28 Основы ГИС
28.1 Обзор
Пространственные аспекты ваших данных могут дать много полезной информации в ситуации вспышек, а также ответить на подобные вопросы:
- Где находятся текущие очаги заболевания?
- Как изменились очаги со временем?
- Каков доступ к медицинским организациям? Нужны ли какие-то улучшения?
Фокус данной страницы по ГИС - ответить на потребности прикладных эпидемиологов при реагировании на вспышки. Мы рассмотрим основные методы пространственной визуализации данных, используя пакеты tmap и ggplot2. Мы также рассмотрим некоторые основные методы управления данными и запросов с помощью пакета sf. И наконец, мы кратко затронем концепции пространственной статистики, например, пространственные отношения, пространственная автокорреляция и пространственная регрессия, используя пакет spdep.
28.2 Ключевые понятия
Ниже мы представим некоторые ключевые понятия. Для более подробного знакомства с ГИС и пространственным анализом, мы рекомендуем вам изучить один из более подробных самоучителей или курсов, указанных в разделе Ресурсы.
Географическая информационная система (ГИС) - ГИС - это рамка или среда для сбора, управления, анализа и визуализации пространственных данных.
Программное обеспечение ГИС
Некоторые популярные ГИС программы допускают взаимодействие по принципу “навести и кликнуть” для разработки карты и пространственного анализа. Эти инструменты имеют свои преимущества - не нужно учиться писать код и легко выбирать вручную и размещать иконки и параметры на карте. Вот две популярных программы:
ArcGIS - Коммерческая ГИС программа, разработанная компанией ESRI, которая очень популярна, но весьма дорогая
QGIS - Бесплатная открытая ГИС программа, которая может делать почти все то же самое, что и ArcGIS. Вы можете скачать QGIS тут
Использование R как ГИС может сначала показаться сложным, поскольку вместо принципа “навести и кликнуть” используется “интерфейс командной строки” (необходимо написать код, чтобы получить желаемый результат). Однако это является серьезным преимуществом, если вам необходимо регулярно готовить одни и те же карты или создавать воспроизводимый анализ.
Пространственные данные
Две основные формы пространственных данных, используемых в ГИС, включают в себя векторные и растровые данные:
Векторные данные - Наиболее частый формат пространственных данных, используемых в ГИС, векторные данные состоят из геометрических характеристик вершин и путей. Векторные пространственные данные можно еще разделить на три широко используемых типа:
Точки - Точка состоит из пары координат (x,y), представляющих определенное место в системе координат. Точки являются наиболее простой формой пространственных данных и могут использоваться для обозначения случая (например, дома пациента) или места (например, больницы) на карте.
Линии - Линия состоит из двух соединенных точек. Линии имеют определенную длину и могут использоваться для обозначения таких объектов, как дороги или реки.
Полигоны - Полигон состоит как минимум из трех отрезков, соединенных точками. Полигоны имеют длину (т.е. периметр области), а также измеряют площадь. Полигоны могут использоваться для обозначения территории (например, деревни) или структуры (например, фактической площади больницы).
Растровые данные - Альтернативный формат пространственных данных, растровые данные представляют собой матрицу ячеек (например, пикселей), каждая из которых содержит такую информацию, как высота, температура, уклон, лесной покров и т.д. Часто это аэрофотоснимки, спутниковые снимки и т.д. Растровые данные также могут использоваться в качестве “базовых карт” под векторными данными.
Визуализация пространственных данных
Чтобы визуально представить пространственные данные на карте, программное обеспечение ГИС требует от вас задать достаточную информацию о том, где должны быть характеристики по отношению друг к другу. Если вы используете векторные данные, что действительно так в большинстве примеров применения, эта информация, как правило, хранится в шейп-файле:
Шейп-файлы - Шейп-файл - частый формат данных для хранения “векторных” пространственных данных, состоящих из линий, точек или полигново. Один шейп-файл на самом деле является сочетанием как минимум трех файлов - .shp, .shx, и .dbf. Все эти файлы-подкомпоненты должны присутствовать в определенной директории (папке) для того, чтобы шейп-файл был читаемым. Эти связанные файлы можно сжать в ZIP папку и направить по почте, либо скачать с веб-сайта.
Шейп-файл будет содержать информацию о самих характеристиках, а также о том, где их найти на поверхности Земли. Это важно, потому что хотя Земля - шар, карты, как правило, двухмерные; решения о том, как сделать пространственные данные “плоскими” может иметь большое влияение на вид и интерпретацию полученных в результате карт.
Референтная система координат (РСК) - это это система координат, используемая для определения местоположения географических объектов на поверхности Земли. Она состоит из нескольких основных компонентов:
Ситема координат - Существует множество различных систем координат, поэтому необходимо знать, в какой системе находятся ваши координаты. Обычно используются градусы широты/долготы, но можно также использовать координаты универсальной поперечной проекции Меркатора UTM.
Единицы - знайте, какие единицы используютсядля вашей системы координат (например, десятичные градусы, метры)
Основа системы координат - Определенная смоделированная версия Земли. В течение многих лет они пересматривались, поэтому убедитесь, что слои карты используют одну и ту же основу.
Проекция - Ссылка на математическое уравнение, которое было использовано для проецирования истинно круглой Земли на плоскую поверхность (карту).
Помните, что обобщить пространственные данные можно и без использования представленных ниже картографических средств. Иногда достаточно простой таблицы по географическому признаку (например, район, страна и т.д.)!
28.3 Начало работы с ГИС
Для создания карты необходимо иметь и продумать несколько ключевых моментов. К ним относятся:
Набор данных – Это может быть формат пространственных данных (например, шейп-файлы, как отмечалось выше), а может быть и не пространственный формат (например, просто csv).
-
Если ваш набор данных не в пространственном формате, вам также потребуется референтный набор данных. Референтные данные состоят из пространственного представления данных и соответствующих атрибутов, которые включают материал, содержащий информацию о месте расположения и адресе конкретных характеристик.
Если вы работаете с заранее определенными географическими границами (например, административными районами), то референтные шейп-файлы часто можно свободно загрузить из государственных учреждений или организаций по обмену данными. В случае сомнений лучше всего начать с поиска в Google “шейп-файл [регионов]”
Если у вас есть информация об адресе, но нет широты и долготы, вы можете использовать механизм геокодирования, чтобы получить референтные пространственные данные для ваших записей.
Идея того, как вы хотите представить информацию в ваших наборах данных вашей целевой аудитории. Существует много разных типов карт и важно подумать о том, какой тип карты лучше подходит для ваших потребностей.
Типы карт для визуализации ваших данных
Картограмма - тип тематической карты, в которой цвета, тени или узоры используются для представления географических регионов в зависимости от значения какого-либо атрибута. Например, большее значение может быть обозначено более темным цветом, чем меньшее. Этот тип карт особенно полезен при визуализации переменной и ее изменений в определенных регионах или геополитических зонах.
Тепловая карта плотности случаев - разновидность тематической карты, в которой цвета используются для отображения интенсивности значения, однако для группирования данных не используются определенные регионы или геополитические границы. Этот тип карт обычно используется для отображения ‘очагов’ или зон с высокой плотностью или концентрацией точек.
Карта плотности точек - тип тематической карты, на которой точками обозначаются значения атрибутов в данных. Этот тип карты лучше всего использовать для визуализации разброса данных и визуального поиска кластеров.
Карта пропорциональных символов (карта градуированных символов) - тематическая карта, аналогичная картограмме, но вместо цвета для обозначения значения атрибута используется символ (обычно круг) по отношению к значению. Например, большее значение может быть обозначено более крупным символом, чем меньшее значение. Этот тип карты лучше всего использовать, когда необходимо визуализировать размер или количество данных по географическим регионам.
Можно также комбинировать несколько различных типов визуализаций, чтобы показать сложные географические закономерности. Например, на приведенной ниже карте случаи (точки) окрашены в соответствии с ближайшим к ним медицинским учреждением (см. легенду). Крупные красные круги показывают участки прикрепления (охвата) для медицинской организации определенного радиуса, а яркие красные точки - случаи, находящиеся за пределами зон охвата:
Примечание: Основной фокус данной страницы по ГИС основан на контексте реагирования на вспышки заболеваний на местах. Поэтому содержание страницы охватывает основные операции с пространственными данными, визуализацию и анализ.
28.4 Подготовка
Загрузка пакетов
Этот фрагмент кода показывает загрузку пакетов, необходимых для анализа. В данном руководстве мы фокусируемся на использовании p_load() из пакета pacman, которая устанавливает пакет, если необходимо, и загружает его для использования. Вы можете также загрузить установленные пакеты с помощью library() из базового R. См. страницу [Основы R] для получения дополнительной информации о пакетах R.
pacman::p_load(
rio, # для импорта данных
here, # для пути к файлу
tidyverse, # для вычистки, работы с данными и построения графиков (включает пакет ggplot2)
sf, # для управления пространственными данными, используя формат простых свойств (Simple Feature)
tmap, # для создания простых карт, работает как для интерактивных, так и статичных карт
janitor, # для вычистки имен столбцов
OpenStreetMap, # для добавления базовой карты OSM на карту ggplot
spdep # пространственная статистика
) Вы можете посмотреть обзор всех пакетов, которые работают с пространственными данными в CRAN “Spatial Task View”.
Пример данных о случаях
Для демонстрационных целей мы будем работать со случайной выборкой из 1000 случаев из имитированной эпидемии Эболы из датафрейма linelist (с точки зрения вычислений работу с меньшим количеством случаев легче отобразить в руководстве). Если вы хотите выполнять действия параллельно, кликните, чтобы скачать “чистый” построчный список (как .rds файл).
Поскольку мы делаем случайную выборку, при самостоятельном выполнении кодов результаты могут несколько отличаться от представленных здесь.
Импортируем данные с помощью функции import() из пакета rio (он работает с разными типами файлов, такими как .xlsx, .csv, .rds - см. детали на странице [Импорт и экспорт]).
# импорт чистого построчного списка случаев
linelist <- import("linelist_cleaned.rds") Далее делаем случайную выборку 1000 строк, используя sample() из базового R.
# генерируем 1000 случайных номеров строк из числа строк построчного списка
sample_rows <- sample(nrow(linelist), 1000)
# подмножество построчного списка, чтобы сохранить только строки выборки и все столбцы
linelist <- linelist[sample_rows,]Теперь нам нужно конвертировать этот построчный список linelist, который относится к классу датафрейм, в объект класса “sf” (пространственные свойства). Учитывая, что в построчном списке есть два столбца “lon” и “lat”, представляющих собой долготу и широту для места проживания каждого случая, это будет легко сделать.
Мы используем пакет sf (пространственные свойствуа) и его функцию st_as_sf() для создания нового объекта, который мы назовем linelist_sf. Этот новый объект, по сути, выглядит так же как и построчный список, но столбцы lon и lat были отмечены как столбцы координат и была присвоена референтная система координат при отображении точек. 4326 определяет наши координаты как основанные на всемирной геодезической системе 1984 (WGS84) - которая является стандартом для GPS координат.
# создаем объект sf
linelist_sf <- linelist %>%
sf::st_as_sf(coords = c("lon", "lat"), crs = 4326)Вот так выглядит оригинальный датафрейм linelist. В этой демонстрации мы будем использовать только столбец date_onset и geometry (который был создан из полей широты и долготы, указанных выше, и является последним столбцом в датафрейме).
DT::datatable(head(linelist_sf, 10), rownames = FALSE, options = list(pageLength = 5, scrollX=T), class = 'white-space: nowrap' )Шейп-файлы административных границ
Сьерра-Леоне: шейп-файлы административных границ
Мы заранее скачали все административные границы для Сьерра-Леоне с веб-сайта Humanitarian Data Exchange (HDX) веб-сайт тут. Альтернативно вы можете скачать их и другие примеры данных для руководства через наш пакет R, который представлен на странице [Скачивание руководствау и данных].
Теперь мы выполним следующие действия, чтобы сохранить шейп-файл Admin Level 3 в R:
- Импортируем шейп-файл
- Вычищаем имена столбцов
- Фильтруем строки, чтобы сохранить только интересующие районы
Чтобы импортировать шейп-файл, мы используем функцию read_sf()из sf. Ей задается путь к файлу с помощью here(). - в нашем случае файл находится внутри нашего проекта R в подпапках “data”, “gis” и “shp”, а имя файла - “sle_adm3.shp” (для дополнительной информации см. страницы [Импорт и экспорт] и [Проекты R]). Вам нужно задать свой собственный путь к файлу.
Далее мы используем clean_names() из пакета janitor, чтобы стандартизировать имена столбцов шейп-файла. Мы также используем filter(), чтобы сохранить только строки с admin2name “Western Area Urban” или “Western Area Rural”.
# чистый уровень ADM3
sle_adm3 <- sle_adm3_raw %>%
janitor::clean_names() %>% # стандартизируем имена столбцов
filter(admin2name %in% c("Western Area Urban", "Western Area Rural")) # фильтр, чтобы сохранить некоторые районыНиже вы видите как выглядит каждый шейп-файл после импорта и вычистки. Пролистайте вправо, чтобы увидеть столбцы с admin уровень 0 (страна), admin уровень 1, admin уровень 2, и наконец, admin уровень 3. У каждого уровня есть текстовое имя и уникальный идентификационный “pcode”. pcode увеличивается на каждом увеличивающемся уровне admin level, например, SL (Сьерра-Леоне) -> SL04 (Western - западная) -> SL0410 (Western Area Rural - Западный сельский район) -> SL040101 (Koya Rural - Сельский район Койа).
Данные о населении
Сьерра-Леоне: Население по ADM3
Опять же, эти данные можно скачать с (ссылка тут) или через наш пакет R epirhandbook, как объясняется [на этой странице][Скачивание руководства и данных]. Мы используем import() для загрузки .csv файла. Мы также передаем импортированный файл в clean_names(), чтобы стандартизировать синтаксис имен столбцов.
# Население по ADM3
sle_adm3_pop <- import(here("data", "gis", "population", "sle_admpop_adm3_2020.csv")) %>%
janitor::clean_names()Вот как выглядит файл по населению. Пролистайте вправо, посмотрите, что у каждой юрисдикции есть столбец с мужским населением (male), женским населением (female), общим населением (total), а также разбивка населения по столбцам по возрастной группе.
Медицинские организации
Сьерра-Леоне: Данные о медицинских организациях из OpenStreetMap
Опять же, мы скачиваем места расположения медицинских организаций с HDX тут или с помощью инструкций на странице [Скачивание руководства и данных].
Мы импортируем шейп-файл с точками медицинских организацией с помощью read_sf(), также вычищаем имена столбцов, затем фильтруем, чтобы сохранить только те точки, которые отмечены как “hospital”, “clinic” или “doctors”.
# Шейп-файл по медицинским организациям из OSM
sle_hf <- sf::read_sf(here("data", "gis", "shp", "sle_hf.shp")) %>%
janitor::clean_names() %>%
filter(amenity %in% c("hospital", "clinic", "doctors"))Вот получившийся в результате датафрейм - пролистайте вправо, чтобы увидеть название организации и координаты geometry.
28.5 Построение графика координат
Самый простой способ построить координаты X-Y (долгота/широта, точки), в случае этих случаев - нарисовать их как точки напрямую из объекта linelist_sf, который мы создали на этапе подготовки.
Пакет tmap предлагает простые возможности составления как статических (режим “график - plot”), так и интерактивных карт (режим “просмотр - view”) буквально с помощью нескольких строк кода. Синтаксис tmap похож на ggplot2 в том, что команды добавляются друг к другу +. Более подробно читайте в этой виньетке.
- Устанавливаем режим tmap. В этом случае используем режим графика “plot”, который создает статические результаты.
tmap_mode("plot") # выберите "view" или "plot"Ниже мы показываем только точки. В tm_shape() задаются объекты linelist_sf. Затем мы добавляем точки с помощью tm_dots(), уточняяя размер и цвет. Поскольку linelist_sf является объектом sf, мы уже назначили два столбца, которые содержат координаты широты/долготы и референтную систему координат (РСК):
# Только случаи (точки)
tm_shape(linelist_sf) + tm_dots(size=0.08, col='blue')
Отдельно точки не очень информативны. Поэтому нужно также наложить карту административных границ:
Мы снова используем tm_shape() (см. документацию), но вместо того, чтобы задать шейп-файл с точками случаев, мы задаем шейп-файл с административными границами (полигонами).
С помощью аргумента bbox = (bbox означает “ограничительная рамка”) мы можем уточнить границы координат. Сначала мы покажем отображение карты без bbox, а затем с ним.
