admin0name <chr>, admin0pcod <chr>,
# date <date>, valid_on <date>, valid_to <date>, shape_leng <dbl>,
# shape_area <dbl>, rowcacode0 <chr>, rowcacode1 <chr>, rowcacode2 <chr>,
# rowcacode3 <chr>, geometry <MULTIPOLYGON [°]>
dplyr パッケージ の left_join() を使って、マッピングしたいデータをシェープファイルオブジェクトに追加することができます。この例では、先ほど作成した case_adm3 データフレームを使って、行政区ごとの症例数をまとめていますが、データフレームに格納されているどのようなデータでも、同様の方法でマッピングすることができます。
<- sle_adm3 %>% inner_join (case_adm3, by = "admin3pcod" ) # inner join = どちらのデータオブジェクトにもある場合にのみ残す select (sle_adm3_dat, admin3name.x, cases) # console に選択した変数を表示
Simple feature collection with 9 features and 2 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -13.29894 ymin: 8.384533 xmax: -13.12612 ymax: 8.499809
Geodetic CRS: WGS 84
# A tibble: 9 × 3
admin3name.x cases geometry
<chr> <int> <MULTIPOLYGON [°]>
1 Mountain Rural 287 (((-13.21496 8.474341, -13.21479 8.474289, -13.21465 8.4…
2 Central I 65 (((-13.22646 8.489716, -13.22648 8.48955, -13.22644 8.48…
3 East I 56 (((-13.2129 8.494033, -13.21076 8.494026, -13.21013 8.49…
4 East II 106 (((-13.22653 8.491883, -13.22647 8.491853, -13.22642 8.4…
5 Central II 23 (((-13.23154 8.491768, -13.23141 8.491566, -13.23144 8.4…
6 West III 219 (((-13.28529 8.497354, -13.28456 8.496497, -13.28403 8.4…
7 West I 37 (((-13.24677 8.493453, -13.24669 8.493285, -13.2464 8.49…
8 West II 185 (((-13.25698 8.485518, -13.25685 8.485501, -13.25668 8.4…
9 East III 18 (((-13.20465 8.485758, -13.20461 8.485698, -13.20449 8.4…
ggplot2 パッケージ を使って、地域別の症例数の棒グラフを作成するには、次のように geom_col() を呼び出します。
ggplot (data= sle_adm3_dat) + geom_col (aes (x= fct_reorder (admin3name.x, cases, .desc= T), # 'cases' 下がり順でx軸を並べ替え y= cases)) + # y軸は地域ごとの症例数 theme_bw () + labs ( # 図のテキストを設定 title= "Number of cases, by administrative unit" ,x= "Admin level 3" ,y= "Number of cases" + guides (x= guide_axis (angle= 45 )) # 見やすいようにx軸を45度傾ける
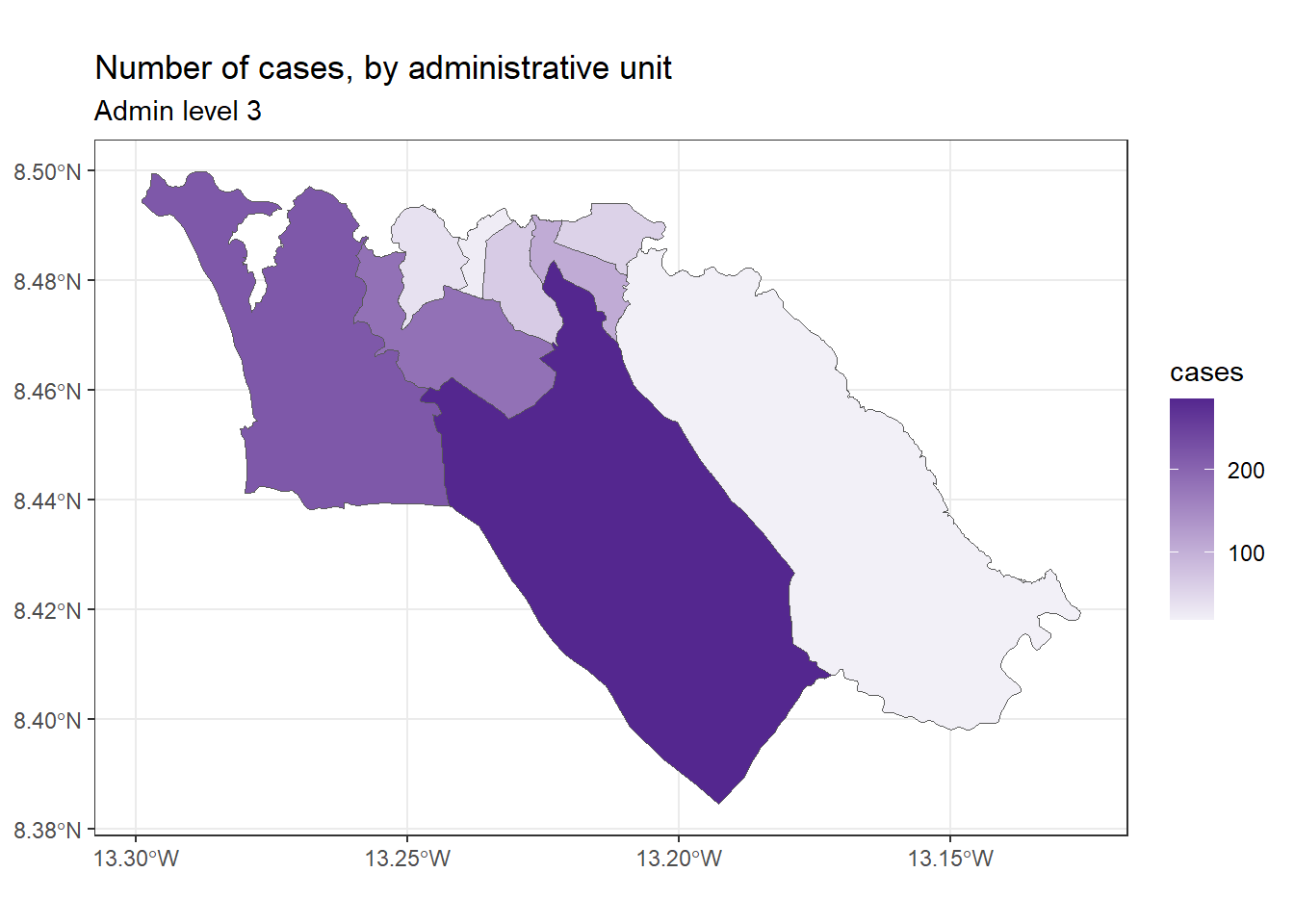
