
7 Импорт и экспорт
На данной странице мы описываем способы поиска, импорта и экспорта файлов:
- Использование пакета rio для гибкого импорта
import()и экспортаexport()многих типов файлов
- Использование пакета here для поиска расположения файлов относительно корневой папки проекта R - чтобы предотвратить проблемы из-за использования путей к файлам, специфичных для одного компьютера
- Специфичные сценарии импорт, такие как:
- Конкретные листы Excel
- Хаотичные заголовки и пропуск строк
- Из таблиц Google
- Из данных, размещенных на веб-сайтах
- С API
- Импорт наиболее свежего файла
- Конкретные листы Excel
- Ручной ввод данных
- Специфичные для R типы файлов, такие как RDS и RData
- Экспорт/сохранение файлов и графиков
7.1 Обзор
При импорте “набора данных” в R, вы, как правило, создаете новый датафрейм объект в рабочей среде R и определяете его как импортированный файл (например, Excel, CSV, TSV, RDS), который расположен в директориях папок по определенному пути к файлу/адресу.
Вы можете импортировать/экспортировать многие типы файлов, включая и те, которые созданы другими статистическими программами (SAS, STATA, SPSS). Вы можете также связать их с реляционными базами данных.
R даже имеет свои собственные форматы данных:
- Файл RDS (.rds) хранит единственный объект R, например, датафрейм. Такие файлы полезны для хранения вычищенных данных, поскольку в них сохраняются классы столбцов R. Боолее подробно читайте в этом разделе.
- Файл RData (.Rdata) может использоваться для хранения нескольких объектов, либо даже полного рабочего пространства R. Более подробно читайте в этом разделе.
7.2 Пакет rio
Мы рекомендуем пакет R: rio. Название “rio” - это сокращение от “R I/O” (ввод/вывод).
Его функции import() и export() могут справляться с разными типами файлов (например, .xlsx, .csv, .rds, .tsv). Когда вы указываете путь к файлу для любой из этих двух функций (включая такие расширения файлов, как “.csv”), rio прочитает расширение и будет использовать правильный инструмент для импорта или экспорта файла.
Альтернативой использованию rio является использование функций из многих других проектов, каждая из которых специфична для какого-то типа файла. Например, read.csv() (базовый R), read.xlsx() (пакет openxlsx), write_csv() (пакет readr) и др. Эти альтернативы может быть сложно запомнить, а использование import() и export() из rio легко.
Функции rio import() и export() используют подходящий пакет и функцию для определенного файла, основываясь на расширении файла. См. полную таблицу того, какие пакеты/функции rio использует фоново, в конце данной страницы. Этот пакет можно также использовать для импорта файлов STATA, SAS и SPSS, а также десятки других типов файлов.
Импорт/экспорт шейп-файлов требует других пакетов, что описано на странице Основы ГИС.
7.3 Пакет here
Пакет here и его функция here() позволяет с легкостью указать R, где найти и сохранить ваши файлы - по сути, он строит пути к файлам.
При сочетании с проектом R, here позволяет вам описать расположение файлов в вашем проекте R по отношению к корневой директории (папке верхнего уровня) проекта R. Это полезно, когда над проектом R ведется совместная работа, либо к нему нужен доступ нескольким людям/с разных компьютеров. Это позволяет предотвратить осложнения, вызванные уникальными путями к файлам на разных компьютерах (например, "C:/Users/Laura/Documents..." благодаря тому, что путь к файлу “начинается” с общего для всех пользователей расположения (с корневой папки проекта R).