# Только административные границы (полигоны)
tm_shape(sle_adm3) + # шейп-файл административных границ
tm_polygons(col = "#F7F7F7")+ # показываем полигоны светло серым
tm_borders(col = "#000000", # показываем границы с помощью цвета и толщины линии
lwd = 2) +
tm_text("admin3name") # текст столбца для отображения для каждого полигона
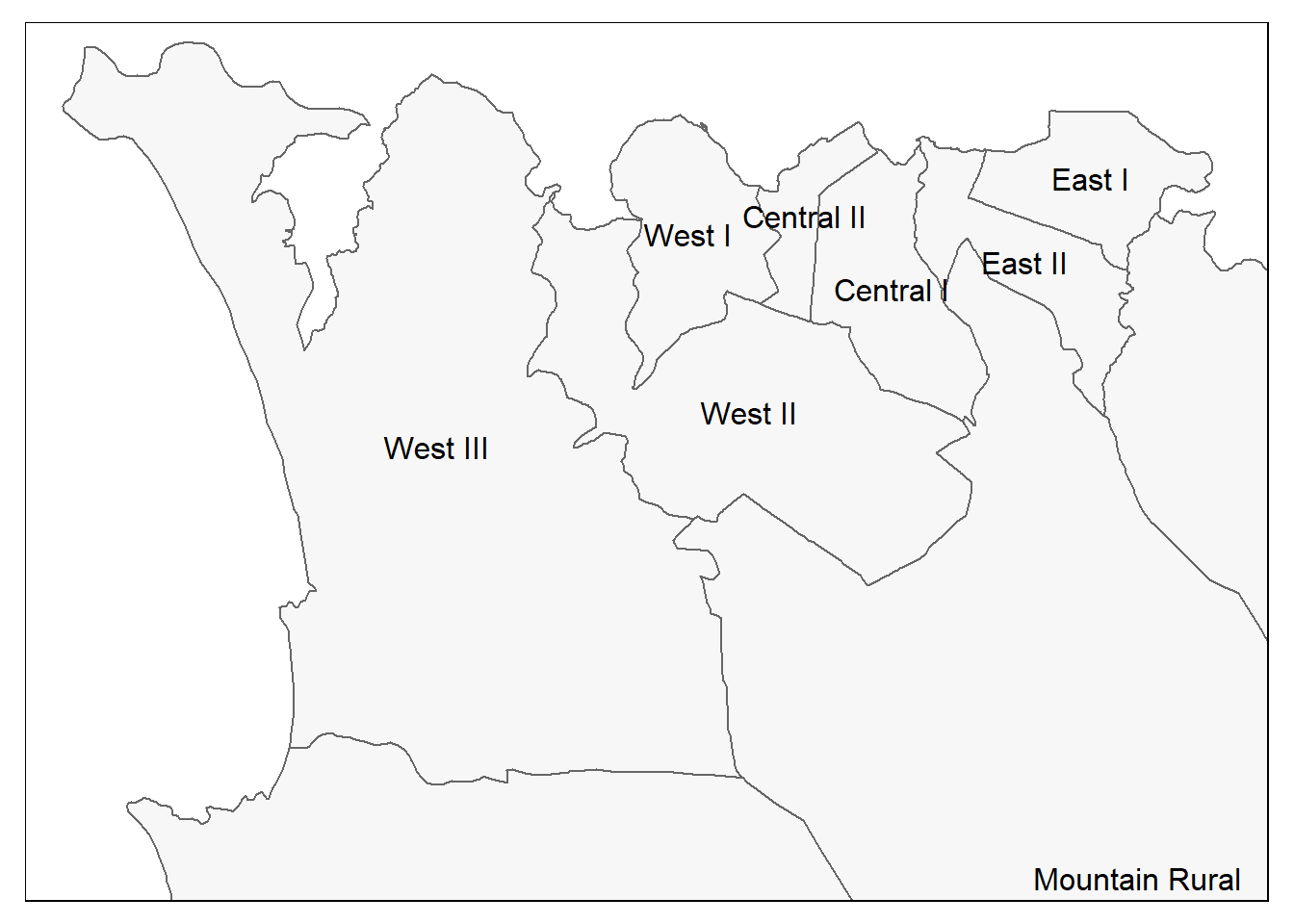
# Также как до этого, но с ограничительной рамкой
tm_shape(sle_adm3,
bbox = c(-13.3, 8.43, # угол
-13.2, 8.5)) + # угол
tm_polygons(col = "#F7F7F7") +
tm_borders(col = "#000000", lwd = 2) +
tm_text("admin3name")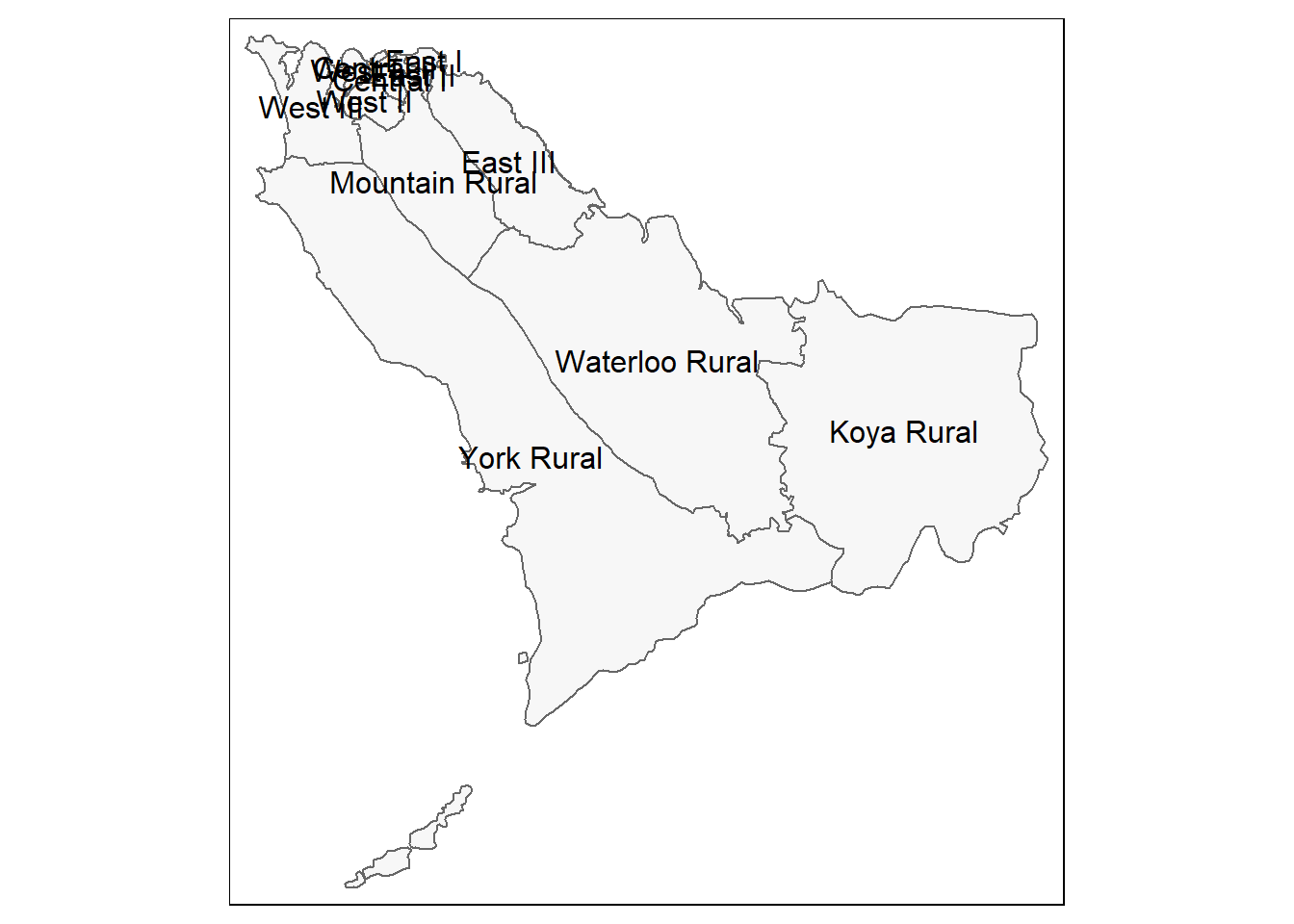
Теперь вместе точки и полигоны:
# All together
tm_shape(sle_adm3, bbox = c(-13.3, 8.43, -13.2, 8.5)) + #
tm_polygons(col = "#F7F7F7") +
tm_borders(col = "#000000", lwd = 2) +
tm_text("admin3name")+
tm_shape(linelist_sf) +
tm_dots(size=0.08, col='blue', alpha = 0.5) +
tm_layout(title = "Distribution of Ebola cases") # определяем заголовок карты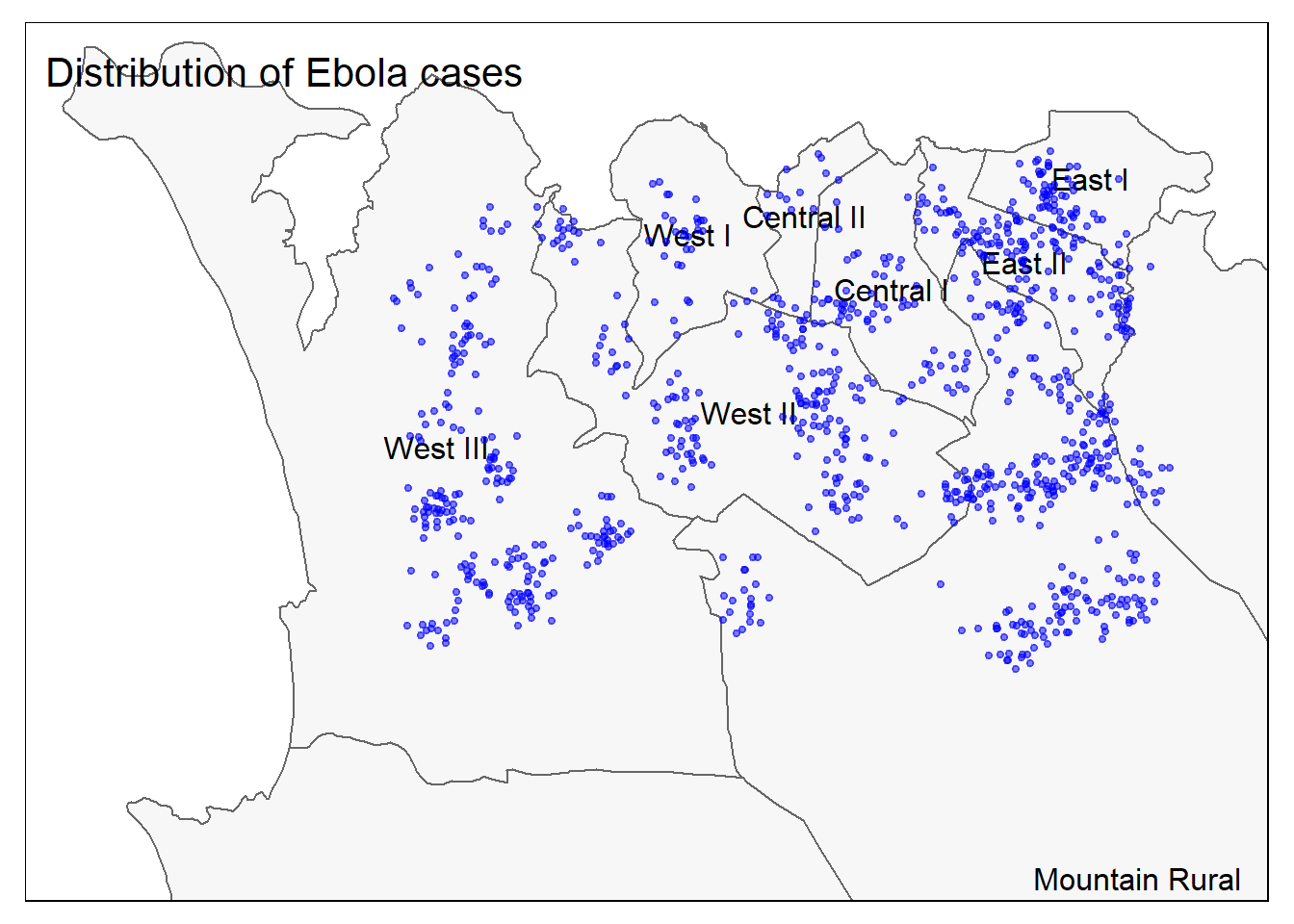
Хорошее сравнение опций картирования в R можно прочитать в этом посте в блоге.
28.6 Пространственные соединения
Вы можете быть знакомы с соединением данных из одного набора данных с другим. На странице [Соединение данных] руководства обсуждается несколько методов. Пространственное соединение служит аналогичным целям, но использует в большей степени пространственные отношения. Вместо того, чтобы полагаться на общие значения в столбцах, которые должны совпадать с наблюдениями, вы можете использовать их пространственные отношения, например, если одна характеристика находится внутри другой, либо является ближайшим соседом к другому, либо находится внутри буферной зоны определенного радиуса от другого и т.п.
Пакет sf предлагает разные методы пространственного соединения. См. дополнительную документацию по методу st_join и типам пространственного соединения по этой ссылке.
Точки в полигонах
Пространственное присваивание административных единиц для случаев
Здесь возникает интересная проблема: в построчном списке случаев не содержится никакой информации об административных единицах этих случаев. Хотя идеально было бы собрать такую информацию на этапе первоначального сбора данных, мы также можем присвоить административные единицы отдельным случаям на основе их пространственных связей (например, точка пересекается с полигоном).
Ниже мы отобразим пространственное пересечение расположения случаев (точки) с границами ADM3 (полигоны):
- Начинаем с построчного списка (точки)
- Пространственное соединение с границами, установка типа соединения в “st_intersects”
- Используем
select(), чтобы сохранить только некоторые новые столбцы с административными границами
linelist_adm <- linelist_sf %>%
# соединяем файл с административными границами с построчным списком на основе пространственного пересечения
sf::st_join(sle_adm3, join = st_intersects)Вса столбцы из sle_adms были добавлены в построчный список! У каждого случая теперь есть столбцы, указывающие административные уровни, к которым он относится. В данном примере мы хотим сохранить только два новых столбца (уровень admin 3), поэтому вы выбираем старые имена столбцов и всего два дополнительных интересующих с помощью select():
linelist_adm <- linelist_sf %>%
# соединяем файл с административными границами с построчным списком на основе пространственного пересечения
sf::st_join(sle_adm3, join = st_intersects) %>%
# сохраняем старые имена столбцов и два новых интересующих столбца admin
select(names(linelist_sf), admin3name, admin3pcod)Ниже в целях иллюстрирования вы можете увидеть первые 10 случаев и их юрисдикции на уровне admin 3 (ADM3), которые были присоединены на основе того, где точка пространственно пересекалась с формами полигонов.
# теперь используем имена ADM3, присоединенные к каждому случаю
linelist_adm %>% select(case_id, admin3name, admin3pcod)Simple feature collection with 1000 features and 3 fields
Geometry type: POINT
Dimension: XY
Bounding box: xmin: -13.27122 ymin: 8.447753 xmax: -13.20613 ymax: 8.490746
Geodetic CRS: WGS 84
First 10 features:
case_id admin3name admin3pcod geometry
4280 241a7d West III SL040208 POINT (-13.25955 8.456019)
3260 ceee63 East I SL040203 POINT (-13.21588 8.487489)
3133 501f29 East II SL040204 POINT (-13.22259 8.483358)
4173 6fbf2f West III SL040208 POINT (-13.26315 8.486153)
117 a11d21 Mountain Rural SL040102 POINT (-13.21382 8.465117)
2619 18ee39 West III SL040208 POINT (-13.26451 8.45718)
1041 1655de West III SL040208 POINT (-13.26031 8.457142)
4641 821030 East II SL040204 POINT (-13.21894 8.484974)
2865 af82b2 West III SL040208 POINT (-13.26751 8.461085)
161 8e1819 Mountain Rural SL040102 POINT (-13.21726 8.465353)Теперь мы можем описать наши случаи по административной единице - до пространственного соединения мы не могли этого сделать!