もし、ggplot2 パッケージ を使って症例数の色分け地図を作りたい場合は、同様の構文で geom_sf() を呼び出すことができます。
ggplot (data= sle_adm3_dat) + geom_sf (aes (fill= cases)) # 症例数で塗りつぶしが変化するように設定
そして、例えば、ggplot2 パッケージ で統一されている文法を使って、地図の外観をカスタマイズすることができます。
ggplot (data= sle_adm3_dat) + geom_sf (aes (fill= cases)) + scale_fill_continuous (high= "#54278f" , low= "#f2f0f7" ) + # 色の段階を変更 theme_bw () + labs (title = "Number of cases, by administrative unit" , # 図のテキストを設定 subtitle = "Admin level 3"
ggplot2 パッケージ に慣れているRユーザーにとって、geom_sf()は、実装がシンプルで直接的であり、基本的な地図の可視化に適しています。詳しくは、geom_sf() ビニエット(vignette) または ggplot2 book をご覧ください。
基図
OpenStreetMap
以下では、OpenStreetMap の機能を使って ggplot2 パッケージを利用したマップの基図を作成する方法を説明します。他の方法としては、Google への無料登録が必要な ggmap パッケージ を使用する方法があります(詳細 )。
OpenStreetMap
まず、OpenStreetMap パッケージをロードして、そこから基図を取得します。
次に、オブジェクト map を作成します。これは、OpenStreetMap パッケージの openmap() を使用して定義します (documentation )。以下のものを用意します。
upperLeft と lowerRight 基図タイルの境界を指定する2つの座標ペア。
ここでは、ラインリストの行の最大値と最小値を入れているので、地図は動的にデータに反応します。
zoom = (null の場合は自動的に決定されます)
type = 基図の種類 - ここではいくつかの可能性を挙げていますが、コードは現在、最初のもの([1])である “osm” を使用しています。
mergeTiles = TRUEを選択したので、ベースタイルはすべて1つに統合されます。
# パッケージをロード :: p_load (OpenStreetMap)# 緯度経度の範囲に基図を切り取る。タイル種別を選択。 <- OpenStreetMap:: openmap (upperLeft = c (max (linelist$ lat, na.rm= T), max (linelist$ lon, na.rm= T)), # 基図のタイルの制限 lowerRight = c (min (linelist$ lat, na.rm= T), min (linelist$ lon, na.rm= T)),zoom = NULL ,type = c ("osm" , "stamen-toner" , "stamen-terrain" , "stamen-watercolor" , "esri" ,"esri-topo" )[1 ])
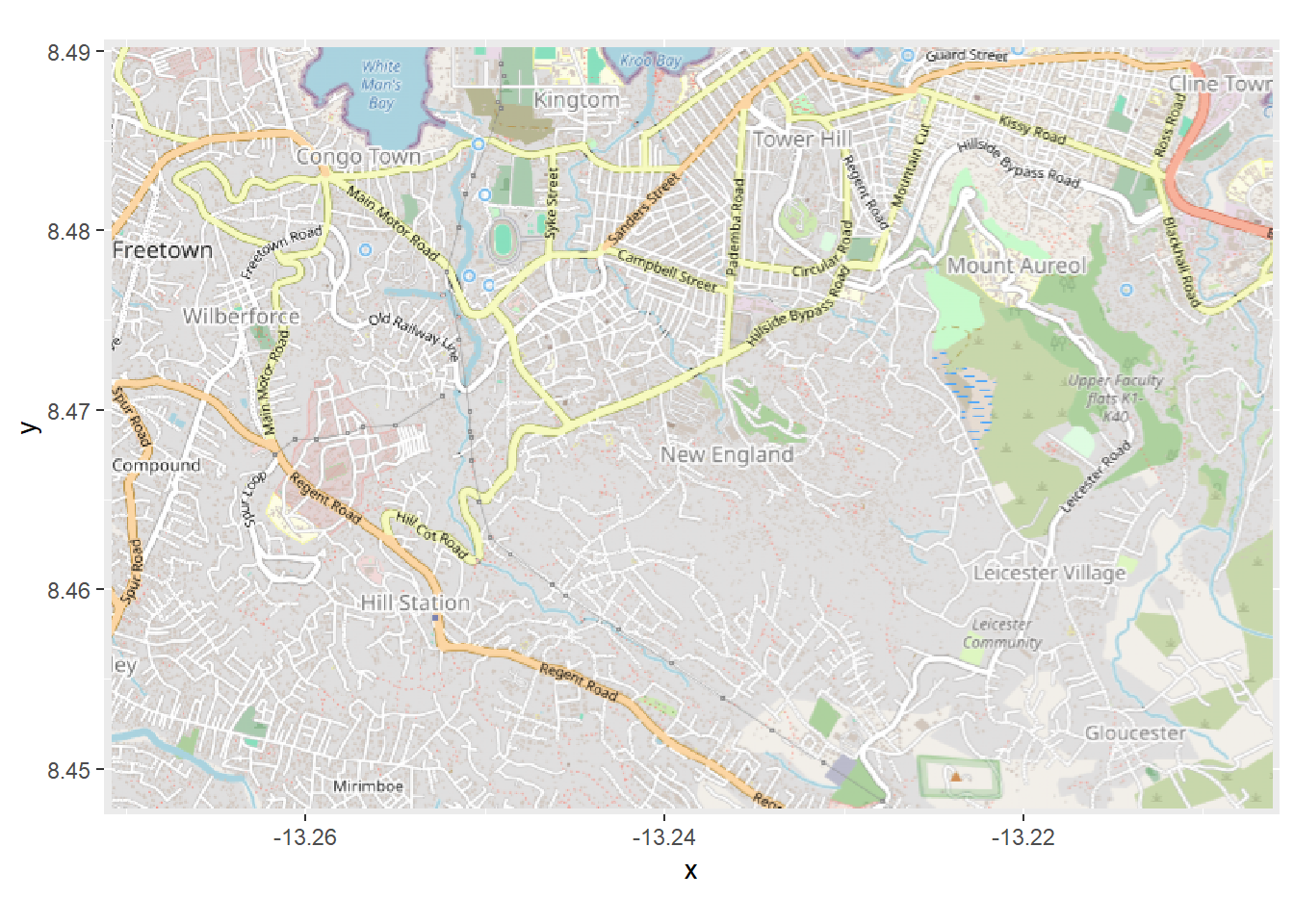
今、この基図を OpenStreetMap パッケージの autoplot.OpenStreetMap() を使ってプロットしてみると、軸の単位が緯度・経度座標ではない違う座標系を使っていることがわかります。緯度/経度で保存されている)症例の位置を正しく表示するには、これを変更する必要があります。
autoplot.OpenStreetMap (map)
そこで、 OpenStreetMap パッケージの openproj() を使って、地図を緯度/経度に変換したいと思います。基図 map と、必要な座標系(CRS)を指定します。ここでは、WGS 1984投影の “proj.4”文字列を指定していますが、他の方法でCRSを指定することもできます。(proj.4文字列が何であるかを理解するには、このページ を参照してください)