Вот как работает here() в рамках проекта R:
- Когда пакет here загружается первый раз в проекте R, он размещает небольшой файл, под названием “.here” в корневой папке вашего проекта R в качестве “бенчмарки” или “якоря”
- Чтобы сделать ссылку на файл в подпапке проекта R в ваших скриптах, вы будете использовать функцию
here(), чтобы построить путь к файлу относительно этого якоря - Чтобы построить путь к файлу, напишите названия папок после корневой папки в кавычках, разделенными запятыми, а в конце указывается название и расширение файла, как показано ниже
- Пути к файлу с помощью
here()могут быть использованы как для импорта, так и для экспорта
Например, ниже функции import() задается путь к файлу, который составлен с помощью here().
linelist <- import(here("data", "linelists", "ebola_linelist.xlsx"))Команда here("data", "linelists", "ebola_linelist.xlsx") на самом деле предоставляет полный путь к файлу, который уникален для компьютера пользователя:
"C:/Users/Laura/Documents/my_R_project/data/linelists/ebola_linelist.xlsx"Прелесть состоит в том, что команду с использованием here() можно успешно запустить на любом компьютере, который получает доступ к проекту R.
СОВЕТ: Если вы не уверены, где расположена корневая папка “.here”, выполните функцию here() с пустыми скобками.
Более подробно о пакете here вы можете почитать по этой ссылке.
7.4 Пути к файлам
При импорте или экспорте данных, вы должны указать путь к файлу. Вы можете это сделать одним из трех способов:
-
Рекомендованный: указать “относительный” путь к файлу с помощью пакета here
- Указать “полный” / “абсолютный” путь к файлу
- Выбор файла вручную
“Относительные пути к файлу”
В R “относительные” пути к файлу состоят из пути к файлу относительно корневой папки проекта R. Они позволяют обеспечить простые пути к файлу, которые могут работать на разных компьютерах (например, если проект R находится на сетевом диске или отправляется по электронной почте). Как указано выше, относительные пути к файлу строятся с помощью пакета here.
Ниже приведен пример относительного пути к файлу, построенного с помощью here(). Мы предполагаем, что работа идет в проекте R, который содержит подпапку “data”, а внутри нее подпапку “linelists”, в которой есть интересующий нас .xlsx файл.
linelist <- import(here("data", "linelists", "ebola_linelist.xlsx"))“Абсолютные” пути к файлу
Абсолютные или “полные” пути к файлам могут быть заданы для таких функций, какimport(), но они являются “хрупкими”, так как они уникальны для конкретного компьютера пользователя и, следовательно, мы их не рекомендуем.
Ниже представлен пример абсолютного пути к файлу, где на компьютере Лауры есть папка “analysis”, подпапка “data”, а внутри нее подпапка “linelists”, в которой находится интересующий нас .xlsx файл.
linelist <- import("C:/Users/Laura/Documents/analysis/data/linelists/ebola_linelist.xlsx")Несколько важных моментов по поводу абсолютных путей к файлам:
- Избегайте использования абсолютных путей к файлам, поскольку они сломаются, если запустить скрипт на другом компьютере
- Используйте прямые слэши (
/), как в примере выше (примечание: это НЕ является опцией по умолчанию для путей к файлам в Windows)
- Пути к файлам, начинающиеся с двойного слэша (например, “//…”), скорее всего, не будут распознаны R и выдадут ошибку. Попробуйте переместить вашу работу на “именованный” диск или диск, который начинается с буквы (например, “J:” или “C:”). См. страницу Взаимодействие директорий для получения более детальной информации по этому вопросу.
Один сценарий, при котором абсолютные пути к файлу могут быть для вас подходящим вариантом, включает ту ситуацию, когда вы хотите импортировать файл с общего диска, который имеет одинаковый путь к файлу для всех пользователей.
СОВЕТ: чтобы быстро конвертировать все \ в /, выделите интересующий код, используйте Ctrl+f (для Windows), отметьте ячейку опции “In selection” (в выбранном), а затем используйте функционал replace (замены) для их конвертации.
Выбор файла вручную
Вы можете импортировать данные вручную с помощью одного из этих методов:
- Панель RStudio Environment (рабочая среда), кликните “Import Dataset” (импортировать набор данных), затем выберите тип данных
- Кликните File (Файл) / Import Dataset (импорт набора данных) / (выберите тип данных)
- Чтобы жестко закодировать ручной выбор, используйте команду из базового R
file.choose()(оставьте скобки пустыми), чтобы вызвать появление всплывающего окна, которое позволяет пользователю вручную выбрать файл со своего компьютера. Например:
# Выбор файла вручную. когда выполняется эта команда, возникнет ВСПЛЫВАЮЩЕЕ окно.
# Выбранный путь к файлу будет передан в команду import().
my_data <- import(file.choose())СОВЕТ: Всплывающее окно может появиться ЗА вашим окном RStudio.