# создаем новый датафрейм, содержащий количество случаев по административным единицам
case_adm3 <- linelist_adm %>% # начинаем с построчного списка с новыми столбцами admin
as_tibble() %>% # конвертируем в таблицу tibble для более удобного отображения
group_by(admin3pcod, admin3name) %>% # группируем по административной единице по имени и pcode
summarise(cases = n()) %>% # обобщаем и считаем строки
arrange(desc(cases)) # сортируем в порядке уменьшения
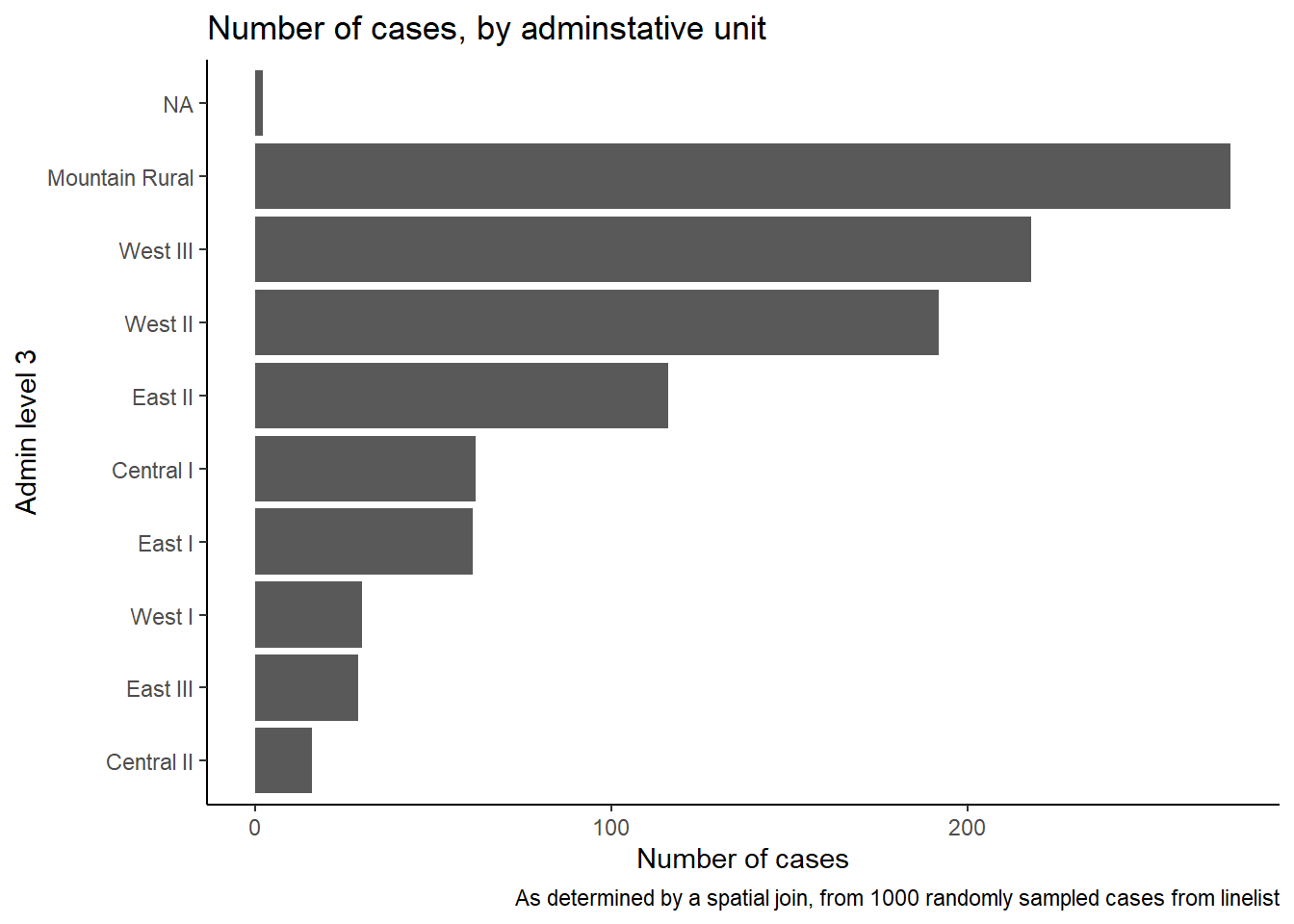
case_adm3# A tibble: 10 × 3
# Groups: admin3pcod [10]
admin3pcod admin3name cases
<chr> <chr> <int>
1 SL040102 Mountain Rural 274
2 SL040208 West III 218
3 SL040207 West II 192
4 SL040204 East II 116
5 SL040201 Central I 62
6 SL040203 East I 61
7 SL040206 West I 30
8 SL040205 East III 29
9 SL040202 Central II 16
10 <NA> <NA> 2Мы также можем создать столбчатую диаграмму количества случаев по административным единицам.
В этом примере мы начнем ggplot() с linelist_adm, чтобы мы могли применить функции факторов, такие как fct_infreq(), которая упорядочивает столбцы по частоте (см. советы на странице [Факторы]).
ggplot(
data = linelist_adm, # начинаем с построчного списка, содержащего информацию об административной единице
mapping = aes(
x = fct_rev(fct_infreq(admin3name))))+ # ось x - административные единицы, упорядоченные по частоте (в обратном порядке)
geom_bar()+ # создаем столбцы, высота - количество строк
coord_flip()+ # меняем местами оси X и Y, чтобы легче читать административные единицы
theme_classic()+ # упрощаем фон
labs( # заголовки и подписи
x = "Admin level 3",
y = "Number of cases",
title = "Number of cases, by adminstative unit",
caption = "As determined by a spatial join, from 1000 randomly sampled cases from linelist"
)
Ближайшие соседи
Поиск ближайшей медицинской организации/участка прикрепления
Может быть полезным узнать, где расположены медицинские организации относительно очагов заболевания.
Мы можем использовать метод соединения st_nearest_feature из функции st_join() (пакет sf), чтобы визуализировать ближайшую к отдельным случаям медицинскую организацию.
- Мы начинаем с построчного списка с шейп-файлом
linelist_sf
- Мы пространственно соединяем с помощью
sle_hf, то есть с расположениями медицинских организаций и клиник (точки)
# Ближайшая медицинская организация к каждому случаю
linelist_sf_hf <- linelist_sf %>% # начинаем с шейп-файла с построчным списком
st_join(sle_hf, join = st_nearest_feature) %>% # данные о ближайшей клинике соединяются с данными о случаях
select(case_id, osm_id, name, amenity) %>% # сохраняем интересующие столбцы, включая id, имя, тип, а также геометрию, для медицинских организаций
rename("nearest_clinic" = "name") # переименовываем для ясностиНиже мы можем увидеть (первые 50 строк), что у каждого случая теперь есть данные о ближайшей клинике/больнице
Мы можем увидеть, что клиника “Den Clinic” является ближайшей медицинской организацией примерно для ~30% случаев.
# Подсчет случаев по медицинской организации
hf_catchment <- linelist_sf_hf %>% # начинаем с построчного списка, включая данные о ближайшей клинике
as.data.frame() %>% # конвертируем из шейп-файла в датафрейм
count(nearest_clinic, # считаем строки по "имени" (клиники)
name = "case_n") %>% # присваиваем новому столбцу с подсчетом имя "case_n"
arrange(desc(case_n)) # сортируем в порядке уменьшения
hf_catchment # выводим на консоль nearest_clinic case_n
1 Den Clinic 355
2 Shriners Hospitals for Children 316
3 GINER HALL COMMUNITY HOSPITAL 173
4 panasonic 55
5 Princess Christian Maternity Hospital 38
6 ARAB EGYPT CLINIC 29
7 <NA> 18
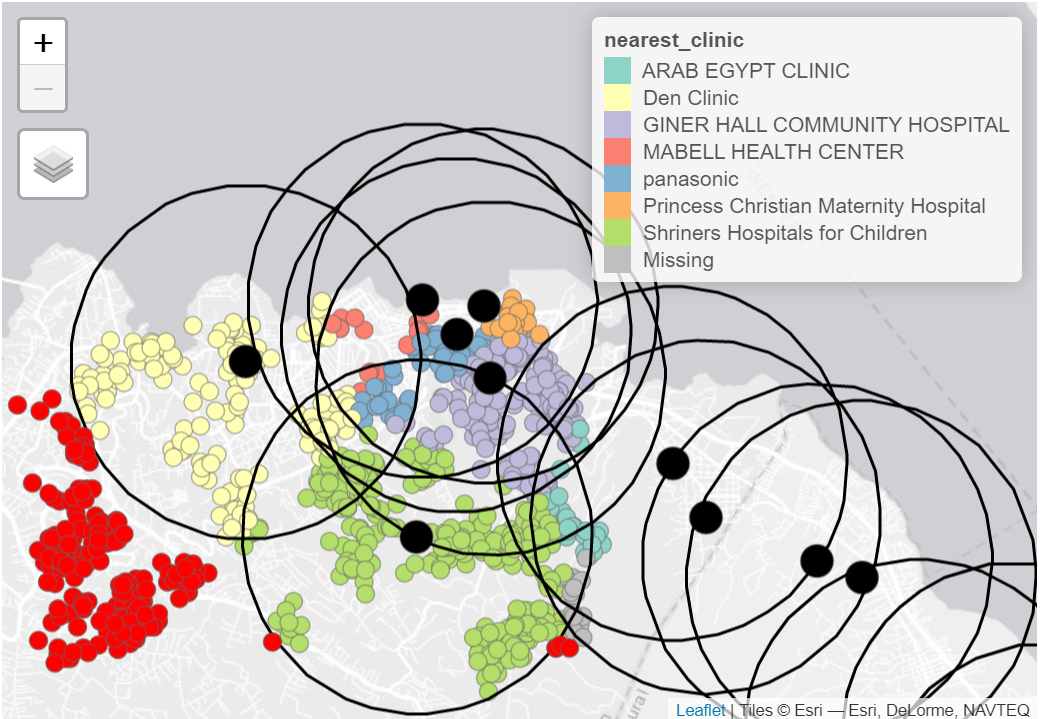
8 MABELL HEALTH CENTER 16Чтобы визуализировать результаты, мы можем использовать tmap - в этот раз в интерактивном режиме для облегчения просмотра
tmap_mode("view") # устанавливаем режим tmap на интерактивный
# строим визуализацию случаев и точек клиник
tm_shape(linelist_sf_hf) + # визуализируем случаи
tm_dots(size=0.08, # случаи окрашены по ближайшей клинике
col='nearest_clinic') +
tm_shape(sle_hf) + # визуализируем медицинские организации большими черными точками
tm_dots(size=0.3, col='black', alpha = 0.4) +
tm_text("name") + # накладываем название организации
tm_view(set.view = c(-13.2284, 8.4699, 13), # корректируем масштаб (центр координат, приближение)
set.zoom.limits = c(13,14))+
tm_layout(title = "Cases, colored by nearest clinic")Буферные зоны
Мы также можем изучить, сколько случаев находятся на расстоянии 2.5 км (~30 минут) ходьбы от ближайшей медицинской организации.
Примечание: Для более точных расчетов расстояний лучше перепроецировать объект sf в соответствующую местную систему картографических проекций, например UTM (Земля проецируется на плоскую поверхность). В данном примере для простоты мы будем придерживаться географической системы координат Всемирной геодезической системы (WGS84) (Земля представлена в виде сферической/круглой поверхности, поэтому единицы измерения - десятичные градусы). Мы будем использовать общее преобразование: 1 десятичный градус = ~111 км.
См. дополнительную информацию о проекциях карт и системах координат в этой статье esri. В этом блоге рассказывается о разных типах проекций карт и о том, как выбирать подходящую проекцию в зависимости от интересующего района и контекста вашей карты/анализа.
Сначала, создаем круговой буфер с радиусом ~2.5 км вокруг каждой медицинской организации. Это делается с помощью функции st_buffer() из tmap. Поскольку единица карты - десятичные градусы широты/долготы, так интерпретируется “0.02”. Если ваша система координат карты в метрах, надо задавать число в метрах.
sle_hf_2k <- sle_hf %>%
st_buffer(dist=0.02) # десятичные градусы, примерно соответствующие 2.5 км Ниже мы строим сами буферные зоны следующим образом:
tmap_mode("plot")
# создаем круговые буферы
tm_shape(sle_hf_2k) +
tm_borders(col = "black", lwd = 2)+
tm_shape(sle_hf) + # визуализируем медицинские организации большими красными точками
tm_dots(size=0.3, col='black') 
**Во-вторых, мы ищем пересечение этих буферов со случаями (точками), используя st_join() с типом соединения st_intersects*. То есть данные о буферах присоединяются к точкам, с которыми они пересекаются.
# пересечение случаев с буферами
linelist_sf_hf_2k <- linelist_sf_hf %>%
st_join(sle_hf_2k, join = st_intersects, left = TRUE) %>%
filter(osm_id.x==osm_id.y | is.na(osm_id.y)) %>%
select(case_id, osm_id.x, nearest_clinic, amenity.x, osm_id.y)Теперь мы можем посчитать результаты: nrow(linelist_sf_hf_2k[is.na(linelist_sf_hf_2k$osm_id.y),]) из 1000 случаев не пересекаются ни с одним буфером (это значение отсутствует), то есть живут дальше, чем 30 минут ходьбы от ближайшей медицинской организации.
# Случаи, у которых нет пересечения с буферами медицинских организаций
linelist_sf_hf_2k %>%
filter(is.na(osm_id.y)) %>%
nrow()[1] 1000Мы можем визуализировать результаты таким образом, чтобы случаи, не пересекающиеся с буфером, отражались красным.
tmap_mode("view")
# Сначала отобразим случаи точками
tm_shape(linelist_sf_hf) +
tm_dots(size=0.08, col='nearest_clinic') +
# визуализируем медицинские организации большими черными точками
tm_shape(sle_hf) +
tm_dots(size=0.3, col='black')+
# затем наложим буферы медицинских организаций полилиниями
tm_shape(sle_hf_2k) +
tm_borders(col = "black", lwd = 2) +
# выделим случаи, которые не попали в буферы ни одной медицинской организации
# красными точками
tm_shape(linelist_sf_hf_2k %>% filter(is.na(osm_id.y))) +
tm_dots(size=0.1, col='red') +
tm_view(set.view = c(-13.2284,8.4699, 13), set.zoom.limits = c(13,14))+
# добавим заголовок
tm_layout(title = "Cases by clinic catchment area")Другие пространственные соединения
Альтернативные значения для аргумента join включают (из документации)
- st_contains_properly
- st_contains
- st_covered_by
- st_covers
- st_crosses
- st_disjoint
- st_equals_exact
- st_equals
- st_is_within_distance
- st_nearest_feature
- st_overlaps
- st_touches
- st_within
28.7 Картограммы
Картограммы могут быть полезны для визуализации данных по заранее определенным областям, обычно административным единицам или районам здравоохранения. Например, при реагировании на вспышки заболеваний это может помочь целенаправленно распределять ресурсы для конкретных районов с высоким уровнем заболеваемости.
Теперь, когда у нас присвоены названия административных единиц для всех случаев (см. раздел пространственные соединения выше), мы можем начать составлять карту количества случаев по району (картограмму).
Поскольку у нас также есть данные по населению для ADM3, мы можем добавить эту информацию к таблице case_adm3, созданной ранее.
Мы начинаем с датафрейма, созданного на предыдущем шаге case_adm3, который является суммарной таблицей каждой административной единицы и количества случаев в ней.
- Данные по населению
sle_adm3_popприсоединяются, используя левое соединениеleft_join()из dplyr на основе общих значений по столбцуadmin3pcodдля датафреймаcase_adm3и столбцаadm_pcodeв датафреймеsle_adm3_pop. См. страницу [Соединение данных]).
-
select()применяется к новому датафрейму, чтобы сохранить только нужные столбцы -total- это общее население.