# 座標系 WGS84 <- openproj (map, projection = "+proj=longlat +ellps=WGS84 +datum=WGS84 +no_defs" )
プロットを作成すると、軸に沿って緯度と経度の座標が表示されています。座標系が変換されたことになります。これで、症例を重ね合わせても正しくプロットできるようになりました。
# 地図をプロット。ggplot を使うためには、"autoplot" が必須。 autoplot.OpenStreetMap (map_latlon)
詳しくはチュートリアルこちら とこちら をご覧ください。
等高線密度ヒートマップ
以下では、基図の上に症例の等高線付き密度ヒートマップを作成する方法を説明します。まず、ラインリストから始めます(1症例につき1行)。
上述のように OpenStreetMap から基図タイルを作成する
linelist の症例を、緯度と経度の列を使ってプロットする。
ggplot2 パッケージの stat_density_2d() を使って、点を密度ヒートマップに変換する。
緯度・経度座標を持つ基図があれば、その上に事例の居住地の緯度・経度座標を使ってプロットすることができます。
基図を作成するための関数 autoplot.OpenStreetMap() をベースにして、ggplot2 パッケージ の関数を使えば、以下の geom_point() のように簡単に上に追加することができます。
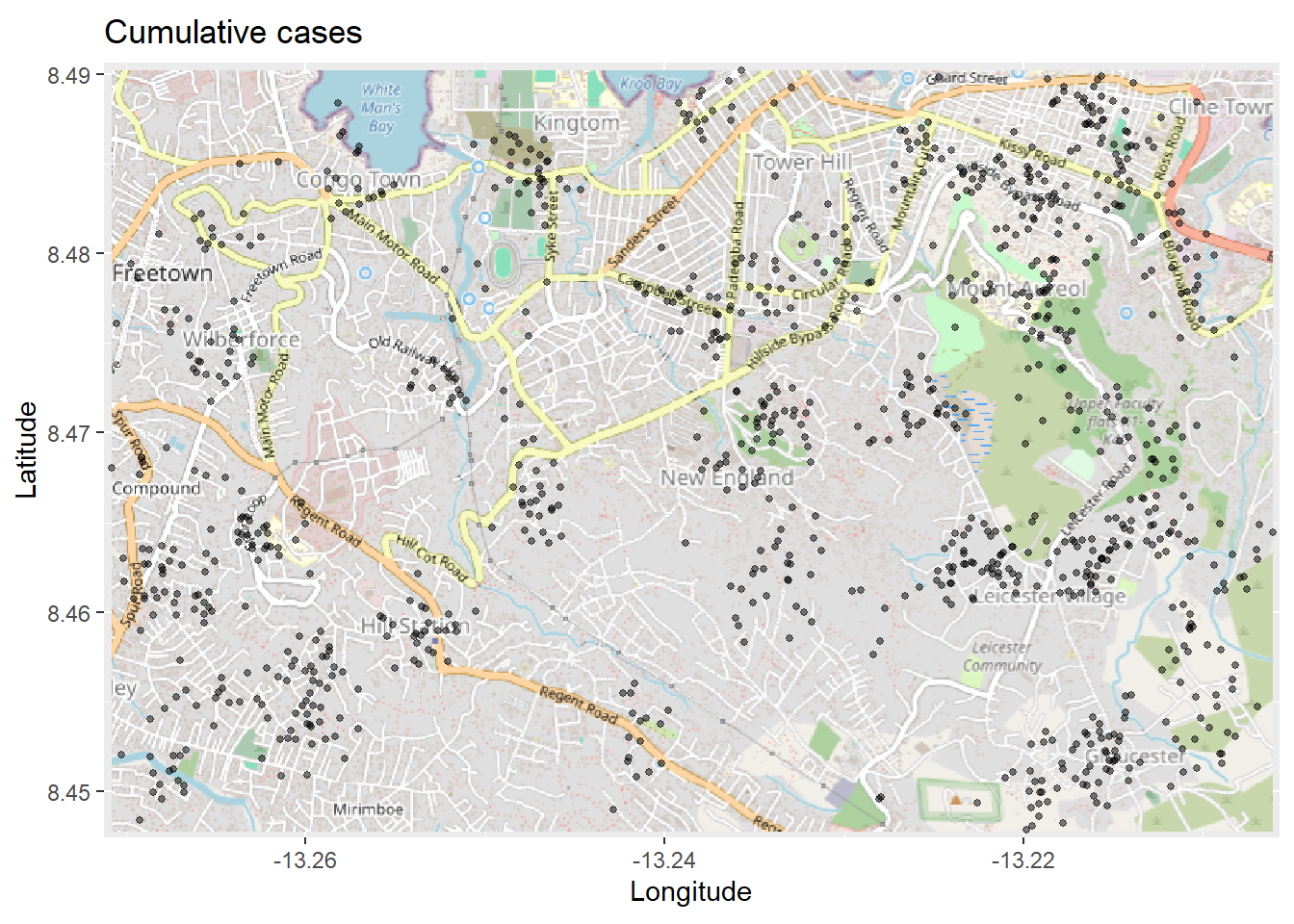
# 地図をプロット。ggplot と使うためには autoplot が必須。 autoplot.OpenStreetMap (map_latlon)+ # 基図から始める geom_point ( # ラインリストの経度と緯度の列から xy の点を追加 data = linelist, aes (x = lon, y = lat),size = 1 , alpha = 0.5 ,show.legend = FALSE ) + # 凡例を完全に削除 labs (x = "Longitude" , # タイトルとラベル y = "Latitude" ,title = "Cumulative cases" )
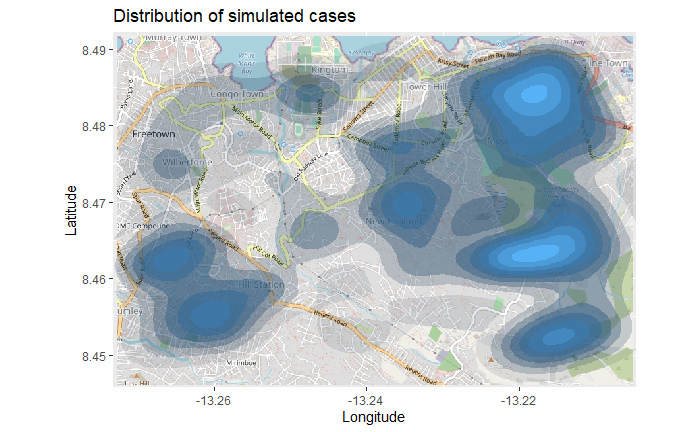
上のマップは、特に点が重なっているところは、解釈が難しいかもしれません。そこで、 ggplot2 パッケージの stat_density_2d() を用いて 2 次元密度マップを作成することができます。ラインリストの緯度/軽度座標を使用していますが、2D カーネル密度推定を行い、その結果を等高線で表示します(地形図のように)。完全なドキュメントはこちら をご覧ください。
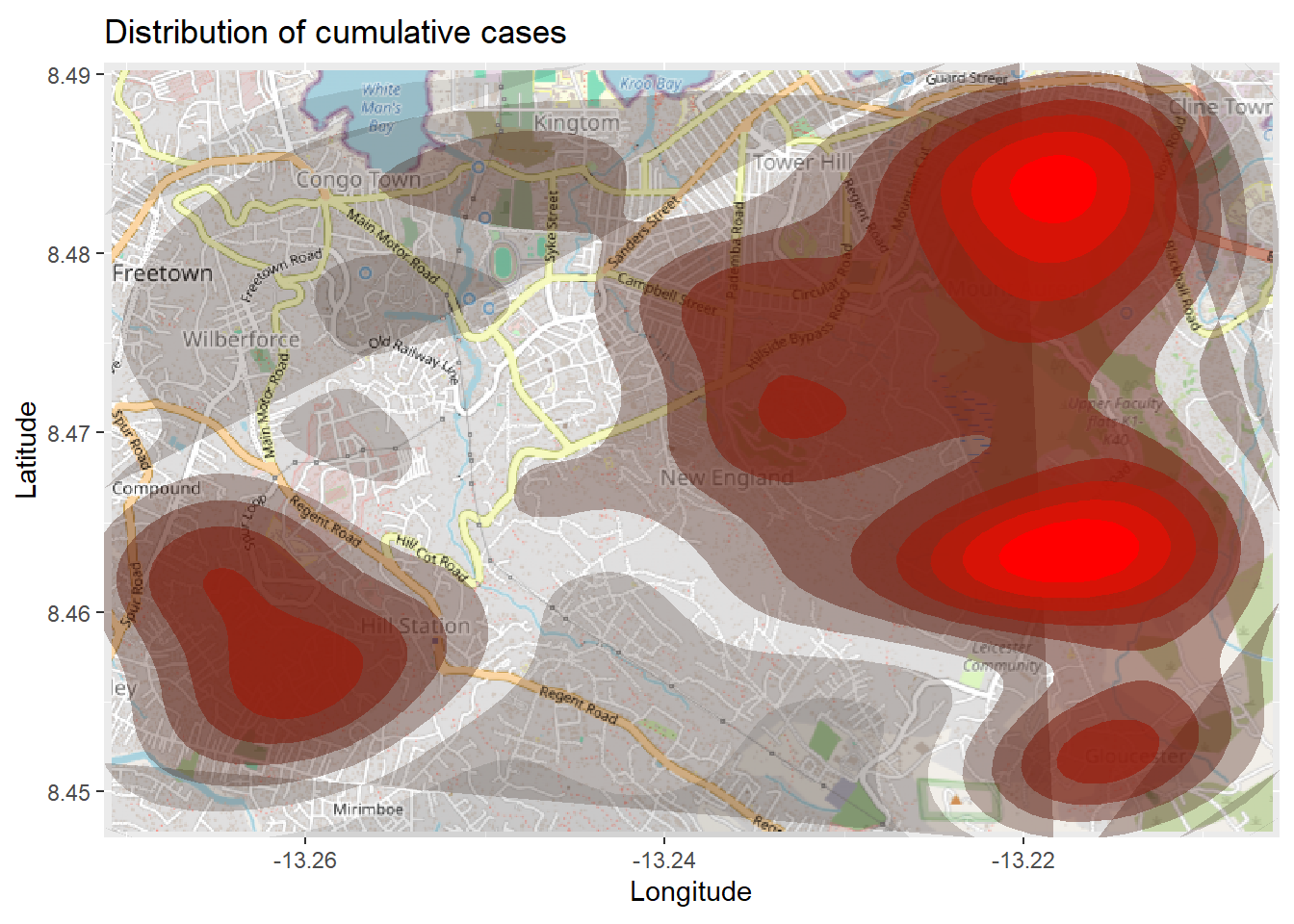
# 基図から始める autoplot.OpenStreetMap (map_latlon)+ # 密度プロットを追加 :: stat_density_2d (data = linelist,aes (x = lon,y = lat,fill = ..level..,alpha = ..level..),bins = 10 ,geom = "polygon" ,contour_var = "count" ,show.legend = F) + # カラースケールを指定 scale_fill_gradient (low = "black" , high = "red" )+ # ラベル labs (x = "Longitude" ,y = "Latitude" ,title = "Distribution of cumulative cases" )
時系列ヒートマップ
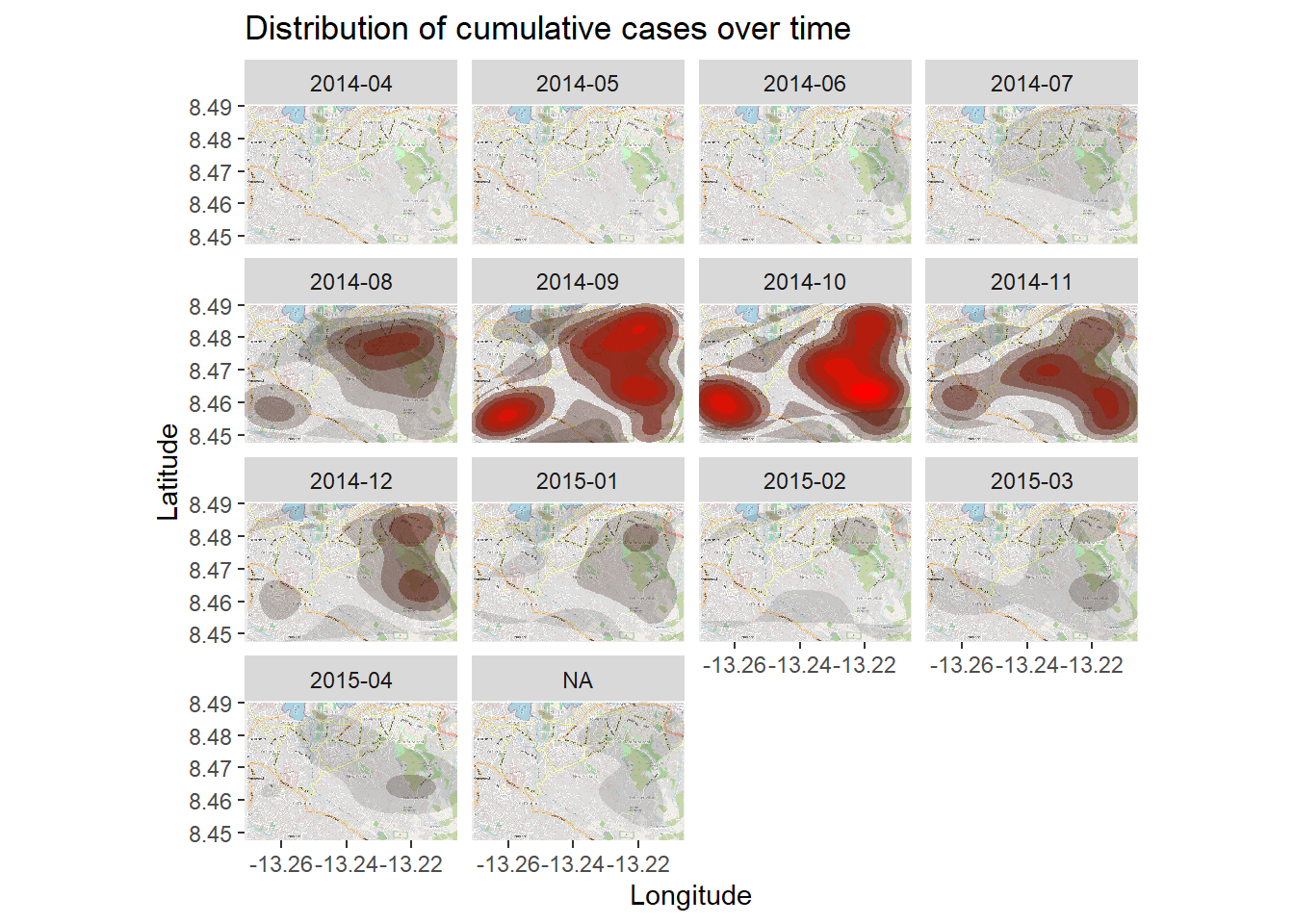
上の密度ヒートマップは、累積症例 を示しています。このヒートマップをラインリストから得られた症状の発症月 に基づいて分割 (facet) することで、時空間的なアウトブレイクを調べることができます。
まず、linelistで、発症した年と月の新しい列を作成します。base R の format() は、日付の表示方法を変更します。ここでは “YYYY-MM”とします。