7.5 Импорт данных
Использовать import() для импорта набора данных очень просто. Просто укажите путь к файлу (включая название файла и расширение файла) в кавычках. При использовании here() для построения пути к фаайлу, следуйте указанным выше инструкциям. Ниже приведены несколько примеров:
Импорт csv файла, который расположен в “рабочей директории” или в корневой папке проекта R:
linelist <- import("linelist_cleaned.csv")Импортирование первого листа рабочей книги Excel, который расположен в подпапках “data” и “linelists” проекта R (путь к файлу построен с помощью here()):
linelist <- import(here("data", "linelists", "linelist_cleaned.xlsx"))Импортирование датафрейма (файла .rds) с помощью абсолютного пути к файлу:
linelist <- import("C:/Users/Laura/Documents/tuberculosis/data/linelists/linelist_cleaned.rds")Конкретные листы Excel
По умолчанию, если вы указываете рабочую книгу Excel (.xlsx) функции import(), будет импортирован первый лист рабочей книги. Если вы хотите импортировать конкретный лист, включите название листа в аргумент which =. Например:
my_data <- import("my_excel_file.xlsx", which = "Sheetname")При использовании метода here() для того, чтобы указать относительный путь к файлу для import(), вы можете также указать конкретный лист, добавив аргумент which = после закрытия скобок функции here().
# Демонстрация: импорт конкретного листа Excel при использовании относительного пути к файлу с помощью пакета 'here'
linelist_raw <- import(here("data", "linelist.xlsx"), which = "Sheet1")` Чтобы экспортировать датафрейм из R на конкретный лист Excel, и чтобы остальная рабочая книга Excel при этом осталась неизменной, вам нужно будет проводить импорт, редактирование и экспорт с помощью альтернативного пакета, предназначенного для этой цели, такого как openxlsx. Более подробную информацию можно получить на странице Взаимодействие директорий или на этой странице github.
Если ваша рабочая книга Excel имеет расширение .xlsb (рабочая книга Excel в двоичном формате), вы, возможно, не сможете ее импортировать с помощью rio. Рассмотрите возможность пересохранения в формате .xlsx, или используйте такой пакет, как readxlsb, который предназначен для этой цели.
Отсутствующие значения
Вы можете установить значение(я), которое в вашем наборе данных будет считаться отсутствующим. Как объясняется на странице Отсутствующие данные, значение в R для отсутствующих данных обозначается как NA, но тот набор данных, которые вы импортируете, вместо этого использует 99, “Missing”, или просто пустое текстовое поле ““.
Используйте аргумент na = для import() и укажите значение(я) в кавычках (даже если они числовые).Вы можете указать несколько значений, включив их внутрь вектора, используя c(), как указано ниже.
Здесь значение “99” в импортируемом наборе данных считается отсутствующим и конвертируется в NA в R.
linelist <- import(here("data", "my_linelist.xlsx"), na = "99")Здесь любое из значений “Missing”, “” (пустая ячейка), или ” ” (один пробел) в импортируемом наборе данных конвертируются в NA в R.
linelist <- import(here("data", "my_linelist.csv"), na = c("Missing", "", " "))Пропуск строк
Иногда вы можете захотеть пропустить строку данных при импорте. Вы это можете сделать с помощью аргумента skip =, если используете import() из rio с файлом .xlsx или .csv. Задайте число строк, которое вы хотите пропустить.
linelist_raw <- import("linelist_raw.xlsx", skip = 1) # не импортирует строку заголовкаК сожалению skip = принимает только одно числовое значение, а не диапазон (например, “2:10” не работает). Чтобы пропустить импорт конкретных непоследовательно расположенных строк сверху, рассмотрите импорт несколько раз и использование bind_rows() из dplyr. См. пример ниже по пропуску только строки 2.