- Случаи на 10,000 человек рассчитываются как новый столбец с помощью
mutate()
# добавляем данные по населению и рассчитываем количество случаев на 10 тысяч человек
case_adm3 <- case_adm3 %>%
left_join(sle_adm3_pop, # добавляем столбцы из набора данных по населению
by = c("admin3pcod" = "adm3_pcode")) %>% # соединяем на основе общих значений по этим двум столбцам
select(names(case_adm3), total) %>% # сохраняем только важные столбцы, включая общее население
mutate(case_10kpop = round(cases/total * 10000, 3)) # создаем новый столбец с коэффициентом случаев на 10000, с округлением до 3 знаков после запятой
case_adm3 # выподим на консоль для просмотра# A tibble: 10 × 5
# Groups: admin3pcod [10]
admin3pcod admin3name cases total case_10kpop
<chr> <chr> <int> <int> <dbl>
1 SL040102 Mountain Rural 274 33993 80.6
2 SL040208 West III 218 210252 10.4
3 SL040207 West II 192 145109 13.2
4 SL040204 East II 116 99821 11.6
5 SL040201 Central I 62 69683 8.90
6 SL040203 East I 61 68284 8.93
7 SL040206 West I 30 60186 4.99
8 SL040205 East III 29 500134 0.58
9 SL040202 Central II 16 23874 6.70
10 <NA> <NA> 2 NA NA Соединяем эту таблицу с шейп-файлом полигонов ADM3 для картирования
case_adm3_sf <- case_adm3 %>% # начинаем со случаев и коэффициента по административной единице
left_join(sle_adm3, by="admin3pcod") %>% # соединяем с данными шейп-файла по общему столбцу
select(objectid, admin3pcod, # сохраняем только некоторые интересующие столбцы
admin3name = admin3name.x, # вычищаем имя одного столбца
admin2name, admin1name,
cases, total, case_10kpop,
geometry) %>% # сохраняем геометрию, чтобы можно было визуализировать полигоны
drop_na(objectid) %>% # удаляем пустые строки
st_as_sf() # конвертируем в шейп-файлСоставляем карту результатов
# режим tmap
tmap_mode("plot") # просмотр статической карты
# plot polygons
tm_shape(case_adm3_sf) +
tm_polygons("cases") + # цвет по столбцу количества случаев
tm_text("admin3name") # отображаем имя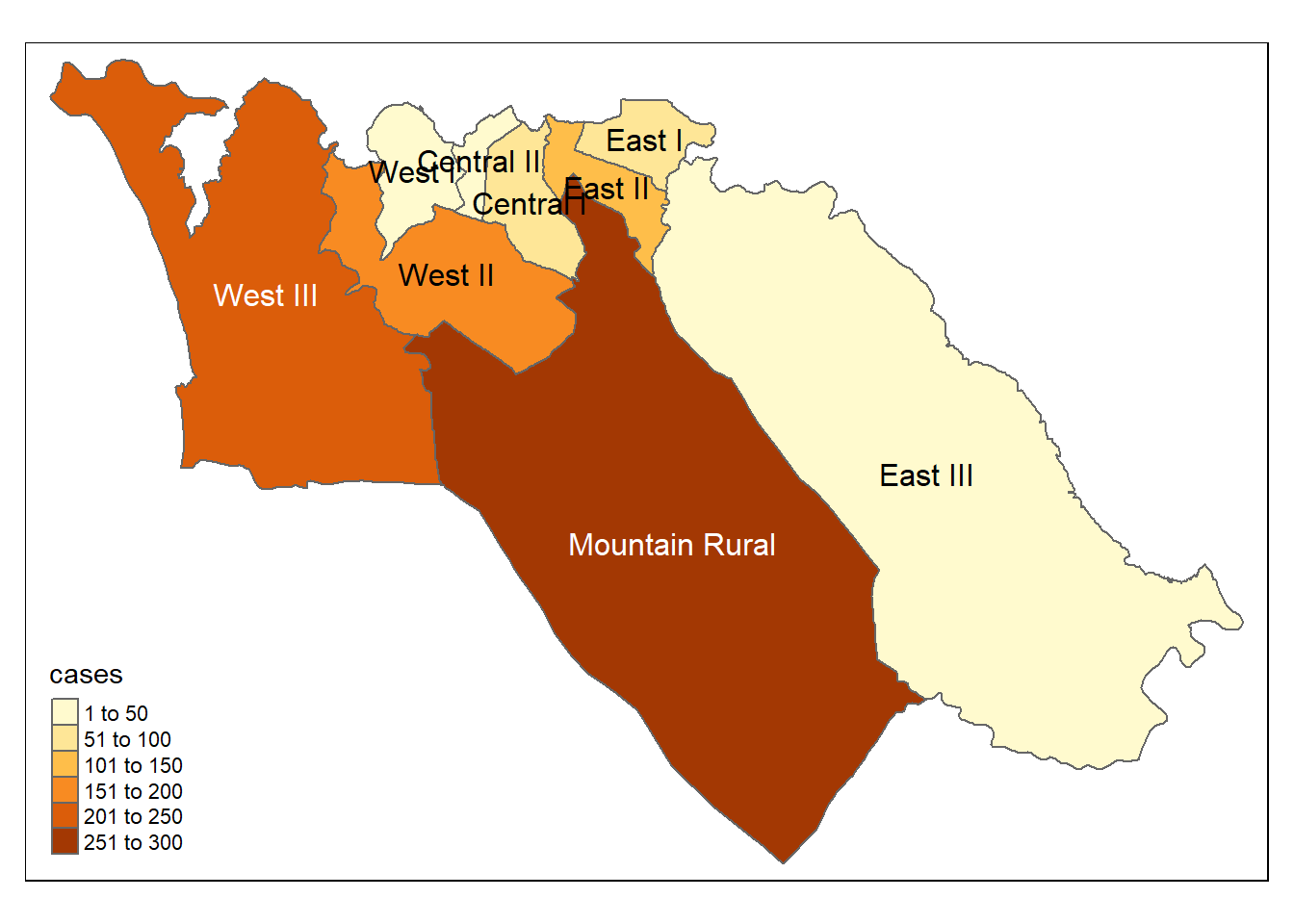
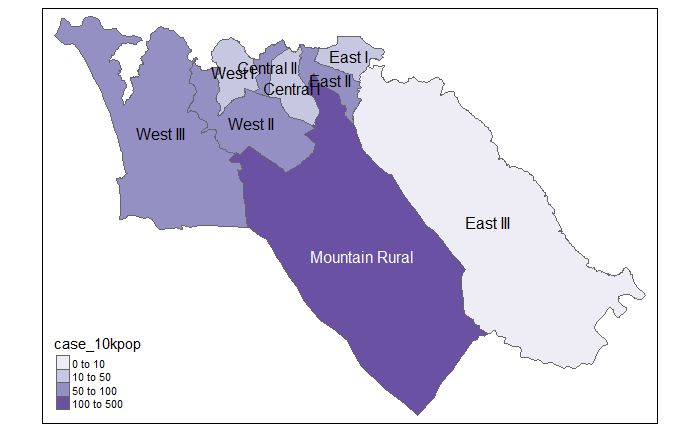
Мы также можем составить карту коэффициента заболеваемости
# Случаи на 10 тысяч человек
tmap_mode("plot") # режим статического просмотра
# plot
tm_shape(case_adm3_sf) + # визуализируем полигоны
tm_polygons("case_10kpop", # цвет по столбцу, содержащему коэффициент случаев
breaks=c(0, 10, 50, 100), # определяем точки перехода для цветов
palette = "Purples" # используем фиолетовую цветовую палитру
) +
tm_text("admin3name") # отображаем текст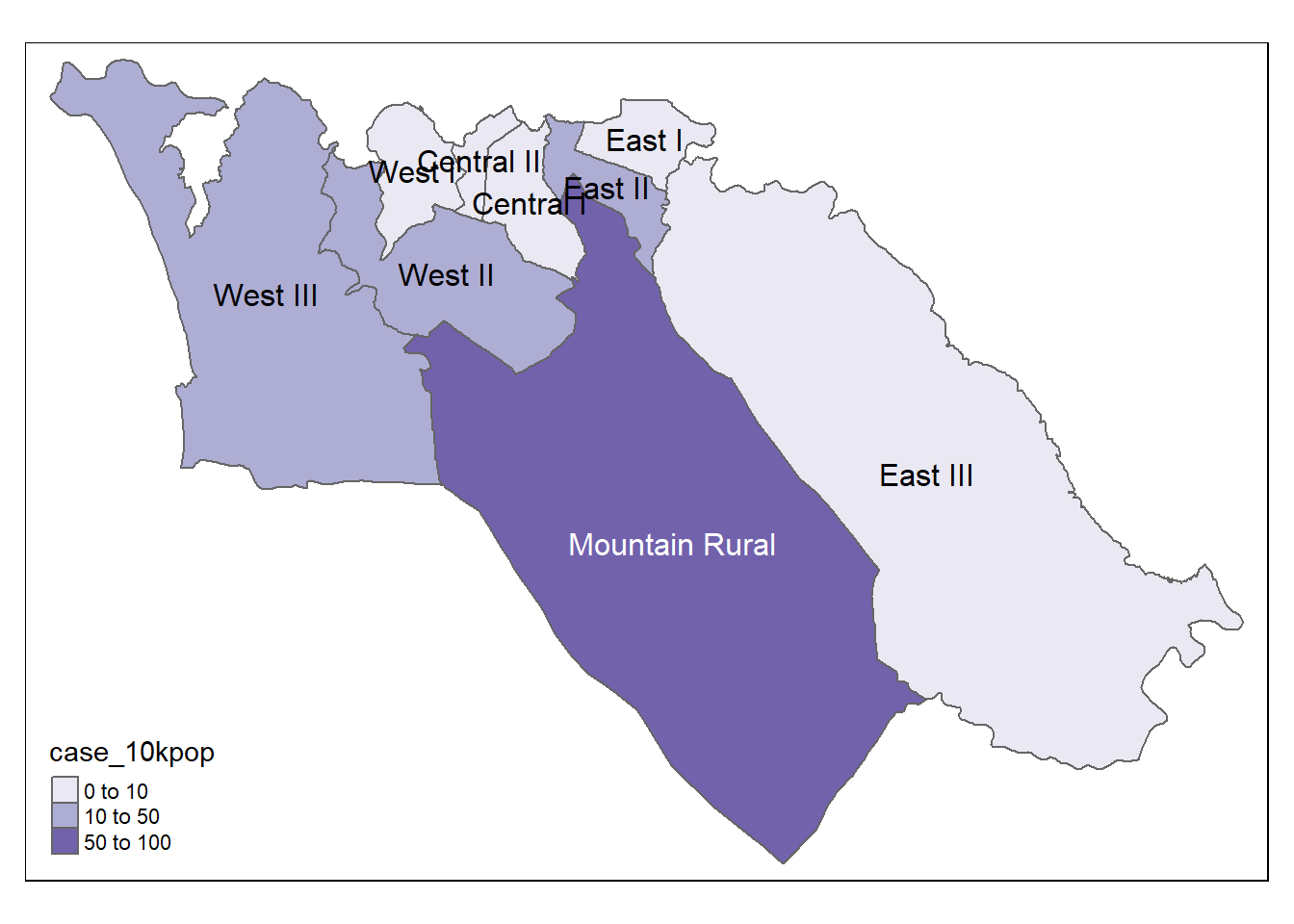
28.8 Составление карт с помощью ggplot2
Если вы уже знакомы с применением ggplot2, вы можете использовать этот пакет для создания статических карт ваших данных. Функция geom_sf() нарисует разные объекты на основе того, какие свойства (точки, линии, полигоны) есть в ваших данных. Например, вы можете использовать geom_sf() в ggplot(), используя данные sf с геометрией полигонов для создания картограммы.
Чтобы иллюстрировать как это работает, мы можем начать с шейп-файла полигонов ADM3, который мы использовали ранее. Вспомните, что это регионы уровня Admin 3 в Сьерра-Леоне:
sle_adm3Simple feature collection with 12 features and 19 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -13.29894 ymin: 8.094272 xmax: -12.91333 ymax: 8.499809
Geodetic CRS: WGS 84
# A tibble: 12 × 20
objectid admin3name admin3pcod admin3ref_n admin2name admin2pcod admin1name
* <dbl> <chr> <chr> <chr> <chr> <chr> <chr>
1 155 Koya Rural SL040101 Koya Rural Western A… SL0401 Western
2 156 Mountain Ru… SL040102 Mountain R… Western A… SL0401 Western
3 157 Waterloo Ru… SL040103 Waterloo R… Western A… SL0401 Western
4 158 York Rural SL040104 York Rural Western A… SL0401 Western
5 159 Central I SL040201 Central I Western A… SL0402 Western
6 160 East I SL040203 East I Western A… SL0402 Western
7 161 East II SL040204 East II Western A… SL0402 Western
8 162 Central II SL040202 Central II Western A… SL0402 Western
9 163 West III SL040208 West III Western A… SL0402 Western
10 164 West I SL040206 West I Western A… SL0402 Western
11 165 West II SL040207 West II Western A… SL0402 Western
12 167 East III SL040205 East III Western A… SL0402 Western
# ℹ 13 more variables: admin1pcod <chr>, admin0name <chr>, admin0pcod <chr>,
# date <date>, valid_on <date>, valid_to <date>, shape_leng <dbl>,
# shape_area <dbl>, rowcacode0 <chr>, rowcacode1 <chr>, rowcacode2 <chr>,
# rowcacode3 <chr>, geometry <MULTIPOLYGON [°]>Мы можем использовать функцию left_join() из dplyr, чтобы добавить данные, которые мы хотели бы отразить на карте, к объекту шейп-файла. В данном случае мы будем использовать датафрейм case_adm3, который мы создали ранее, для обобщения количества случаев по административному региону; однако, мы можем использовать тот же подход, чтобы составить карту любых данных, сохраненных в датафрейме.