# 発症した月を抽出 <- linelist %>% mutate (date_onset_ym = format (date_onset, "%Y-%m" ))# 値を調査 table (linelist$ date_onset_ym, useNA = "always" )
2014-04 2014-05 2014-06 2014-07 2014-08 2014-09 2014-10 2014-11 2014-12 2015-01
1 11 15 37 95 179 181 130 91 66
2015-02 2015-03 2015-04 <NA>
61 54 39 40
ここでは、密度ヒートマップに ggplot2 パッケージによる分割列を導入するだけです。facet_wrap() が適用され、新しい列が行として使用されます。わかりやすくするために、分割列の数を 3 に設定しました。
# パッケージ :: p_load (OpenStreetMap, tidyverse)# 基図から始める autoplot.OpenStreetMap (map_latlon)+ # 密度プロットを追加 :: stat_density_2d (data = linelist,aes (x = lon,y = lat,fill = ..level..,alpha = ..level..),bins = 10 ,geom = "polygon" ,contour_var = "count" ,show.legend = F) + # カラースケールを指定 scale_fill_gradient (low = "black" , high = "red" )+ # ラベル labs (x = "Longitude" ,y = "Latitude" ,title = "Distribution of cumulative cases over time" )+ # 発症した month-year でプロットを分割 facet_wrap (~ date_onset_ym, ncol = 4 )
空間統計
これまでの議論のほとんどは、空間データの視覚化に焦点を当ててきました。しかし、空間統計 を使用し、データ内の属性の空間的な関係を定量化したいような場合もあるでしょう。ここでは、空間統計の主要な概念を簡単に説明し、より包括的な空間分析を行いたい場合に参考となるリソースを紹介します。
空間的な関係
空間統計を計算する前に、データのフィーチャ間の関係を特定する必要があります。空間的な関係を概念化する方法は数多くありますが、シンプルで一般的に適用できるモデルは「隣接関係」です。具体的には、境界を共有している、または「隣り合っている」エリア間に地理的な関係があると考えます。
spdep パッケージで使用している sle_adm3 データの行政区域ポリゴン間の隣接関係を定量化することができます。ここでは、共点 隣接 (queen contiguity) を指定します。こちらは、地域がその境界に沿って少なくとも1つの点を共有していれば、隣り合っていることを意味します。この他には、共辺 隣接 (rook ) を指定することもできます。こちらは、地域がその境界に沿って境界縁を共有していれば、隣り合っていることを意味します。この違いは些細なことですが、この事例は不規則なポリゴンですので、場合によっては queen と rook の選択が影響を与えることもあります。
<- spdep:: poly2nb (sle_adm3_dat, queen= T) # 隣接を作成 <- spdep:: nb2mat (sle_nb) # 隣接関係をまとめた行列の作成 <- spdep:: nb2listw (sle_nb) # listw (重みのリスト) オブジェクトを作成 -- 後で使います
Neighbour list object:
Number of regions: 9
Number of nonzero links: 30
Percentage nonzero weights: 37.03704
Average number of links: 3.333333
round (sle_adjmat, digits = 2 )
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9]
1 0.00 0.20 0.00 0.20 0.00 0.2 0.00 0.20 0.20
2 0.25 0.00 0.00 0.25 0.25 0.0 0.00 0.25 0.00