Управление второй строкой заголовка
Иногда у ваших данных может быть вторая строка, например, если это строка “data dictionary”, как указано ниже. Эта ситуация может быть проблематичной, поскольку это может привести к тому, что все столбцы будут импортированы как “текстовый” класс.
Ниже представлен пример такого набора данных (где первая строка data dictionary).
Удаление второй строки заголовка
Чтобы выбросить вторую строку заголовка, вам, скорее всего, потребуется дважды импортировать данные.
- Импортируйте данные, чтобы сохранить правильные названия столбцов
- Вновь импортируйте данные, пропустив первые две строки (строку заголовка и вторую строку)
- Объедините правильные названия в сокращенный датафрейм
Точный аргумент для объединения правильных названий столбцов зависят от типа файла с данными (.csv, .tsv, .xlsx, etc.). Это происходит потому, что rio использует разные функции для разных типов файлов (см. таблицу выше).
Для файлов Excel: (col_names =)
# импорт в первый раз; сохранение названий столбцов
linelist_raw_names <- import("linelist_raw.xlsx") %>% names() # save true column names
# импорт во второй раз; пропускает строку 2, и присваивает названия столбца аргументу col_names =
linelist_raw <- import("linelist_raw.xlsx",
skip = 2,
col_names = linelist_raw_names
) Для файлов CSV: (col.names =)
# импорт в первый раз; сохранение названий столбцов
linelist_raw_names <- import("linelist_raw.csv") %>% names() # сохранение истинных названий столбцов
# отметить аргумент для файлов 'col.names = '
linelist_raw <- import("linelist_raw.csv",
skip = 2,
col.names = linelist_raw_names
) Запасной вариант - изменение названий столбцов как отдельная команда
# присваивание/перезапись заголовков, используя базовую функцию 'colnames()'
colnames(linelist_raw) <- linelist_raw_namesСоздание словаря данных
Бонус! Если у вас есть вторая строка, которая является словарем данных, вы можете легко создать правильный словарь данных. Этот совет взят из следующего поста.
dict <- linelist_2headers %>% # начало: построчный список со словарем в качестве первой строки
head(1) %>% # сохраните только названия столбцов и первую строку словаря
pivot_longer(cols = everything(), # поверните все столбцы в вертикальный формат
names_to = "Column", # присвойте новые названия столбцов
values_to = "Description")Объединение двух строк заголовков
В некоторых случаях, когда в вашем наборе данных две строки заголовка (или, если говорить более конкретно, 2ая строка данных является подзаголовком), вы можете их “объединить” или добавить значения второй строки заголовка в первую строку заголовка.
Команда ниже определит названия столбцов датафрейма, как комбинацию (слияние) первого (истинного) заголовка со значением, которое идет непосредственно под ним (в первой строке).
names(my_data) <- paste(names(my_data), my_data[1, ], sep = "_")Лист Google
Вы можете импортировать из электронных таблиц Google с помощью пакета googlesheet4 и через аутентификацию вашего доступа к электронной таблице.
pacman::p_load("googlesheets4")Ниже импортируется и сохраняется демо таблица Google. Эта команда может потребовать аутентификации в вашем Google аккаунте. Следуйте подсказкам и требованиям во всплывающих окнах вашего интернет-браузера, чтобы дать пакетам Tidyverse API разрешения на редактирование, создание и удаление электронных таблиц на Google диске.
См. лист ниже, который “доступен к просмотру любому со ссылкой”, вы можете попробовать его импортировать.
Gsheets_demo <- read_sheet("https://docs.google.com/spreadsheets/d/1scgtzkVLLHAe5a6_eFQEwkZcc14yFUx1KgOMZ4AKUfY/edit#gid=0")Лист можно также импортировать, используя только ID листа, более короткую часть URL:
Gsheets_demo <- read_sheet("1scgtzkVLLHAe5a6_eFQEwkZcc14yFUx1KgOMZ4AKUfY")Другой пакет, googledrive, предлагает полезные функции для написания, редактирования и удаления Google таблиц. Например, используя функции gs4_create() и sheet_write() из этого пакета.