sle_adm3_dat <- sle_adm3 %>%
inner_join(case_adm3, by = "admin3pcod") # внутреннее соединение = сохранить только если присутствует в обоих объектах данных
select(sle_adm3_dat, admin3name.x, cases) # выводим выбранные переменные на консольSimple feature collection with 9 features and 2 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -13.29894 ymin: 8.384533 xmax: -13.12612 ymax: 8.499809
Geodetic CRS: WGS 84
# A tibble: 9 × 3
admin3name.x cases geometry
<chr> <int> <MULTIPOLYGON [°]>
1 Mountain Rural 274 (((-13.21496 8.474341, -13.21479 8.474289, -13.21465 8.4…
2 Central I 62 (((-13.22646 8.489716, -13.22648 8.48955, -13.22644 8.48…
3 East I 61 (((-13.2129 8.494033, -13.21076 8.494026, -13.21013 8.49…
4 East II 116 (((-13.22653 8.491883, -13.22647 8.491853, -13.22642 8.4…
5 Central II 16 (((-13.23154 8.491768, -13.23141 8.491566, -13.23144 8.4…
6 West III 218 (((-13.28529 8.497354, -13.28456 8.496497, -13.28403 8.4…
7 West I 30 (((-13.24677 8.493453, -13.24669 8.493285, -13.2464 8.49…
8 West II 192 (((-13.25698 8.485518, -13.25685 8.485501, -13.25668 8.4…
9 East III 29 (((-13.20465 8.485758, -13.20461 8.485698, -13.20449 8.4…Чтобы создать столбчатую диаграмму количества случаев по регионам с помощью ggplot2, мы можем использовать geom_col() следующим образом:
ggplot(data=sle_adm3_dat) +
geom_col(aes(x=fct_reorder(admin3name.x, cases, .desc=T), # меняем порядок на оси x по уменьшению количества случаев ('cases')
y=cases)) + # ось y - количествос лучаев по региону
theme_bw() +
labs( # задаем текст рисунка
title="Number of cases, by administrative unit",
x="Admin level 3",
y="Number of cases"
) +
guides(x=guide_axis(angle=45)) # подписи на оси x под углом 45 градусов, чтобы они вошли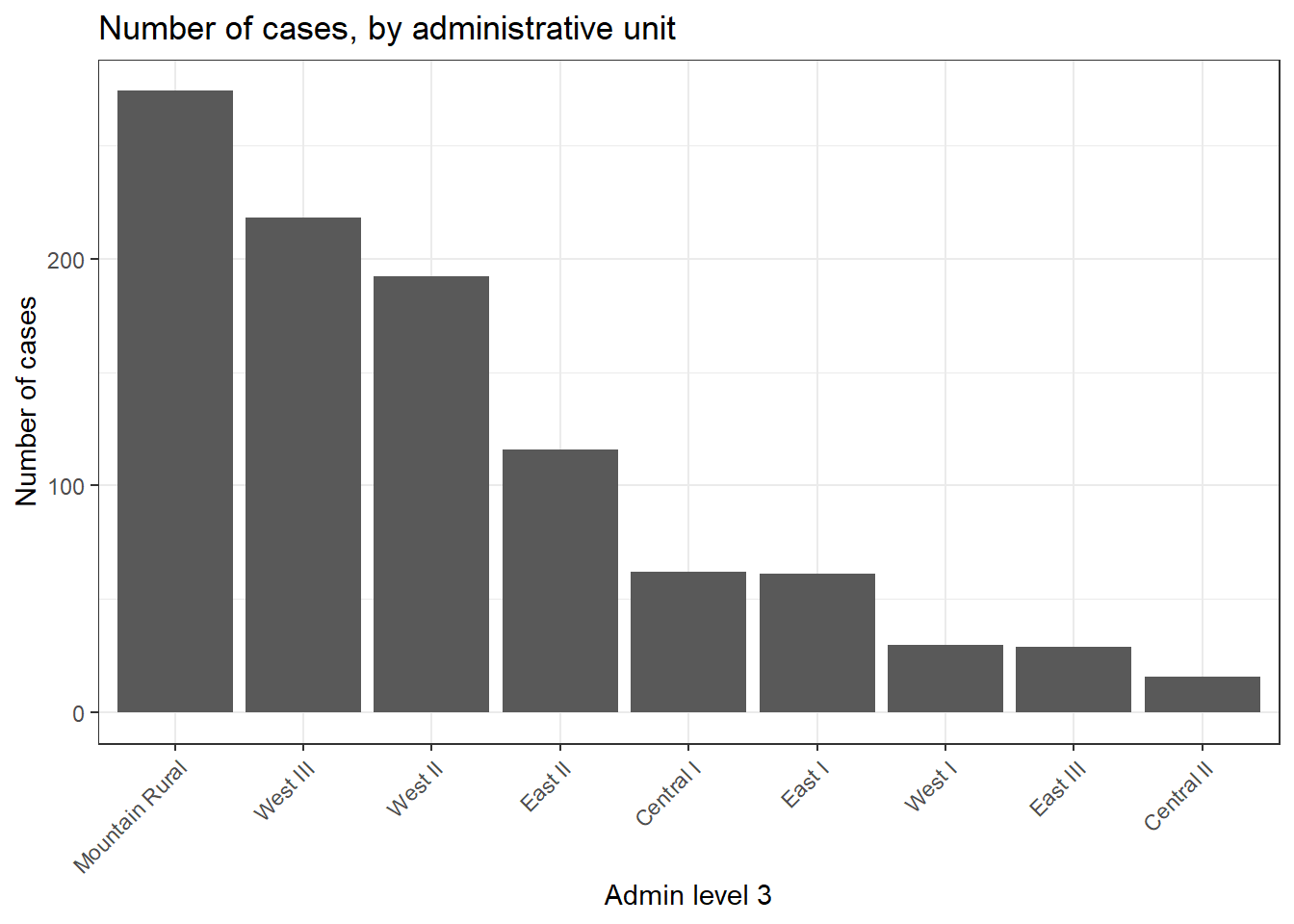
Если мы хотим использовать ggplot2 для создания картограммы количества случаев, мы используем синтаксис, похожий на функцию geom_sf():
ggplot(data=sle_adm3_dat) +
geom_sf(aes(fill=cases)) # устанавливаем заливку с изменением в зависимости от переменной количества случаев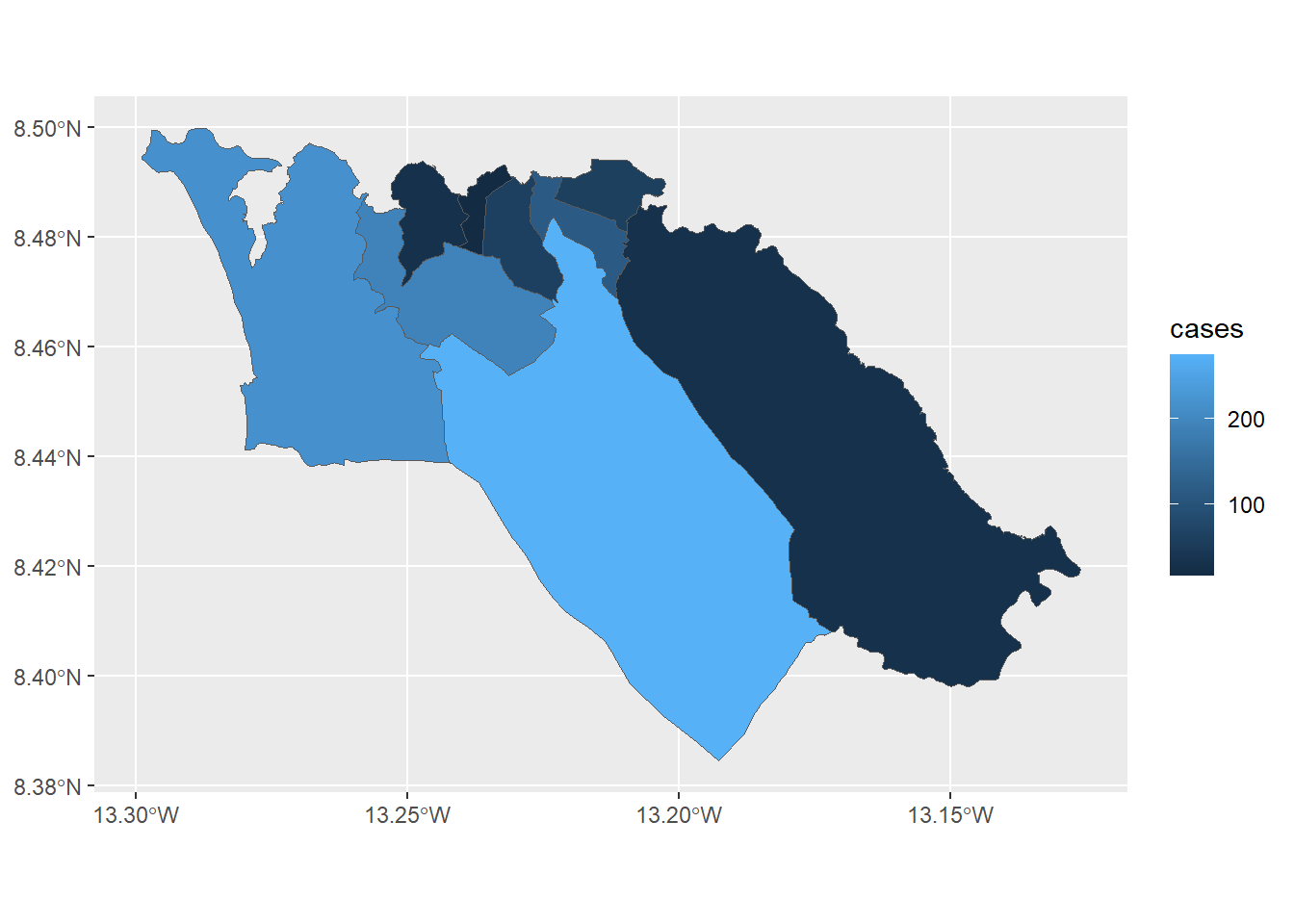
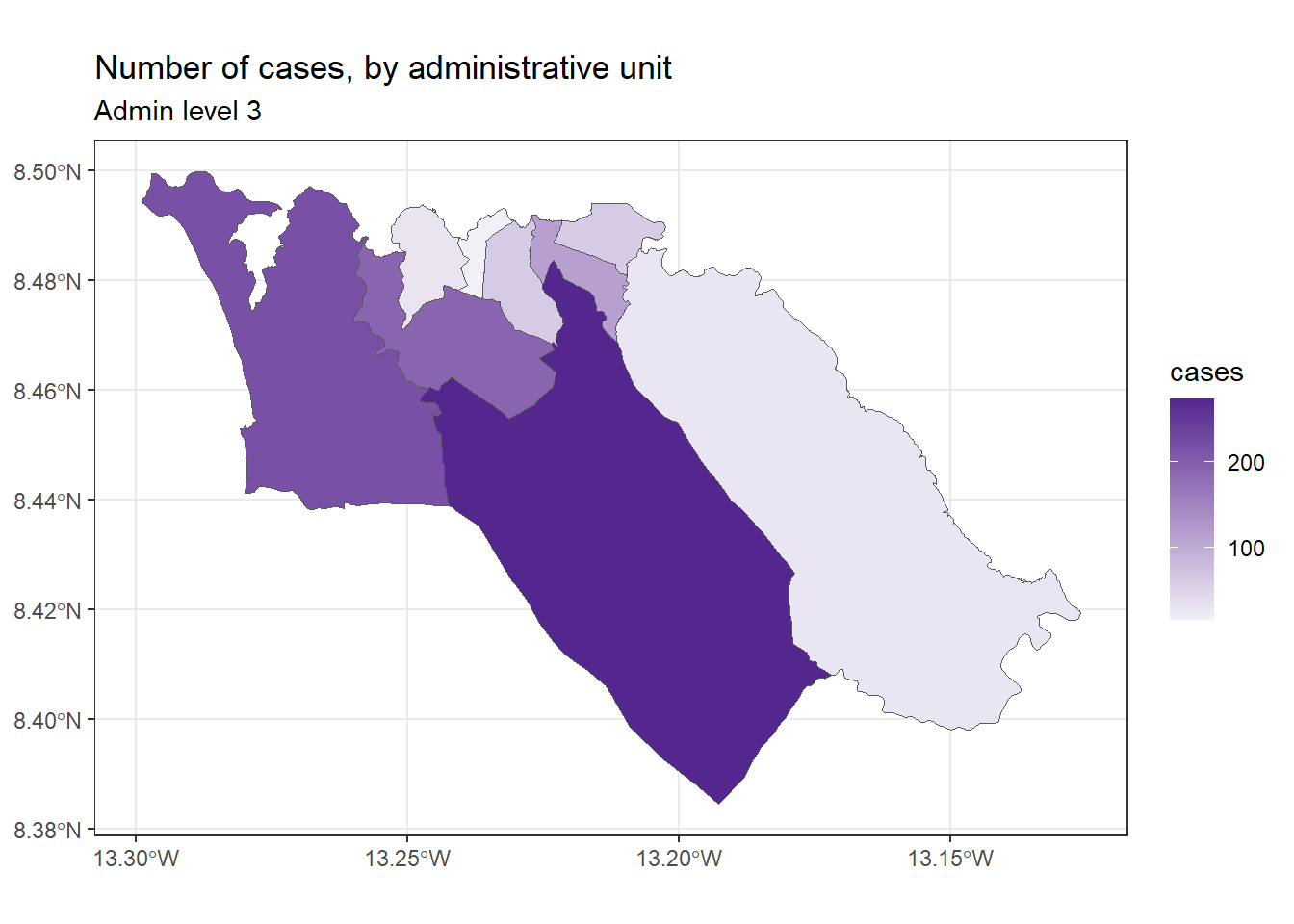
Затем мы можем индивидуализировать отображение нашей карты, используя грамматику, которая применяется единообразно в ggplot2, например:
ggplot(data=sle_adm3_dat) +
geom_sf(aes(fill=cases)) +
scale_fill_continuous(high="#54278f", low="#f2f0f7") + # изменяем градиент цветов
theme_bw() +
labs(title = "Number of cases, by administrative unit", # задаем текст рисунка
subtitle = "Admin level 3"
)
Для пользователй R, которые комфортно себя чувствуют при работе с ggplot2, geom_sf() предлагает простую и прямую реализацию, которая подходит для визуализации базовых карт. Чтобы узнать детали, прочитайте виньетку по geom_sf() или учебник по ggplot2.
28.9 Карты-основы
OpenStreetMap
Ниже мы опишем, как получить карту-основу для карты ggplot2, используя характеристики OpenStreetMap. Альтернативные методы включают использование ggmap, который требует бесплатной регистрации в Google (детали).
OpenStreetMap - это совместный проект по созданию бесплатной редактируемой карты мира. Основным результатом проекта являются геолокационные данные (например, расположение городов, дорог, природных объектов, аэропортов, школ, больниц, дорог и т.д.).
Сначала мы загрузим пакет OpenStreetMap, из которого мы получим карту-основу.
Затем мы создаем объект map, который мы определяем, используя функцию openmap() из пакета OpenStreetMap (документация). Мы указываем следующее:
-
upperLeftиlowerRightДве пары координат, уточняющие пределы плитки карты-основы- В данном случае мы указываем максимум и минимум из строк построчного списка, чтобы карта динамически реагировала на данные
- В данном случае мы указываем максимум и минимум из строк построчного списка, чтобы карта динамически реагировала на данные
-
zoom =(если не задано, то определяется автоматически)
-
type =какой тип карты-основы - мы указали тут ряд возможностей и код сейчас использует первую ([1]) “osm”
-
mergeTiles =мы выбираем TRUE (ИСТИНА), чтобы плитки карты-основы были объединены в одну
# загружаем пакет
pacman::p_load(OpenStreetMap)
# Строим карту-основу по диапазону координат долготы/широты. Выбираем тип плиток
map <- OpenStreetMap::openmap(
upperLeft = c(max(linelist$lat, na.rm=T), max(linelist$lon, na.rm=T)), # пределы плитки карты-основы
lowerRight = c(min(linelist$lat, na.rm=T), min(linelist$lon, na.rm=T)),
zoom = NULL,
type = c("osm", "stamen-toner", "stamen-terrain", "stamen-watercolor", "esri","esri-topo")[1])Если мы визуализируем сейчас эту карту-основу, используя autoplot.OpenStreetMap() из пакета OpenStreetMap, вы увидите, что единицы на осях не являются координатами широты/долготы. Используется другая система координат. Чтобы правильно отобразить места проживания случаев (которые отражены в виде широты/долготы), это нужно изменить.
autoplot.OpenStreetMap(map)
Таким образом, нам нужно конвертировать карту в широту/долготу с помощью функции openproj() из пакета OpenStreetMap. Мы задаем карту-основу map и также задаем Референсную систему координат (РСК), которая нам нужна. Мы это делаем с помощью текстовой последовательности “proj.4” для проекции WGS 1984, но вы можете задать РСК и другими способами. (см. эту страницу, чтобы понять, что такое последовательность proj.4)
# Проекция WGS84
map_latlon <- openproj(map, projection = "+proj=longlat +ellps=WGS84 +datum=WGS84 +no_defs")Теперь, когда мы создаем график, мы видим на осях координаты широты и долготы. Система координат была конвертирована. Теперь случаи будут наложены верно!
# Строим карту. Необходимо использовать "autoplot", чтобы работать с ggplot
autoplot.OpenStreetMap(map_latlon)
28.10 Контурные карты плотности
Ниже мы описываем, как получить конторную карту плотности поверх карты-основы, начиная с построчного списка (по одной строке на случай).
- Создаем плитку карты-основы из OpenStreetMap, как описано выше
- Визуализируем случаи из
linelist, используя столбцы широты и долготы
- Конвертируем точки в тепловую карту плотности с помощью
stat_density_2d()из ggplot2,
Когда у нас имеется карта-основа с координатами широты/долготы, мы можем отразить сверху нее случая, используя координаты широты/долготы их места проживания.