3 0.00 0.00 0.00 0.50 0.00 0.0 0.00 0.00 0.50
4 0.25 0.25 0.25 0.00 0.00 0.0 0.00 0.00 0.25
5 0.00 0.33 0.00 0.00 0.00 0.0 0.33 0.33 0.00
6 0.50 0.00 0.00 0.00 0.00 0.0 0.00 0.50 0.00
7 0.00 0.00 0.00 0.00 0.50 0.0 0.00 0.50 0.00
8 0.20 0.20 0.00 0.00 0.20 0.2 0.20 0.00 0.00
9 0.33 0.00 0.33 0.33 0.00 0.0 0.00 0.00 0.00
attr(,"call")
spdep::nb2mat(neighbours = sle_nb)
上の図は、sle_adm3 データの 9 つのリージョン間の関係を示しています。スコア 0 は2つの地域が隣り合っていないことを示し、0以外の値は隣り合っていることを示しています。行列の値は、各地域の行の重みの合計が 1 になるようにスケーリングされています。
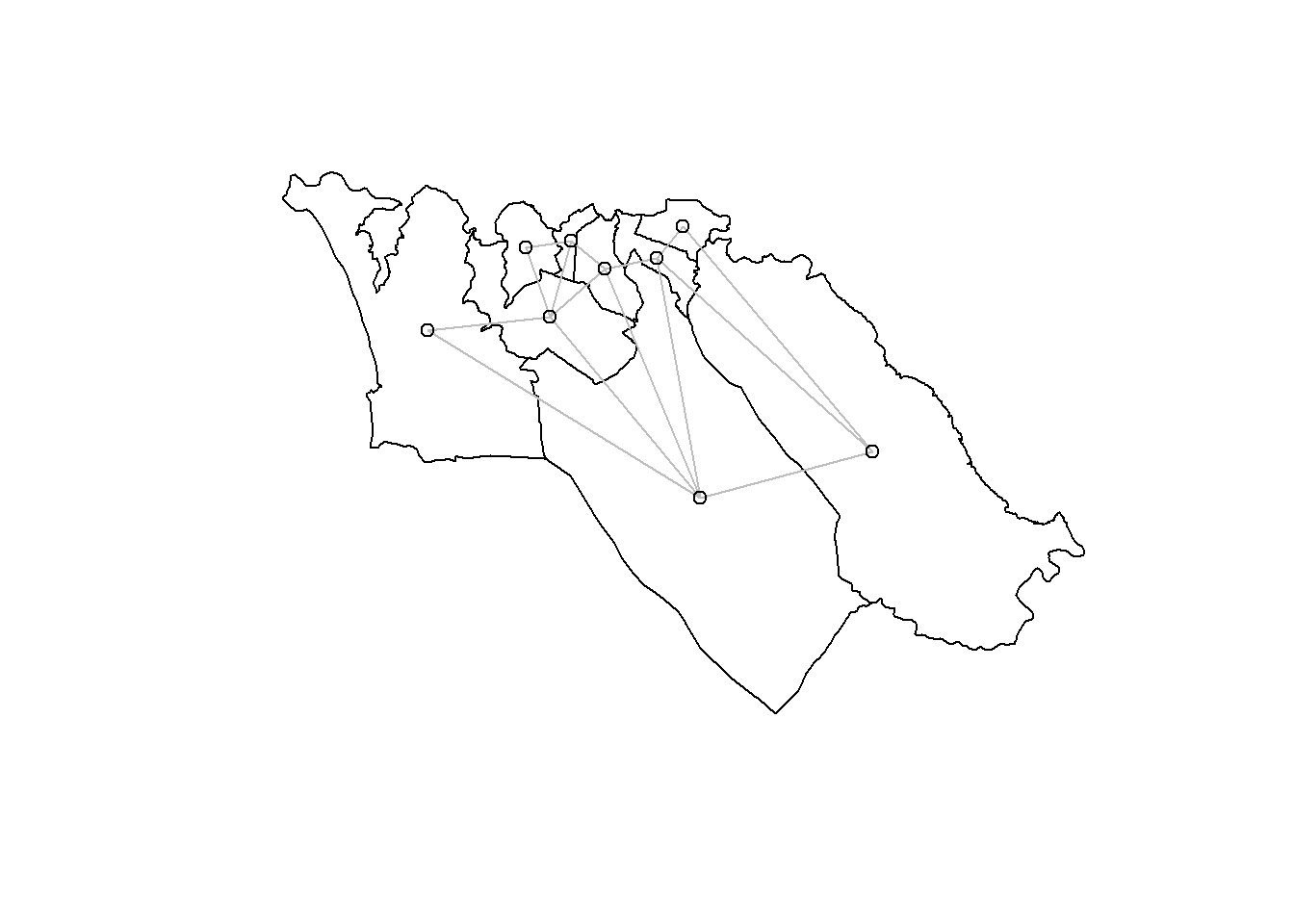
これらの隣接関係を視覚化するより良い方法は、プロットすることです。
plot (sle_adm3_dat$ geometry) + # 地域境界をプロット :: plot.nb (sle_nb,as (sle_adm3_dat, 'Spatial' ), col= 'grey' , add= T) # 隣接関係を追加
ここでは、隣接するポリゴンを特定するために、隣接アプローチを用いました。特定した隣接は、隣接ベース近傍 (contiguity-based neighbors ) と呼ばれることもあります。しかし、これは、どの地域が地理的な関係を持っていると予想されるかを選択する一つの方法に過ぎません。地理的関係を特定するため別の方法で、最も一般的な方法は、以下のような距離ベース近傍 を生成することです。
K-最近傍 - セントロイド(各ポリゴン領域の地理的に重み付けされた中心)間の距離に基づいて、n 個の最も近い領域を近傍として選択します。最大距離の近さのしきい値を指定することもできます。spdep パッケージでは、knearneigh() が使えます(ドキュメント を参照)。
距離閾値近傍 - 距離閾値以内のすべての近傍を選択します。spdep パッケージでは、これらの近傍関係は dnearneigh() を使って特定できます(ドキュメント を参照)。
空間的自己相関
よく引用されるトブラーの地理学の第一法則では、「すべてのものは他のすべてのものに関係しているが、近くのものは遠くのものより関係している」とされています。疫学においては、ある地域における特定の健康結果のリスクは、遠くの地域よりも近隣の地域に類似していることを意味していることが多いです。この概念は、「空間的自己相関」として正式に定義されています。これは、類似した値を持つ地理的フィーチャが空間的に集まっているという統計的特性です。空間的自己相関の統計的測定は、データにおける空間的クラスタリングの程度を定量化 し、クラスタリングが発生する場所を特定 し、データ内の異なる変数間の空間的自己相関の共通パターンを特定 するために使用することができます。このセクションでは、空間的自己相関の一般的な測定方法とRでの計算方法について説明します。
Moran’s I - これは、ある地域での変数の値と、近隣の地域での同じ変数の値との間の相関のグローバルな要約統計です。通常、Moran’s I 統計量は、-1 から 1 の範囲をとります。0 は、空間的な相関のパターンがないことを示し、1 や -1 に近い値は、それぞれ空間的な自己相関(似たような値が近くにある)や空間的なばらつき(似ていない値が近くにある)が強いことを示しています。
例として、先ほどマッピングしたエボラ出血熱の症例の空間的自己相関を定量化するために、Moran’s I 統計量を計算してみます(これは、シミュレーションされた linelist データフレームからの症例のサブセットであることを覚えておいてください)。spdep パッケージには、この計算を行うための、moran.test() があります。