Вот некоторые полезные онлайн самоучители:
самоучитель по основам импорта из Google таблиц
более детальный самоучитель
взаимодействие между googlesheets4 и tidyverse
7.6 Несколько файлов - импорт, экспорт, разделение, объединение
См. страницу Итерации, циклы и списки, где приведены примеры того, как импортировать и объединять несколько файлов или несколько рабочих книг Excel. На этой странице также приведены примеры того, как разделить датафрейм на части, и экспортировать каждую из частей отдельно, либо в качестве именованных объектов в рабочей книге Excel.
7.7 Импорт из Github
Импорт данных напрямую из Github в R может быть простым, а может потребовать нескольких шагов - в зависимости от типа файла. Ниже приведен ряд подходов:
CSV файлы
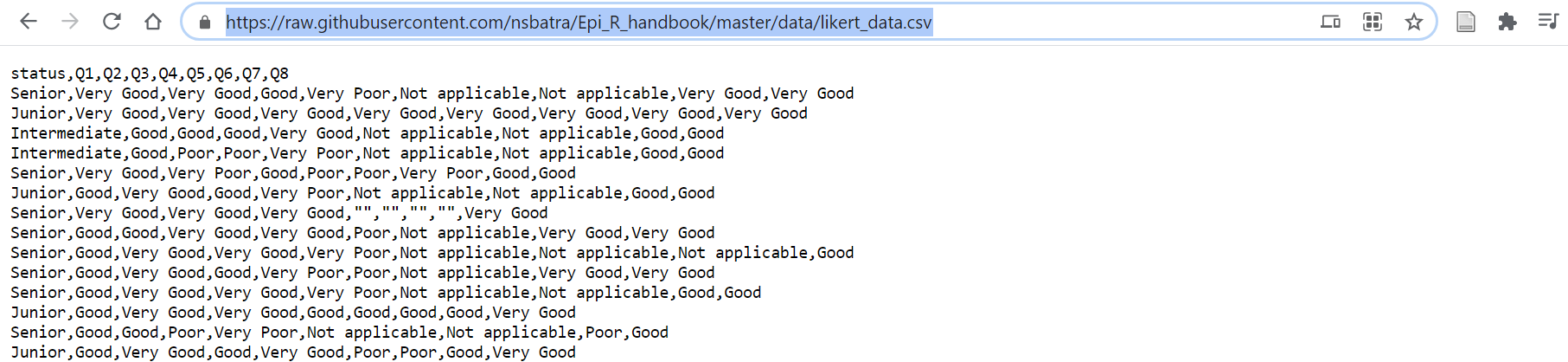
Импортироавть .csv файл напрямую из Github в R с помощью команды R может быть очень просто.
- Зайдите в репозиторий Github, найдите интересующий вас файл, кликните на него
- Кликните на кнопку “Raw” (сырые данные) (вы затем увидите “сырые” csv данные, как показано ниже)
- Скопируйте URL (веб-адрес)
- Разместите URL в кавычках в команде
import()в R
XLSX файлы
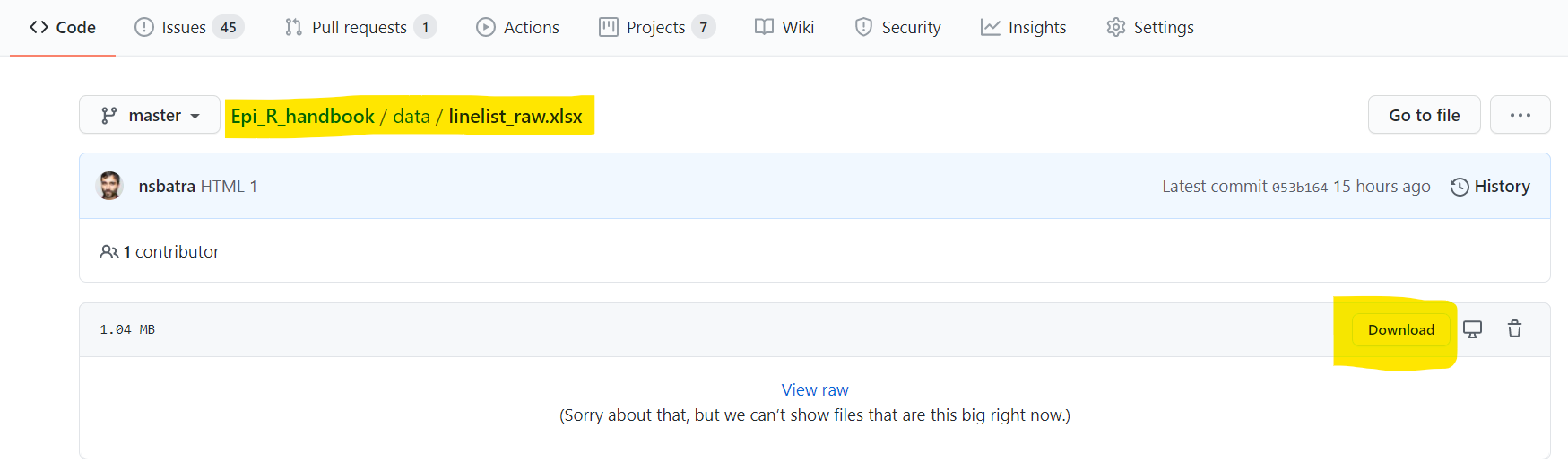
Возможно, у вас не получится просмотреть “сырые” данные для некоторых файлов (например, .xlsx, .rds, .nwk, .shp)
- Зайдите в репозиторий Github, найдите интересующий вас файл, кликните на него