На основе функции autoplot.OpenStreetMap() для создания карты-основы, функции ggplot2 будут наложены сверху, как это сделано с помощью geom_point() ниже:
# Строим карту. Необходимо использовать autoplot, чтобы работать с ggplot
autoplot.OpenStreetMap(map_latlon)+ # начинаем с карты-основы
geom_point( # aдобавляем точки xy из столбцов широты и долготы построчного списка
data = linelist,
aes(x = lon, y = lat),
size = 1,
alpha = 0.5,
show.legend = FALSE) + # полностью убираем легенду
labs(x = "Longitude", # заголовки и подписи
y = "Latitude",
title = "Cumulative cases")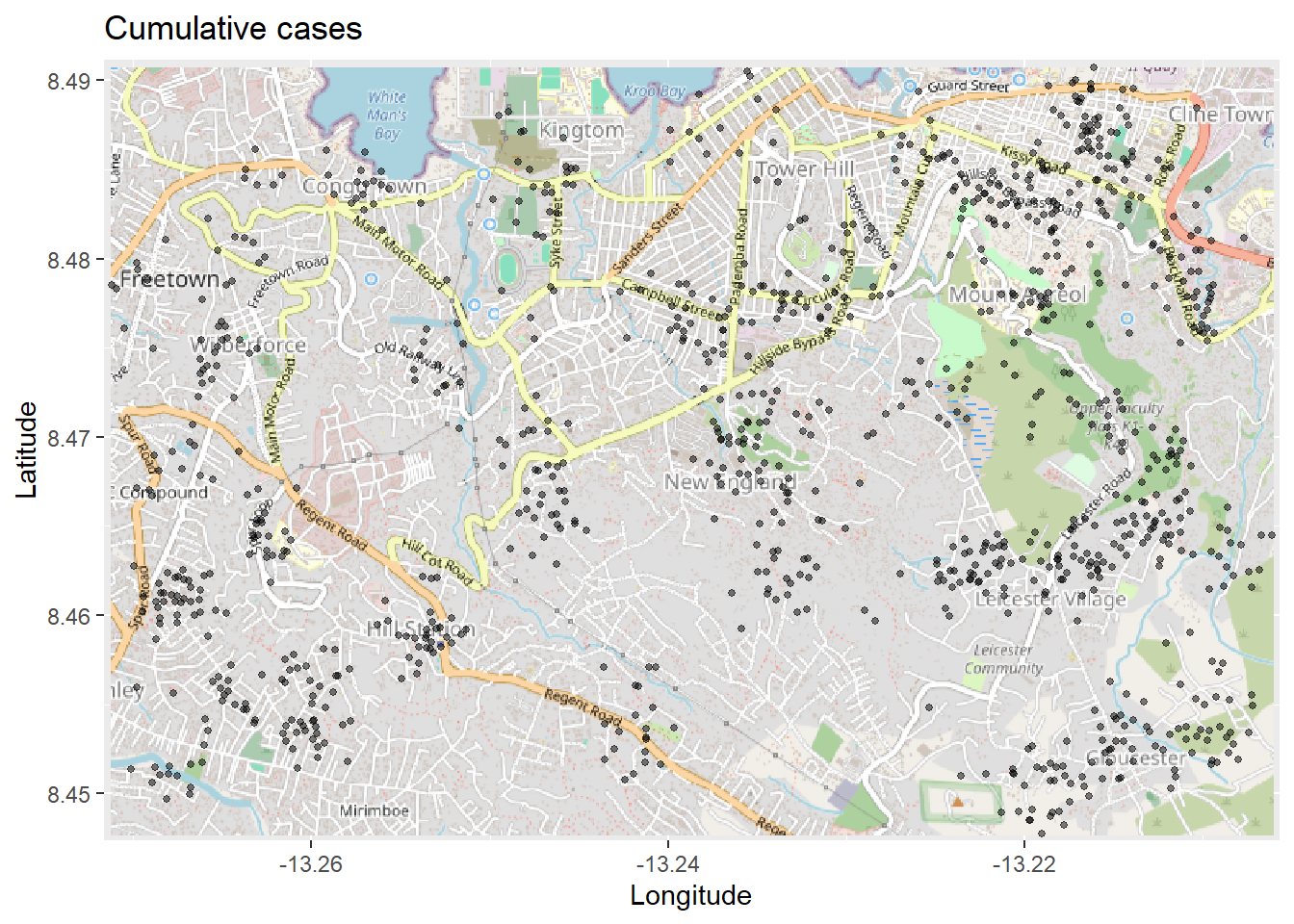
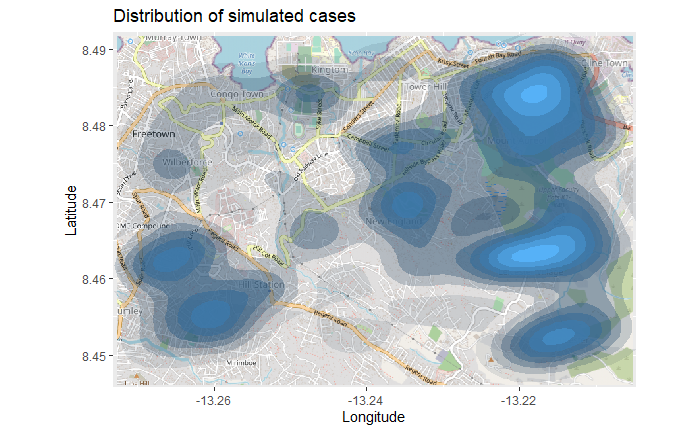
Карту, созданную выше, может быть сложно интерпретировать, особенно учитывая наложение точек друг на друга. Поэтому вы можете вместо этого создать 2d карту плотности, используя функцию ggplot2 stat_density_2d(). Вы все еще используете координаты широты/долготы из построчного списка, но проводится 2D ядерная оценка плотности и результаты отображаются в виде линий контура - как на топографической карте. Прочитайте полную документацию тут.
# начинаем с карты-основы
autoplot.OpenStreetMap(map_latlon)+
# добавляем график плотности
ggplot2::stat_density_2d(
data = linelist,
aes(
x = lon,
y = lat,
fill = ..level..,
alpha = ..level..),
bins = 10,
geom = "polygon",
contour_var = "count",
show.legend = F) +
# уточняем цветовую шкалу
scale_fill_gradient(low = "black", high = "red")+
# подписи
labs(x = "Longitude",
y = "Latitude",
title = "Distribution of cumulative cases")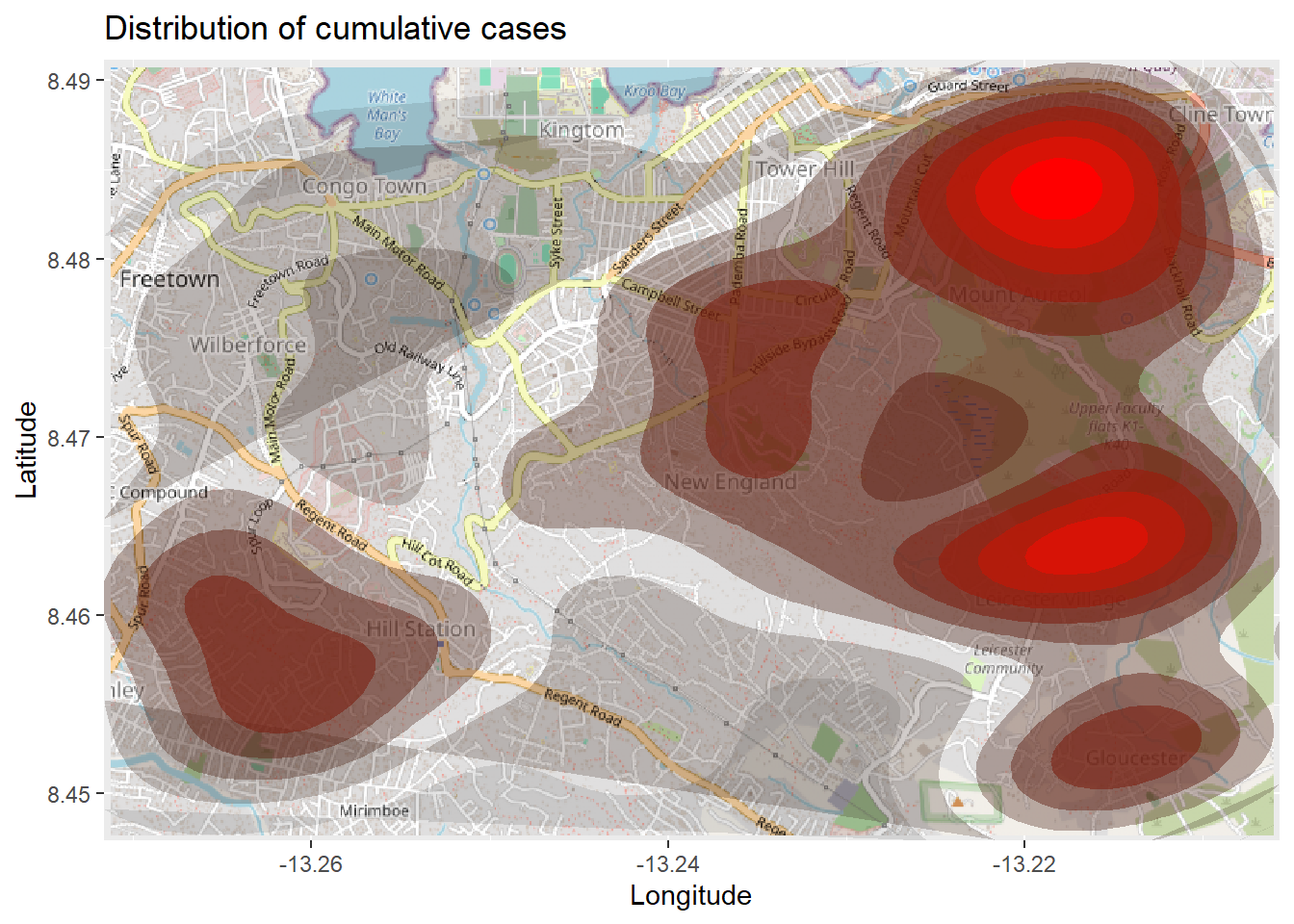
Тепловая карта временных рядов
Тепловая карта плотности выше показывает кумулятивное количество случаев. Мы можем рассмотреть вспышку во времени и пространстве с помощью фасетов тепловой карты на основе месяца возникновения симптомов, который мы можем получить из построчного списка.
Мы начинаем с linelist, создаем новый столбец с годом и месяцм возникновения симптомов. Функция format() из базового R меняет отображение даты. В этом случае нам нужно “ГГГГ-ММ”.
# извлекаем месяц возникновения симптомов
linelist <- linelist %>%
mutate(date_onset_ym = format(date_onset, "%Y-%m"))
# Изучаем значения
table(linelist$date_onset_ym, useNA = "always")
2014-05 2014-06 2014-07 2014-08 2014-09 2014-10 2014-11 2014-12 2015-01 2015-02
15 24 38 77 201 187 136 75 73 50
2015-03 2015-04 <NA>
55 26 43 Теперь мы просто добавим фасеты с помощью ggplot2 на тепловую карту плотности. Применяем facet_wrap(), используя новый столбец как строки. Мы задаем количество столбцов фасета как 3 для ясности.
# пакеты
pacman::p_load(OpenStreetMap, tidyverse)
# начинаем с карты-основы
autoplot.OpenStreetMap(map_latlon)+
# добавляем график плотности
ggplot2::stat_density_2d(
data = linelist,
aes(
x = lon,
y = lat,
fill = ..level..,
alpha = ..level..),
bins = 10,
geom = "polygon",
contour_var = "count",
show.legend = F) +
# уточняем цветовую шкалу
scale_fill_gradient(low = "black", high = "red")+
# подписи
labs(x = "Longitude",
y = "Latitude",
title = "Distribution of cumulative cases over time")+
# фасеты по месяцу-году возникновения симптомов
facet_wrap(~ date_onset_ym, ncol = 4) 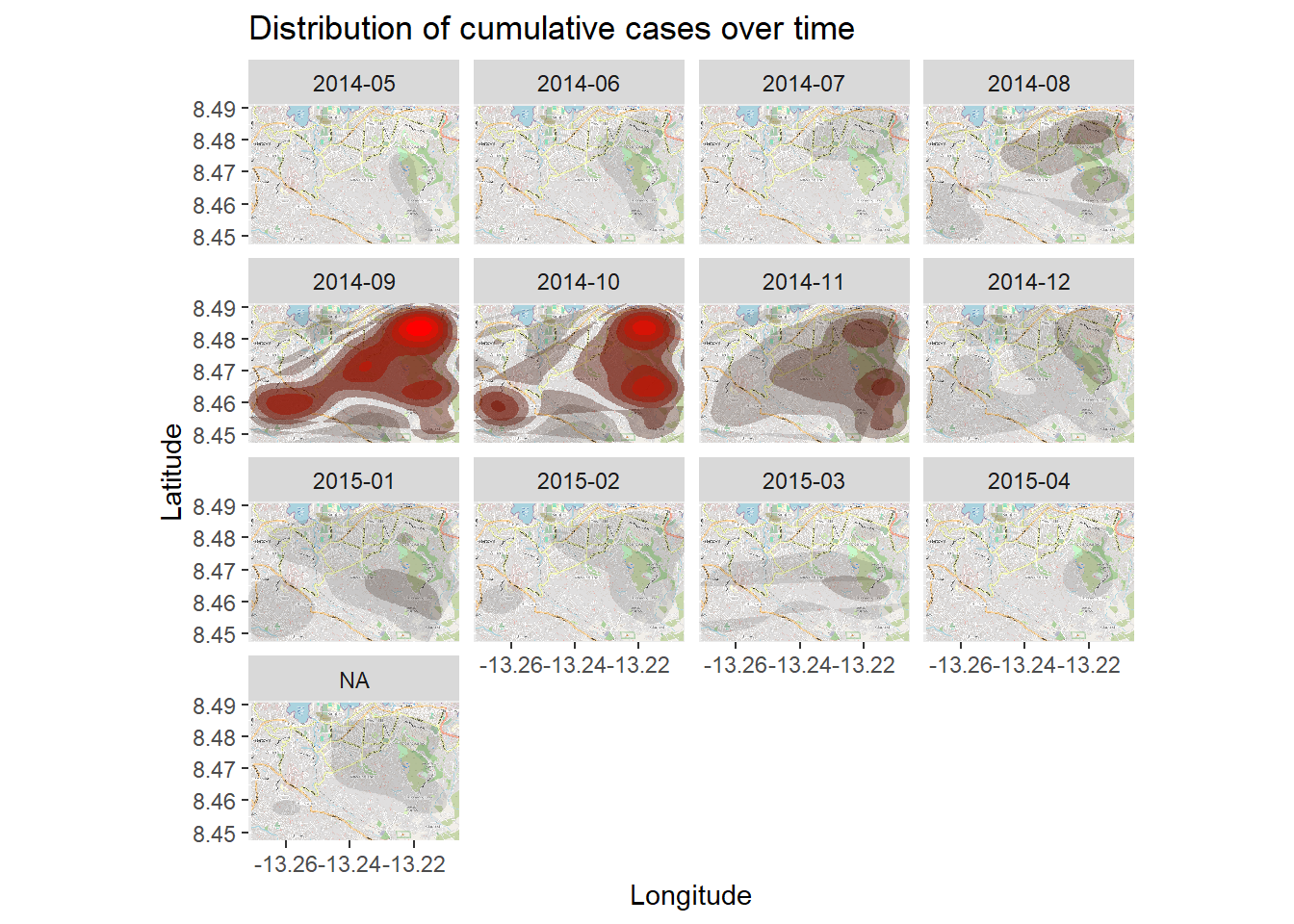
28.11 Пространственная статистика
Наша дискуссия в основном до сих пор фокусировалась на визуализации пространственных данных. В некоторых случаях вас также может интересовать пространственная статистика для количественного отражения пространственных отношений характеристик ваших данных. В этом разделе мы сделаем краткий обзор ключевых концепций в пространственной статистике и порекомендуем некоторые ресурсы, которые могут быть полезны для изучения, если вам нужен более подробный пространственный анализ.
Пространственные отношения
Прежде чем мы сможем рассчитать пространственную статистику, нам нужно уточнить отношения между характеристиками наших данных. Существует много способов концептуализации пространственных отношений, но простой и часто применяемой моделью является Смежность - в частности, что мы ожидаем географические связи между зонами, имеющими общую границу или “соседствующими” друг с другом.
Мы можем количественно выразить отношения смежности между полигонами административных регионов в данных sle_adm3, которые мы использовали, с помощью пакета spdep. Мы уточним смежность ферзя, который означает, что регионы будут соседями, если они имеют как минимум одну общую точку на своих границах. Альтернативой будет смежность ладьи, которая требует, чтобы регионы имели совместную грань - в нашем случаи при полигонах неправильной формы различия не так важны, но в некоторых случаях выбор ферзя или ладьи может иметь большое значение.
sle_nb <- spdep::poly2nb(sle_adm3_dat, queen=T) # создаем соседей
sle_adjmat <- spdep::nb2mat(sle_nb) # создаем матрицу, обобщающую отношения соседства
sle_listw <- spdep::nb2listw(sle_nb) # создаем объект listw (список весов) -- нам он потребуется позже
sle_nbNeighbour list object:
Number of regions: 9
Number of nonzero links: 30
Percentage nonzero weights: 37.03704
Average number of links: 3.333333 round(sle_adjmat, digits = 2) [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9]
1 0.00 0.20 0.00 0.20 0.00 0.2 0.00 0.20 0.20
2 0.25 0.00 0.00 0.25 0.25 0.0 0.00 0.25 0.00
3 0.00 0.00 0.00 0.50 0.00 0.0 0.00 0.00 0.50
4 0.25 0.25 0.25 0.00 0.00 0.0 0.00 0.00 0.25
5 0.00 0.33 0.00 0.00 0.00 0.0 0.33 0.33 0.00
6 0.50 0.00 0.00 0.00 0.00 0.0 0.00 0.50 0.00
7 0.00 0.00 0.00 0.00 0.50 0.0 0.00 0.50 0.00
8 0.20 0.20 0.00 0.00 0.20 0.2 0.20 0.00 0.00
9 0.33 0.00 0.33 0.33 0.00 0.0 0.00 0.00 0.00
attr(,"call")
spdep::nb2mat(neighbours = sle_nb)Напечатанная выше матрица показывает отношения между 9 регионами в наших данных sle_adm3. Балл 0 указывает, что два региона не являются соседями, а любое значение больше 0 указывает на отношение соседства. Значения в матрице значения в матрице шкалируются таким образом, чтобы каждый регион имел суммарный вес строки, равный 1.