<- spdep:: moran.test (sle_adm3_dat$ cases, # 指定の変数で数値ベクトル listw= sle_listw) # 隣接関係を要約したlistwオブジェクト # Moran's I 検定の結果を表示
Moran I test under randomisation
data: sle_adm3_dat$cases
weights: sle_listw
Moran I statistic standard deviate = 1.5771, p-value = 0.05739
alternative hypothesis: greater
sample estimates:
Moran I statistic Expectation Variance
0.20220485 -0.12500000 0.04304462
moran.test() の出力を見ると、Moran’s I 統計量は round(moran_i$estimate[1],2) となっています。これは、データに空間的な自己相関が存在することを示しています。具体的には、エボラ出血熱の患者数が同程度の地域は、近くにある可能性が高いということです。moran.test() で得られるp値は、空間的自己相関がないという帰無仮説の下での期待値との比較によって生成され、正式な仮説検定の結果を報告する必要がある場合に使用できます。
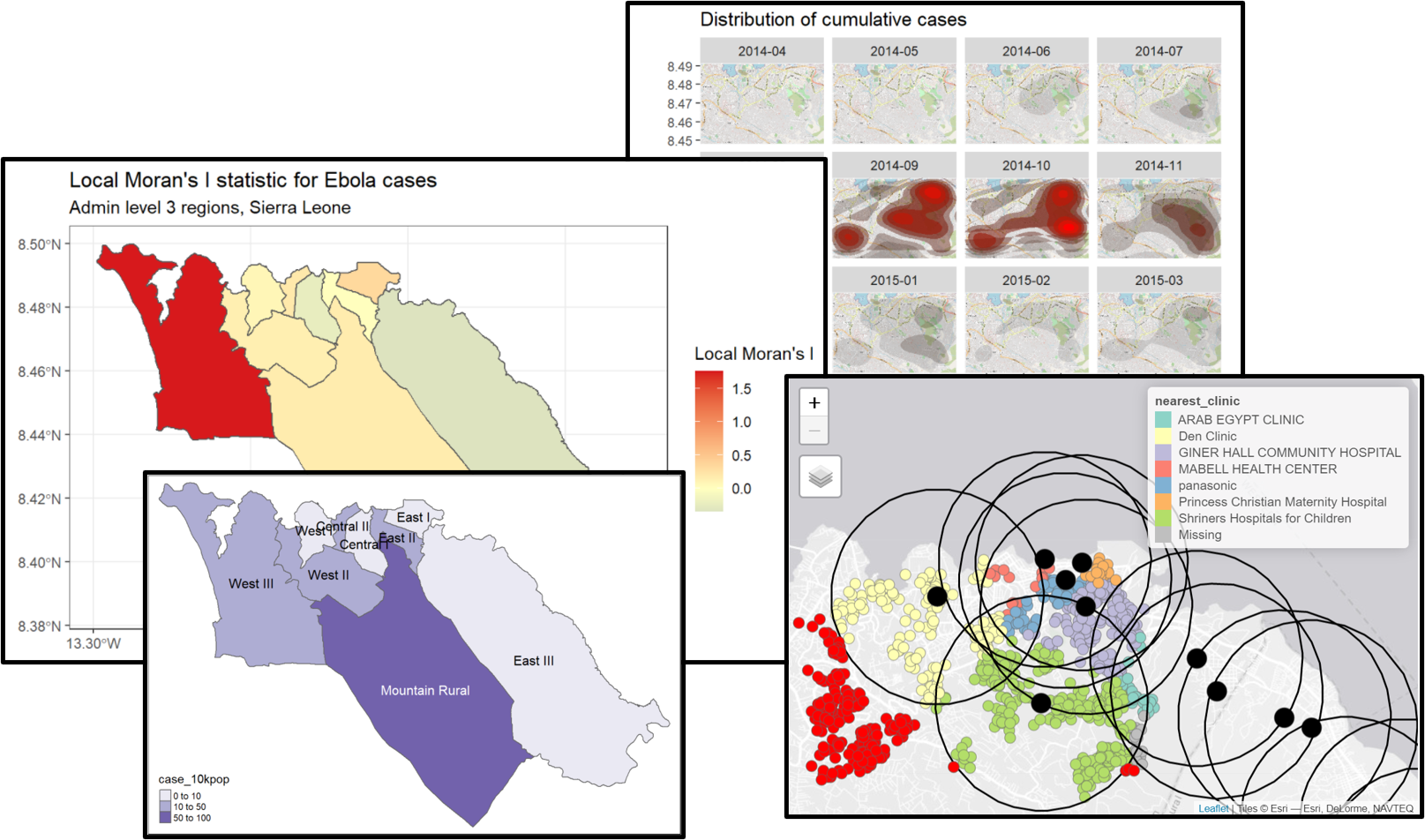
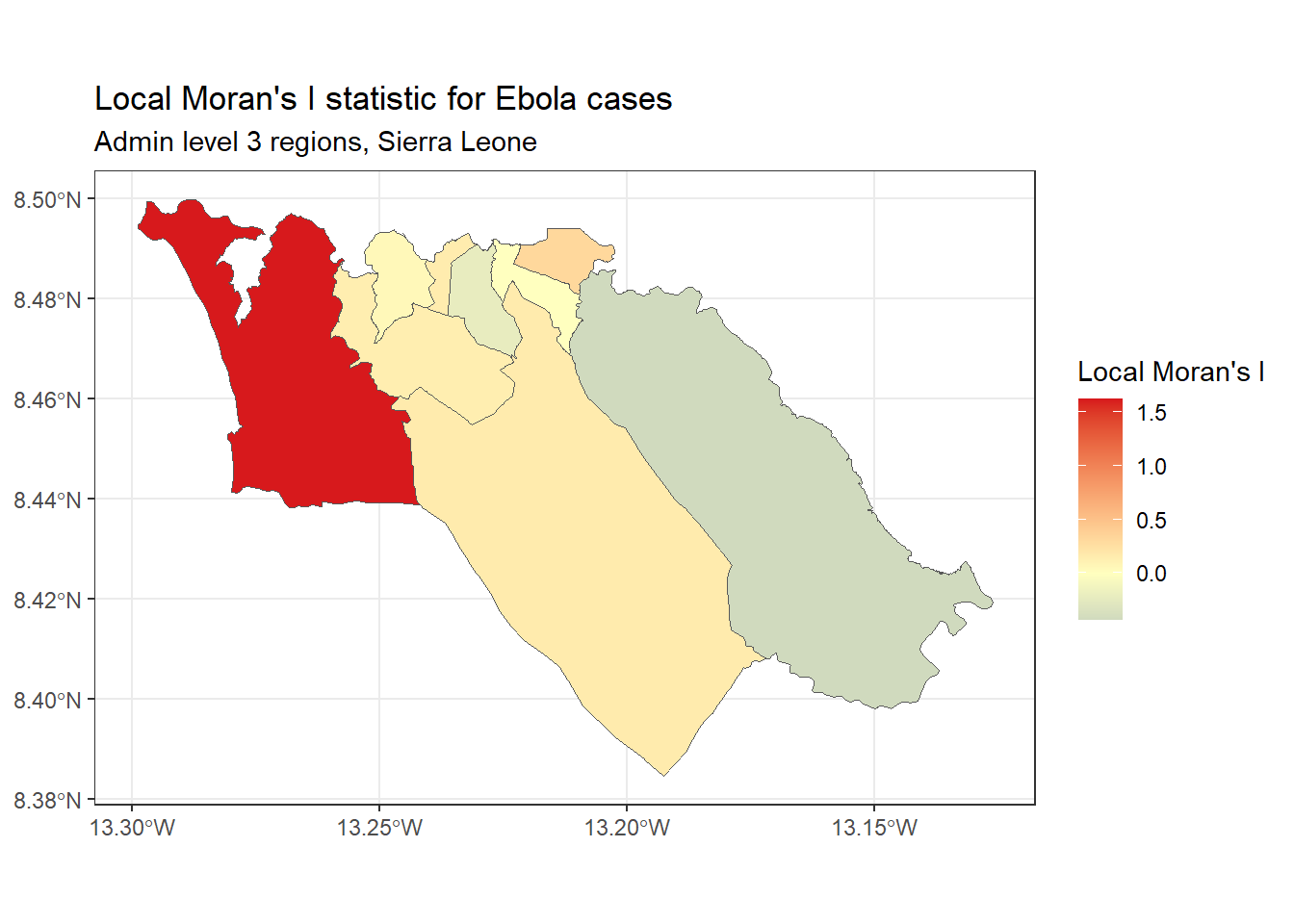
Local Moran’s I - 上で計算した(グローバルな)Moran’s I 統計を分解することで、局所的な 空間的な自己相関を識別することができます。これを利用すると、データ内の特定のクラスターの識別を行うことができます。この統計は、LISA(Local Indicator of Spatial Association)統計量と呼ばれることもあり、個々の地域における空間的自己相関の程度を要約したものです。この値は、地図上の「ホット」と「コールド」な場所を見つけるのに役立ちます。
例として、上で使用したエボラ出血熱の症例数に対して、spdep パッケージの local_moran() を用いて、Local Moran’s I を計算し、地図上に描画することができます。
# local Moran's I を計算 <- spdep:: localmoran ( $ cases, # 指定の変数 listw= sle_listw # 隣接の重み付けをした listw オブジェクト # 結果を sf データに結合 <- cbind (sle_adm3_dat, local_moran) # 地図をプロット ggplot (data= sle_adm3_dat) + geom_sf (aes (fill= Ii)) + theme_bw () + scale_fill_gradient2 (low= "#2c7bb6" , mid= "#ffffbf" , high= "#d7191c" ,name= "Local Moran's I" ) + labs (title= "Local Moran's I statistic for Ebola cases" ,subtitle= "Admin level 3 regions, Sierra Leone" )
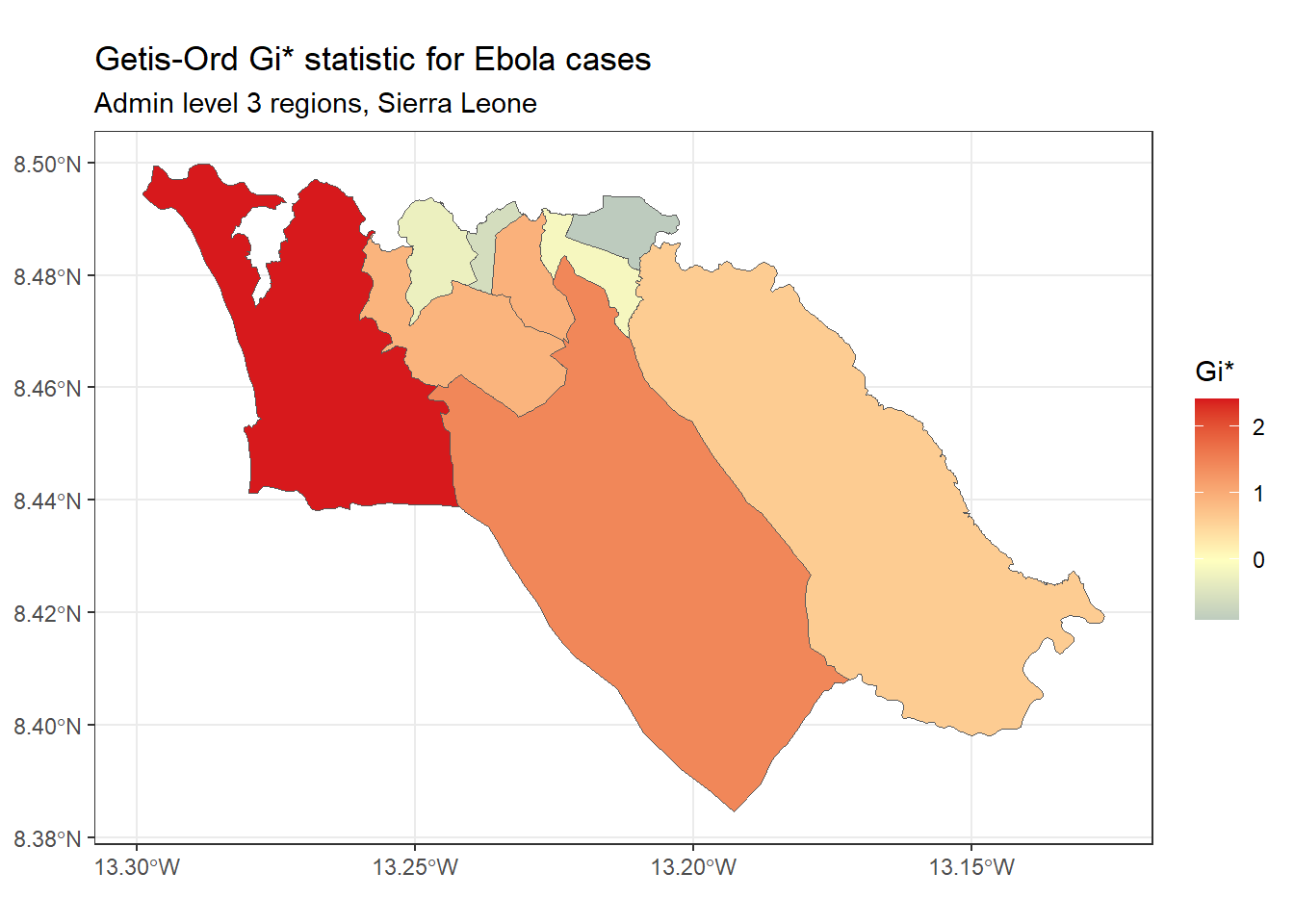
Getis-Ord Gi* - これもホットスポットの分析によく使われる統計です。この統計が人気である理由は、ArcGIS のホットスポット分析ツールで使われていることに関係しています。この統計は、通常、近隣地域間の変数の値の差は正規分布に従うはずだという仮定に基づいています。このツールは、z-score を利用したアプローチを用いて、指定された変数の値が近隣の地域に比べて統計的に特定の変数の値が有意に高い(ホットスポット)または低い(コールドスポット)地域を特定します。
spdep パッケージの localG() を使って Gi* 統計量を計算し、マッピングすることができます。