A better way to visualize these neighbor relationships is by plotting them:
plot(sle_adm3_dat$geometry) + # строим границы региона
spdep::plot.nb(sle_nb,as(sle_adm3_dat, 'Spatial'), col='grey', add=T) # добавляем отношения соседства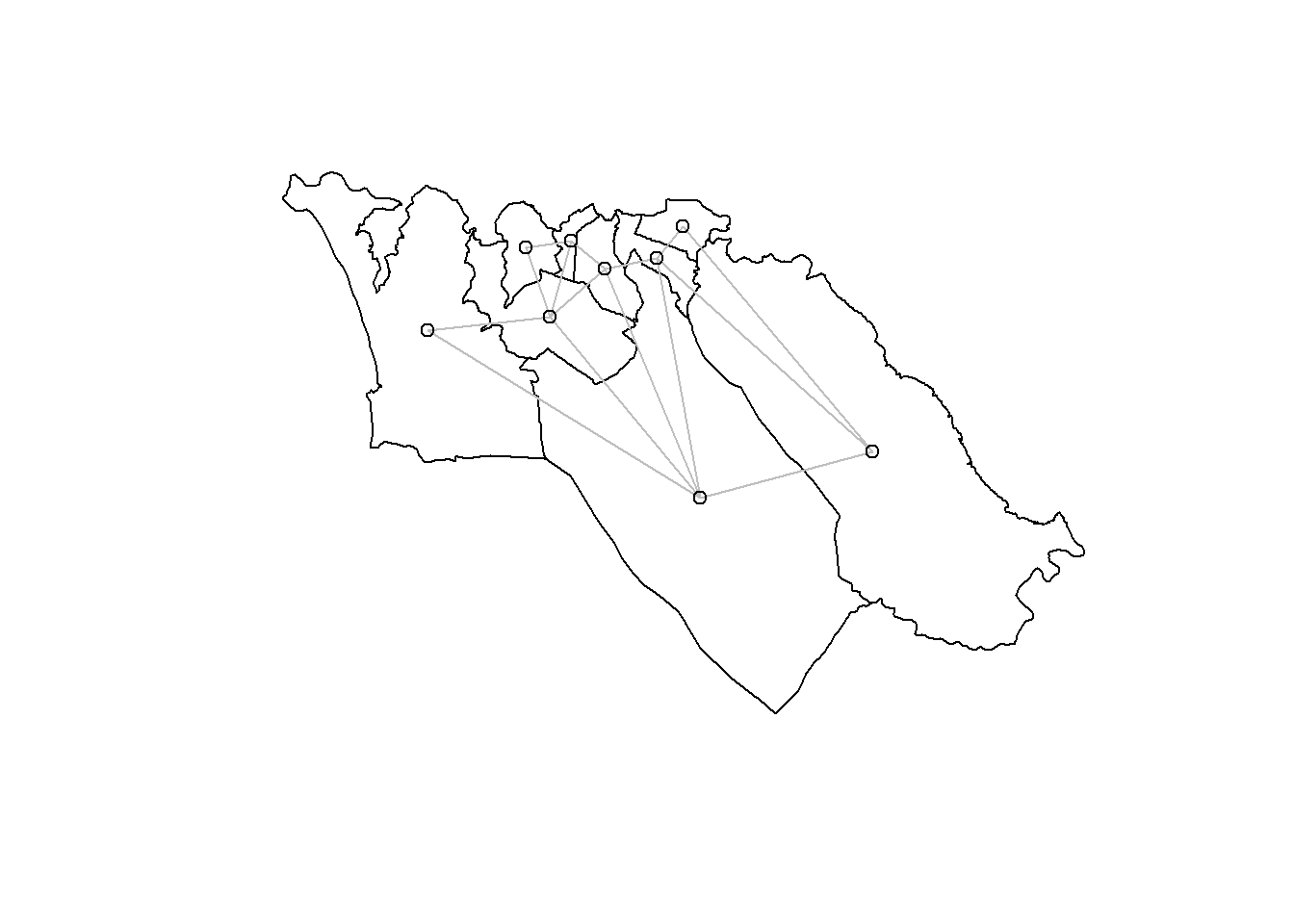
Мы использовали подход смежности, чтобы определить соседние полигоны; были определены соседи, которых также иногда называют соседи на основе смежности. Но это лишь один из способов выбора того, у каких регионов мы ожидаем наличия географических отношений. Одним из частых альтернативных подходов опредлеения географических отношений является соседство на основе расстояния; вкратце, это:
K-ближайшие соседи - основан на расстоянии между центроидами (географически взвешенным центром каждого региона полигона), выбирает n ближайших регионов в качестве соседей. Можно также задать порог максимального расстояния. В spdep вы можете использовать
knearneigh()(см. документацию).Соседи по пороговому расстоянию - выбирает всех соседей в пределах порога расстояния. В spdep такие отношения соседства можно определить с помощью
dnearneigh()(см. документацию).
Пространственная автокорреляция
Часто цитируемый первый закон географии Тоблера гласит: “Все связано со всем остальным, но близкие вещи связаны между собой сильнее, чем далекие”. В эпидемиологии это часто означает, что риск определенного исхода для здоровья в данном регионе более схож с соседними регионами, чем с отдаленными. Эта концепция была закреплена как пространственная автокорреляция - статистическое свойство того, что географические объекты с одинаковыми значениями группируются в пространстве. Статистическая мера пространственной автокорреляции может быть использована для количественного выражения степени пространственной кластеризации ваших данных, поиска мест возникновения кластеров и определения общих закономерностей пространственной автокорреляции между разными переменными в ваших данных. В этом разделе мы сделаем обзор некоторых частых мер пространственной автокорреляции и того, как рассчитать их в R.
I Морана - Это глобальная суммарная статистика корреляции между значением переменной в одном регионе и значениями той же переменной в соседних регионах. Обычно значение статистики I Морана находится в диапазоне от -1 до 1. Значение 0 указывает на отсутствие пространственной корреляции, в то время как значения, близкие к 1 или -1, свидетельствуют о более сильной пространственной автокорреляции (схожие значения близки друг к другу) или пространственной дисперсии (несхожие значения близки друг к другу) соответственно.
Например, мы рассчитаем статистику I Морана, чтобы количественно определить пространственную автокорреляцию случаев Эболы, карту которых мы составляли ранее (помните, что это подмножество случаев из датафрейма с имитированной эпидемией Эболы linelist). В пакете spdep есть функция moran.test, которая может сделать этот расчет для нас:
moran_i <-spdep::moran.test(sle_adm3_dat$cases, # числовой вектор с интересующей переменной
listw=sle_listw) # объект listw, обобщащий отношения соседства
moran_i # печать результатов теста I Морана
Moran I test under randomisation
data: sle_adm3_dat$cases
weights: sle_listw
Moran I statistic standard deviate = 1.558, p-value = 0.05961
alternative hypothesis: greater
sample estimates:
Moran I statistic Expectation Variance
0.20512104 -0.12500000 0.04489437 Результат функции moran.test() показывает нам статистику I Морана round(moran_i$estimate[1],2). Это указывает на наличие пространственной автокорреляции в наших данных - в частности, что регионы со схожим количеством случаев Эболы, вероятно, находятся рядом друг с другом. Значение p, представленное moran.test(), генерируется путем сравнения ожидания при нулевой гипотезе отсутствия пространственной автокорреляции, и может быть использовано, если вам нужно сообщить результаты формального тестирования гипотезы.
Локальный I Морана - Мы можем разложить (глобальную) статистику I Морана, рассчитанную выше, чтобы определить локализованную пространственную автокорреляцию; то есть, чтобы определить конкретные кластеры данных. Эта статистика, которую иногда называют Локальным индикатором пространственной связи (LISA), обобщает степень пространственной автокорреляции вокруг каждого индивидуального региона. Она может быть полезна для выявления “горячих” и “холодных” точек на карте.
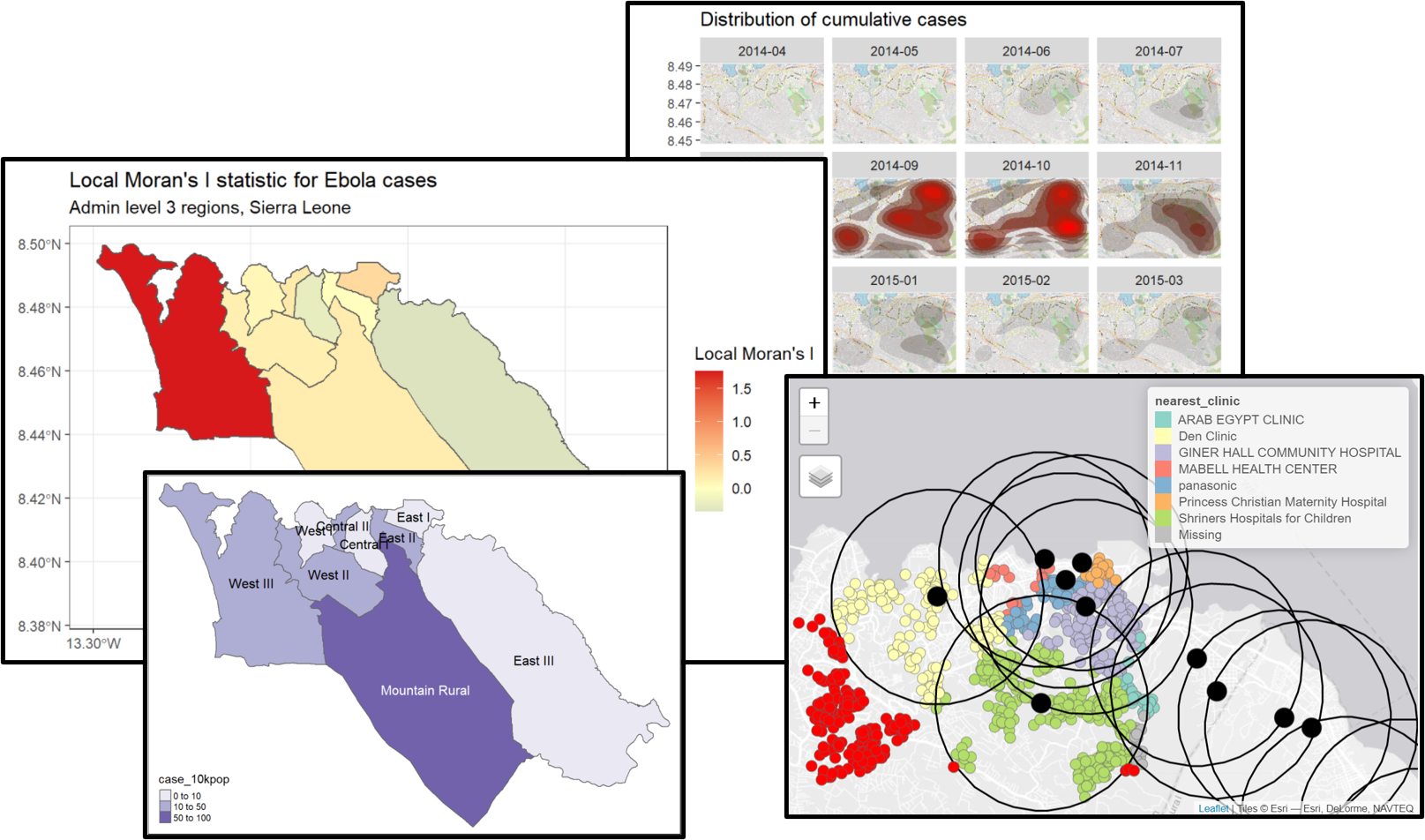
Чтобы показать пример, мы можем рассчитать и отразить на карте Локальный I Морана для количества случаев Эбола, используемых выше, с помощью функции local_moran() из spdep:
# рассчитываем локальный I Морана
local_moran <- spdep::localmoran(
sle_adm3_dat$cases, # интересующая переменная
listw=sle_listw # объект listw с весами для соседей
)
# соединяем результаты с данными sf
sle_adm3_dat<- cbind(sle_adm3_dat, local_moran)
# строим карту
ggplot(data=sle_adm3_dat) +
geom_sf(aes(fill=Ii)) +
theme_bw() +
scale_fill_gradient2(low="#2c7bb6", mid="#ffffbf", high="#d7191c",
name="Local Moran's I") +
labs(title="Local Moran's I statistic for Ebola cases",
subtitle="Admin level 3 regions, Sierra Leone")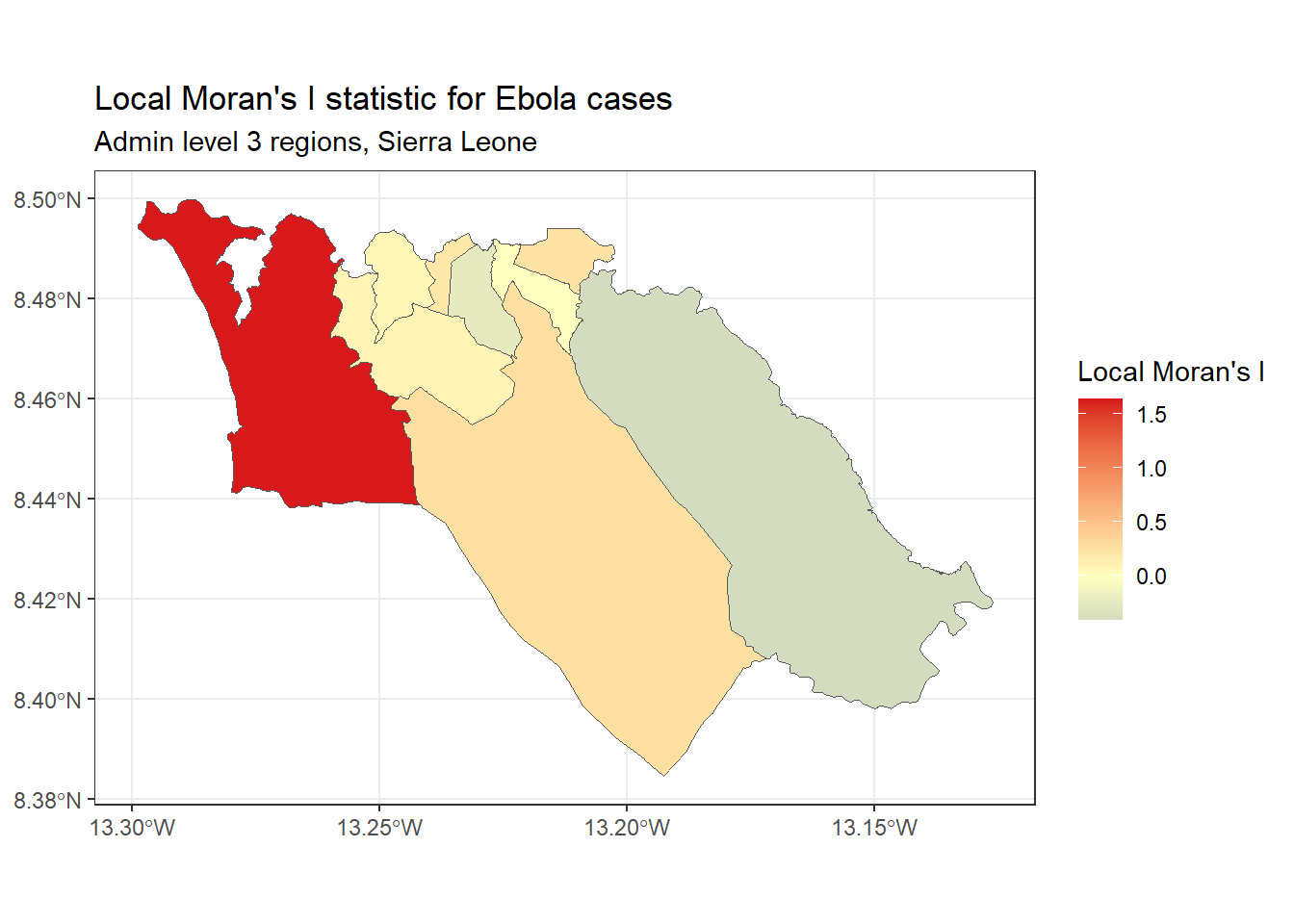
Getis-Ord Gi* - Еще одна статистика, которая часть используется для анализа очагов; во многом популярность этой статистики связана с ее использованием в инструменте анализа очагов (Hot Spot Analysis tool) в ArcGIS. Она основана на допущении о том, что, как правило, разница в значении переменной между соседними регионами должна следовать нормальному распределению. Она использует подход балла z-score для определения регионов, в которых значения указанной переменной значительно выше (горячие точки) или значительно ниже (холодные точки) по сравнению с соседями.
Мы можем рассчитать и построить карту статистики Gi* с помощью функции localG() из spdep:
# Проводим локальный G анализ
getis_ord <- spdep::localG(
sle_adm3_dat$cases,
sle_listw
)
# соединяем результаты с данными sf
sle_adm3_dat$getis_ord <- as.numeric(getis_ord)
# строим карту
ggplot(data=sle_adm3_dat) +
geom_sf(aes(fill=getis_ord)) +
theme_bw() +
scale_fill_gradient2(low="#2c7bb6", mid="#ffffbf", high="#d7191c",
name="Gi*") +
labs(title="Getis-Ord Gi* statistic for Ebola cases",
subtitle="Admin level 3 regions, Sierra Leone")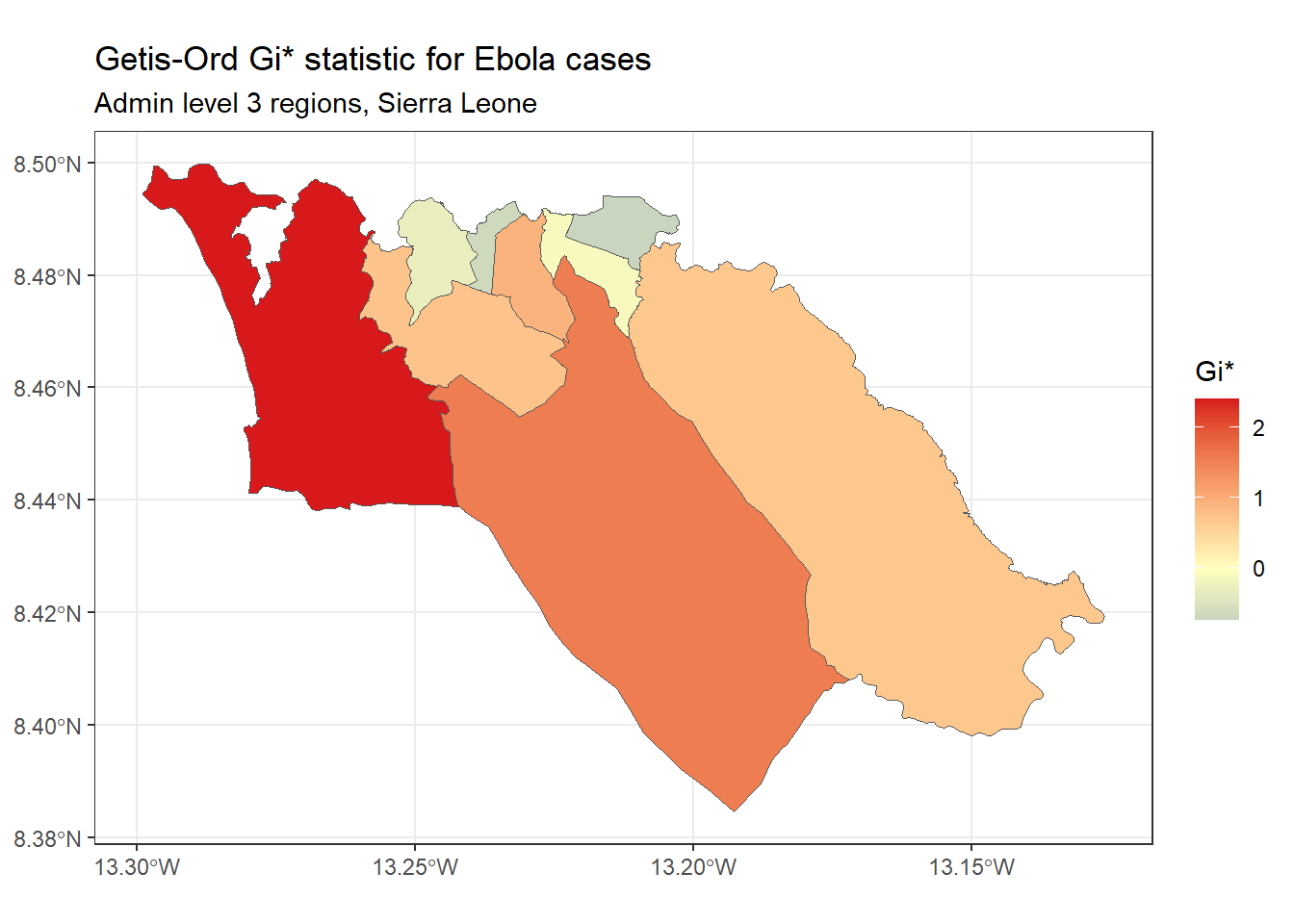
Как видите, карта Getis-Ord Gi* выглядит несколько иначе, чем карта локального I Морана, которую я построил ранее. Это связано с тем, что методы расчета этих двух статистик несколько отличаются друг от друга; какой из них использовать, зависит от конкретного случая использования и интересующего вас вопроса исследования.
L-тест Ли - Это статистический тест на бивариационную пространственную корреляцию. Он позволяет проверить, насколько пространственный паттерн для данной переменной x похож на пространственный паттерн другой переменной, y, которая, согласно гипотезе, пространственно связана с x.
В качестве примера проверим, коррелирует ли пространственная структура случаев заболевания лихорадкой Эбола, полученная в результате имитации эпидемии, с пространственной структурой численности населения. Для начала нам нужна переменная population (население) в данных sle_adm3. Мы можем использовать переменную total (итого) из датафрейма sle_adm3_pop, который мы загрузили ранее.
sle_adm3_dat <- sle_adm3_dat %>%
rename(population = total) # переименуйте 'total' в 'population'Мы можем быстро визуализировать пространственные закономерности двух переменных друг рядом с другом, чтобы посмотреть, похожи ли они:
tmap_mode("plot")
cases_map <- tm_shape(sle_adm3_dat) + tm_polygons("cases") + tm_layout(main.title="Cases")
pop_map <- tm_shape(sle_adm3_dat) + tm_polygons("population") + tm_layout(main.title="Population")
tmap_arrange(cases_map, pop_map, ncol=2) # упорядочиваем по фасетам 2x1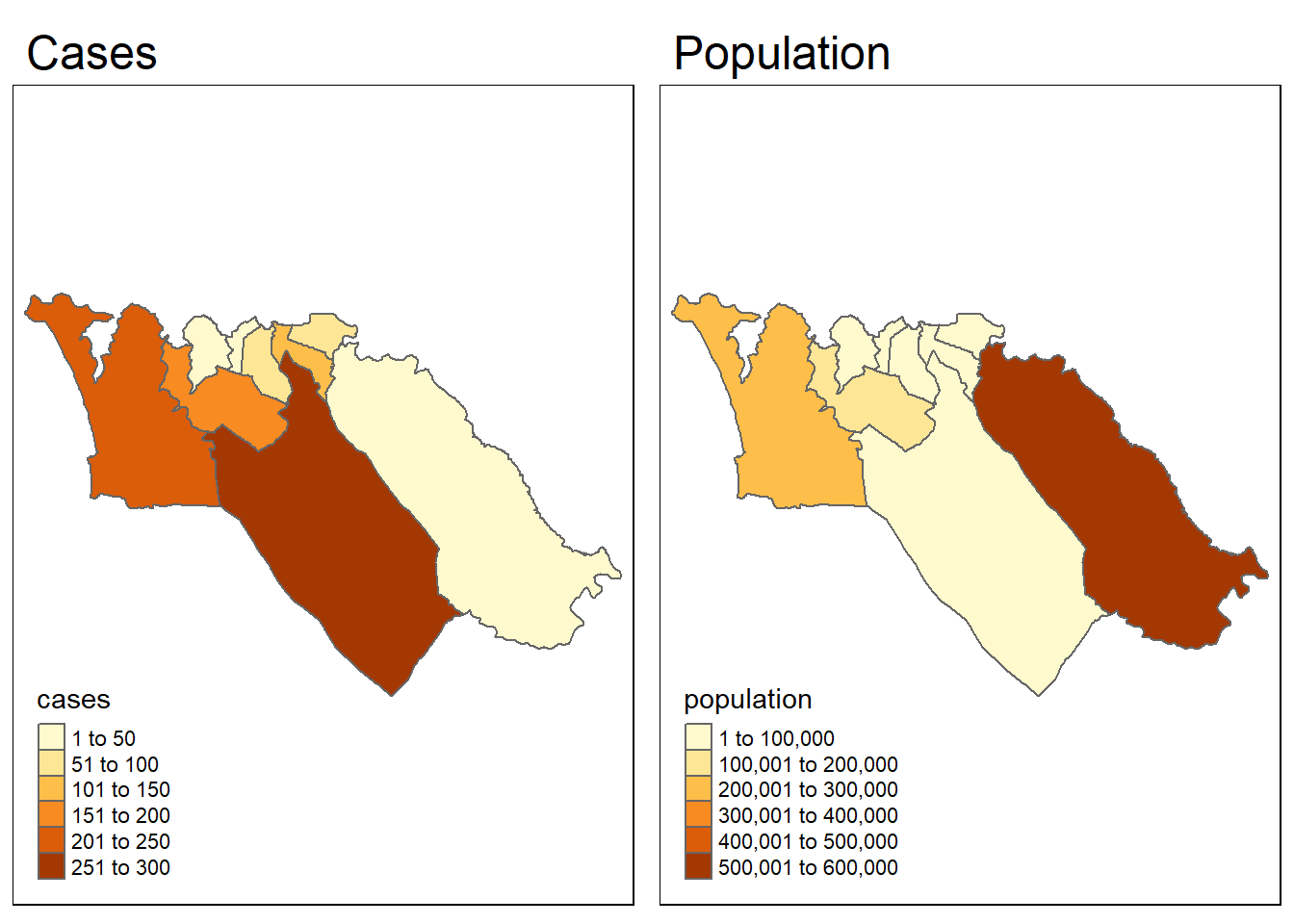
Визуально закономерности кажутся непохожими. Мы можем использовать функцию lee.test() из spdep, чтобы статистически протестировать, связаны ли закономерности пространственной автокорреляции в двух переменных. Статистика L будет близка к 0, если нет корреляции между закономерностями, и близка к 1, если есть сильная положительная корреляция (т.е. закономерности схожи), и близка к -1, если есть сильная отрицательная корреляция (т.е. закономерности противоположны).
lee_test <- spdep::lee.test(
x=sle_adm3_dat$cases, # переменная 1 для сравнения
y=sle_adm3_dat$population, # переменная 2 для сравнения
listw=sle_listw # объект listw с весами соседей
)
lee_test
Lee's L statistic randomisation
data: sle_adm3_dat$cases , sle_adm3_dat$population
weights: sle_listw
Lee's L statistic standard deviate = -0.93709, p-value = 0.8256
alternative hypothesis: greater
sample estimates:
Lee's L statistic Expectation Variance
-0.13740602 -0.03333785 0.01233303 Выходной результат выше показывает, что статистика L Ли по нашим двум переменным была round(lee_test$estimate[1],2), что указывает на слабую отрицательную корреляцию. Это подтверждает нашу визуальную оценку того, что закономерности по случаям и населению не связаны друг с другом, и предоставляет доказательства того, что пространственная закономерность случаев строго не является результатом плотности населения в районах высокого риска.
L-статистика Ли может быть полезной для подобного рода выводов об отношениях между пространственно распределенными переменными; однако для описания природы связи между двумя переменными более детальным образом, либо для корректирования фактора смешивания, потребуются приемы пространственной регрессии. Мы их кратко описываем в следующем разделе.
Пространственная регрессия
Возможно, вы захотите сделать статистические выводы о взаимосвязях между переменными в ваших пространственных данных. В таких случаях полезно рассмотреть приемы пространственной регрессии - то есть подходы к регрессии, явно учитывающие пространственную организацию единиц в ваших данных. Некоторые причины, по которым вам может потребоваться рассмотреть пространственные регрессионные модели вместо стандартных регрессионных моделей, таких как обобщенные линейные модели, включают следующие:
Стандартные модели регрессии предполагают, что остатки независимы друг от друга. При наличии сильной пространственной автокорреляции, остатки стандартной регрессионной модели, скорее всего, также будут пространственно автокоррелированы, что нарушает данное предположение. Это может привести к проблемам с интерпретацией результатов моделирования, и в этом случае предпочтительнее использовать пространственную модель.
В регрессионных моделях также обычно предполагается, что эффект переменной x постоянен для всех наблюдений. В случае пространственной неоднородности, эффекты, которые мы хотим оценить, могут различаться в пространстве, и мы можем быть заинтересованы в количественной оценке этих различий. В этом случае модели пространственной регрессии обеспечивают большую гибкость при оценке и интерпретации эффектов.
Подробное рассмотрение подходов к пространственной регрессии выходит за рамки данного руководства. Вместо этого в данном разделе будет представлен обзор наиболее распространенных моделей пространственной регрессии и их применения, а также даны ссылки на источники, которые могут оказаться полезными при дальнейшем изучении этой области.
Модели пространственной ошибки - В этих моделях предполагается, что условия ошибки между пространственными единицами коррелированы, и в этом случае данные будут нарушать предположения стандартной модели наименьших квадратов. Модели пространственных ошибок также иногда называют одновременными авторегрессионными моделями (SAR). Их можно построить с помощью функции errorsarlm() из пакета spatialreg (функции пространственной регрессии, которые раньше входили в spdep).
Модели пространственного лага - Эти модели предполагают, что на зависимую переменную для региона i влияет не только значение независимой переменной в i, но и значения этих переменных в регионах по соседству с i. Как и в моделях пространственной ошибки, модели пространственного лага иногда описывают как одновременные авторегрессионные модели (SAR). Их можно построить с помощью функции lagsarlm() из пакета spatialreg.
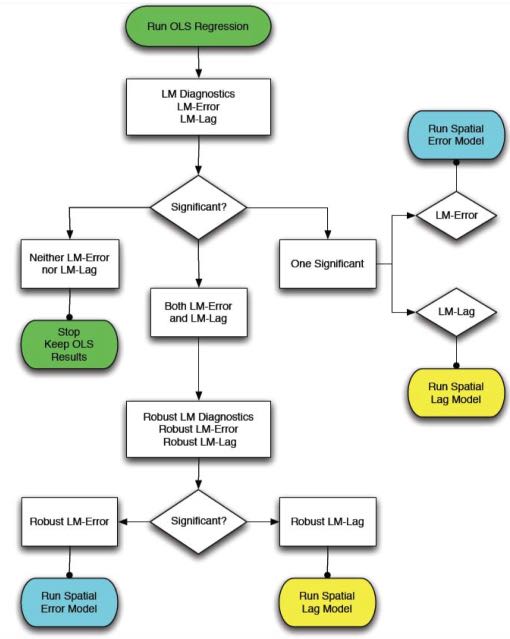
Пакет spdep содержит несколько полезных диагностических тестов для выбора метода наименьших квадратов, модели пространственного лага или модели пространственной ошибки. Эти тесты, называемые Диагностика методом множителей Лагранжа, могут быть использованы для определения типа пространственной зависимости в ваших данных и выбора наиболее подходящей модели. Функция lm.LMtests() может быть использована для рассчета всех тестов по методу множителей Лагранжа. Анселин (1988) также создал полезную блок-схему для принятия решения о том, какую модель пространственной регрессии использовать, исходя из результатов теста по методу множителей Лагранжа:
Байесовские иерархические модели - Байсовские подходы часто применяются для некоторых приложений пространственного анализа, чаще всего для картирования заболеваний. Они также являются предпочтительными в случаях, когда у данных по случаям низкая концентрация (например, при редком исходе), либо много статистического “шума”, так как они могут использоваться для создания “сглаженных” оценок риска заболеваний, принимая во внимание базовый латентный пространственный процесс. Это может улучшить качество оценок. Они также позволяют исследователю предварительно уточнить (через выбор априорной величины) сложные закономерности пространственной автокорреляции, которые могут существовать в данных, которые могут учитывать и пространственно-зависимые, и пространственно-независимые колебания как в независимой, так и зависимой переменной. В R Байесовские иерархические модели можно построить, используя пакет CARbayes (см. виньетка) или R-INLA (см. веб-сайт и учебник). R можно также использовать для запроса во внешнюю программу для Байесовской оценки, такую как JAGS или WinBUGS.
28.12 Ресурсы
Простые свойства (Simple Features) R и пакет sf виньетка
Пакет R tmap виньетка
Пространственные данные в R (курс EarthLab)
Прикладной анализ пространственных данных в R учебник
SpatialEpiApp - приложение Shiny, которое можно скачать как пакет R, которое позволяет вам задавать собственные данные и делать картирование, анализ кластеров и пространственную статистику.
Введение в пространственную эконометрику в R семинар