# local G 分析を実行 <- spdep:: localG ($ cases,# 結果を sf データに結合 $ getis_ord <- as.numeric (getis_ord)# 地図をプロット ggplot (data= sle_adm3_dat) + geom_sf (aes (fill= getis_ord)) + theme_bw () + scale_fill_gradient2 (low= "#2c7bb6" , mid= "#ffffbf" , high= "#d7191c" ,name= "Gi*" ) + labs (title= "Getis-Ord Gi* statistic for Ebola cases" ,subtitle= "Admin level 3 regions, Sierra Leone" )
上のとおり、Getis-Ord Gi* のマップは、先に作成した Local Moran’s の地図とは若干異なっています。これは、これらの2つの統計量を計算するために使用される方法がわずかに異なることを反映しています。どちらを使用すべきかは、特定の事例とあなたが関心を持っているリサーチクエスチョンに依存します。
Lee’s L test - これは、二変量の空間相関に関する統計的な検定です。与えられた変数 x の空間パターンが、x に空間的に関連すると仮定された別の変数 y の空間パターンに類似しているかどうかを検定することができます。
例として、シミュレーションしたエボラ出血熱の患者数の空間パターンが、人口の空間パターンと相関しているかどうかを検証してみましょう。まず始めに、sle_adm3 データに population 変数が必要です。先ほど読み込んだ sle_adm3_pop データフレームの total 変数を使うことができます。
<- sle_adm3_dat %>% rename (population = total) # 列名 total を population に変更
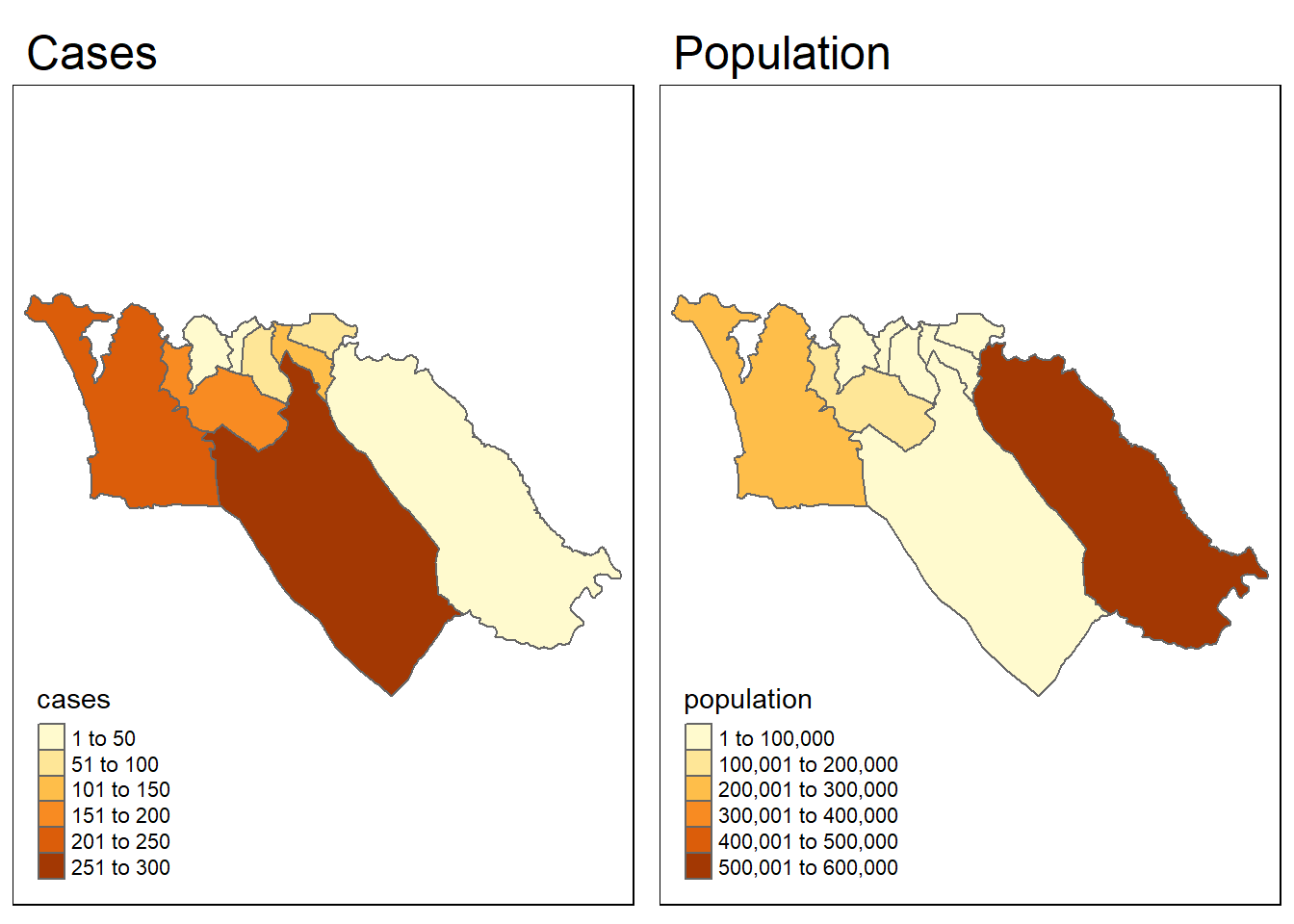
2つの変数の空間パターンを並べて視覚化することで、似ているかどうかをすぐに確認することができます。
tmap_mode ("plot" )<- tm_shape (sle_adm3_dat) + tm_polygons ("cases" ) + tm_layout (main.title= "Cases" )<- tm_shape (sle_adm3_dat) + tm_polygons ("population" ) + tm_layout (main.title= "Population" )tmap_arrange (cases_map, pop_map, ncol= 2 ) # arrange into 2x1 facets
視覚的には、この 2 つのパターンは似ていないように見えます。spdep パッケージの lee.test() を使って、2 つの変数の空間的自己相関のパターンが関連しているかどうかを統計的に検定することができます。L 統計量は、パターン間に相関がなければ 0 に近く、強い正の相関があれば(パターンが似ている場合は)1 に近く、強い負の相関があれば(パターンが逆の場合は)-1 に近くなります。
<- spdep:: lee.test (x= sle_adm3_dat$ cases, # 比較する変数1 y= sle_adm3_dat$ population, # 比較する変数2 listw= sle_listw # 隣接重みづけのある listw オブジェクト
Lee's L statistic randomisation
data: sle_adm3_dat$cases , sle_adm3_dat$population
weights: sle_listw
Lee's L statistic standard deviate = -0.9954, p-value = 0.8402
alternative hypothesis: greater
sample estimates:
Lee's L statistic Expectation Variance
-0.15688836 -0.04633098 0.01233621
上記の出力では、2つの変数の Lee’s L 統計量が round(lee_test$estimate[1],2) となり、弱い負の相関があることを示しています。これは、症例のパターンと人口が互いに関連していないという私たちの視覚的な評価を裏付けるものであり、症例の空間的なパターンは、厳密には高リスク地域の人口密度の結果ではないという証拠となります。
Lee’s L 統計は、空間的に分布する変数間の関係について、このような推論を行うのに役立ちます。しかし、2 つの変数間の関係の性質をより詳細に記述したり、交絡を調整したりするには、空間回帰 技術が必要になります。以下では、これらについて簡単に説明します。
空間回帰
空間データの変数間の関係を統計的に推論したい場合があります。このような場合には、空間回帰 の手法、つまり、データ内のユニットの空間的な構成を明示的に考慮した回帰のアプローチを検討することが有用です。GLM のような標準的な回帰モデルではなく、空間回帰モデルを検討する必要がある理由は以下の通りです。
標準的な回帰モデルは、残差が互いに独立していることを前提としています。標準回帰モデルは、残差が互いに独立であると仮定していますが、強い空間的自己相関 がある場合、標準回帰モデルの残差は空間的にも自己相関している可能性が高く、この仮定に反することになります。これは、モデルの結果を解釈する際に問題となる可能性があり、そのような場合には、空間モデルを使用することが望ましいでしょう。
また、回帰モデルでは、変数 x の効果がすべての観測点で一定であることを仮定します。空間的に異質 である場合、推定したい効果は空間によって異なる可能性があり、その違いを定量化することに興味があるかもしれません。このような場合、空間回帰モデルは効果の推定と解釈をより柔軟に行うことができます。
空間回帰アプローチの詳細については、このハンドブックの範囲外です。このセクションでは、最も一般的な空間回帰モデルとその用途の概要を説明し、この分野をさらに探求したい場合に役立つ参考文献を紹介します。
空間誤差モデル - これらのモデルは、空間ユニット間の誤差項が相関していると仮定していますが、その場合、データは標準的な最小二乗法(OLS) モデルの仮定に反することになります。空間誤差モデルは、「同時自己回帰(SAR)モデル」と呼ばれることもあります。空間誤差モデルは、 spatialreg パッケージの errorsarlm()(空間回帰関数、以前は spdep パッケージの一部だった)を使ってフィットさせることができます。
空間ラグモデル - このモデルは、ある地域 i の従属変数が、i の独立変数の値だけでなく、i に隣接する地域のそれらの変数の値にも影響されると仮定しています。空間誤差モデルと同様に、空間ラグモデルもまた、同時自己回帰(SAR)モデル と呼ばれることがあります。 空間ラグモデルは、spatialreg パッケージの lagsarlm() を使ってフィットさせることができます。
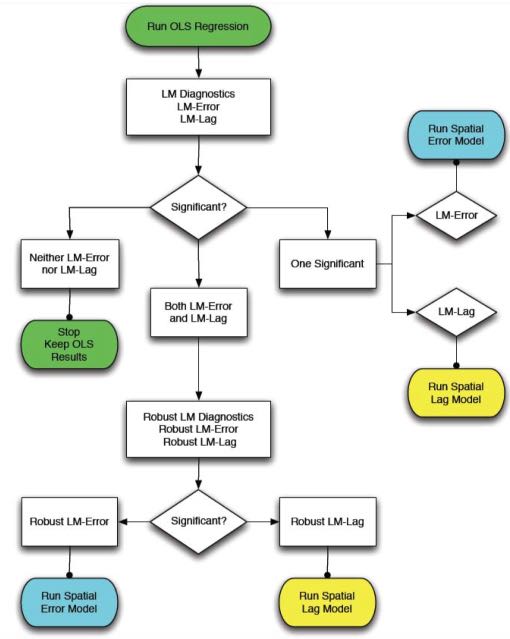
spdep パッケージには、標準的な最小二乗法 (OLS) モデル、空間ラグモデル、空間誤差モデルを決定するための便利な診断テストがいくつか含まれています。これらのテストは、ラグランジュ乗数診断 と呼ばれ、データの空間依存性のタイプを特定し、どのモデルが最も適切かを選択するために使用することができます。lm.LMtests() を用いると、すべてのラグランジュ乗数検定を計算することができます。Anselin (1988) は、ラグランジュ乗数検定の結果に基づいて、どの空間回帰モデルを使用するかを決定するための便利なフローチャートツールも提供しています。
ベイズ階層モデル - ベイズを用いた手法は、いくつかの応用例において空間分析で一般的に使用されています。最も一般的なのは 疾患マッピング です。症例データの分布がまばらであったり(例えば、稀な結果の場合)、統計的に「ノイズが多い」場合には、潜在的な空間プロセスを考慮して疾病リスクの「平滑化された」推定値を生成するために使用することができるので、ベイズを用いた手法の方が好まれます。これにより、推定値の質が向上する可能性があります。また、データに存在する可能性のある複雑な空間的相関パターンを(選択することで)事前に指定することができ、独立変数と従属変数の両方における空間依存および非依存の変動を説明することができます。Rでは、CARbayes パッケージ( ビニエット(vignette) 参照)や R-INLA(website や textbook 参照)を用いてベイズ階層モデルをフィットさせることができます。また、R は JAGS や WinBUGS のようなベイズ推定を行う外部ソフトウェアを呼び出すのにも使うことができます。