- Кликните на кнопку “Download” (скачать), как показано ниже
- Сохраните файл на своем компьютере и импортируйте его в R
Шейп-файлы
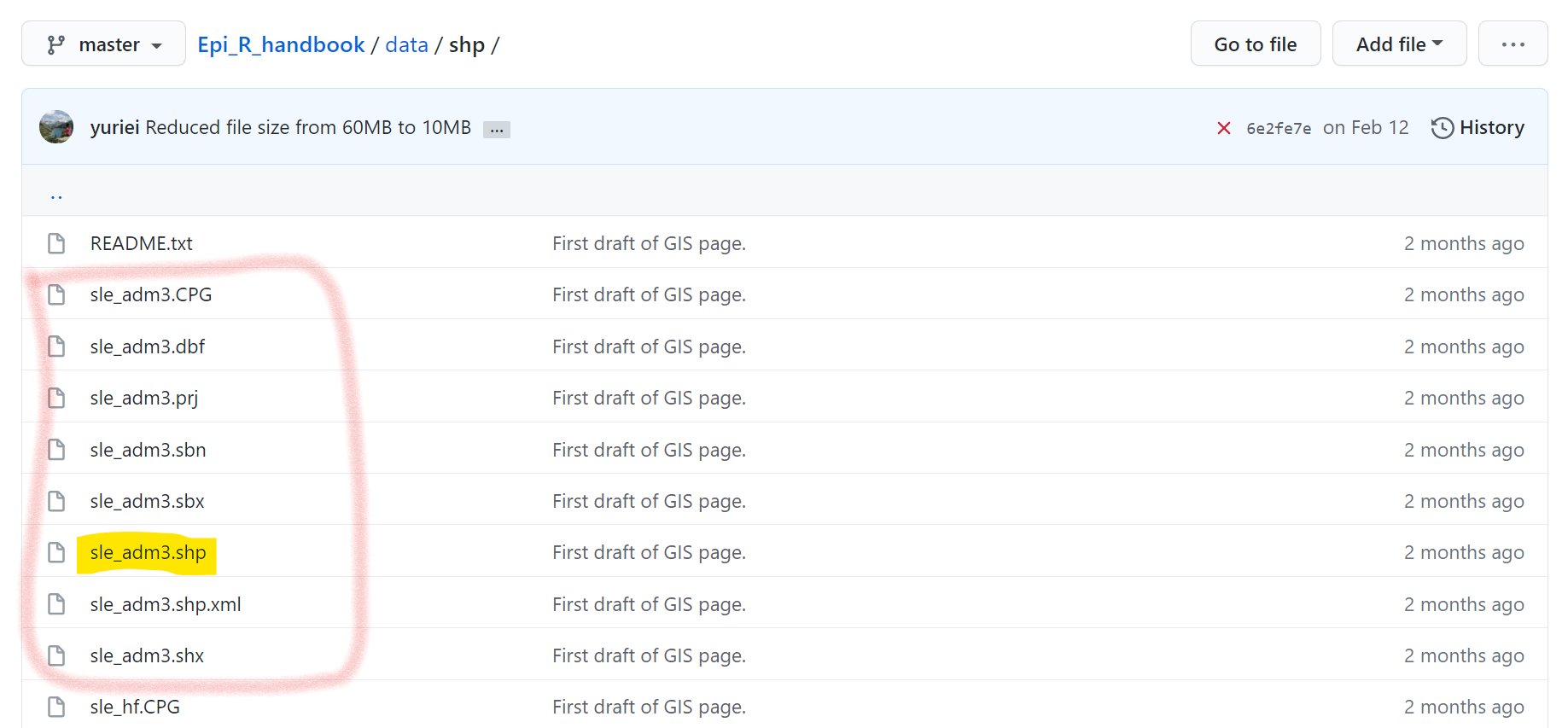
Шейп-файлы могут иметь много файлов суб-компонентов, каждый с разным расширением файла. У одного файла будет расширение “.shp”, а у других оно может быть “.dbf”, “.prj”, и т.д. Чтобы скачать шейп-файл с Github, вам нужно загрузить каждый файл суб-компонент отдельно и сохранить их все в одну и ту же папку на вашем компьютере. В Github кликните отдельно на каждый файл и скачайте каждый, нажав кнопку “Download” (скачать).
После сохранения на компьютер, вы можете испортировать шейп-файл, как описано на странице Основы ГИС, используя st_read() из пакета sf. Вам нужно только задать путь к файлу и имя файла “.shp” - при условии, что другие связанные файлы находятся в той же папке на вашем компьютере.
Ниже вы можете увидеть. что шейп-файл “sle_adm3” состоит из множества файлов - каждый из которых нужно скачать с Github.
7.8 Ручной ввод данных
Ввод по строкам
Используйте функцию tribble из пакета tibble из tidyverse (онлайн справка по tibble).
Обратите внимание, что заголовки столбцов начинаются с тильды (~). Также обратите внимание, что в каждом столбце должен содержаться только один класс данных (текстовых, числовых и т.п.). Вы можете использовать табуляцию, пробелы и новые строки, чтобы сделать ввод данных более интуитивно понятным и читаемым. Пробелы не важны между значениями, но каждую строку таблицы нужно представлять новой строкой кода. Например:
# создание нового набора данных вручную по строкам
manual_entry_rows <- tibble::tribble(
~colA, ~colB,
"a", 1,
"b", 2,
"c", 3
)Теперь мы отобразим новый набор данных:
Ввод по столбцам
Поскольку датафрейм состоит из векторов (вертикальных столбцов), базовый подход к ручному созданию датафрейма в R ожидает, что вы определите каждый столбец и объедините их. Это может показаться интуитивно противоречивым в эпидемиологии, поскольку мы мыслим строками (как показано выше).
# определите каждый вектор (вертикальный столбец) отдельно, дав каждому собственное имя
PatientID <- c(235, 452, 778, 111)
Treatment <- c("Да", "No", "Да", "Да")
Death <- c(1, 0, 1, 0)ВНИМАНИЕ: Все векторы должны быть одной длины (то же самое количество значений).
Затем векторы можно связать вместе, используя функцию data.frame():
# объедините столбцы в датафрейм, дав ссылку на имена векторов
manual_entry_cols <- data.frame(PatientID, Treatment, Death)Теперь отобразим новый набор данных:
Вставка из буфера обмена
Если вы копируете данные откуда-то, и они есть у вас в буфере обмена, вы можете попробовать один из указанных ниже способов:
В пакете clipr вы можете использовать read_clip_tbl() для импорта в виде датафрейма, либо просто read_clip() для импорта в виде текстового вектора. В обоих случаях оставьте скобки пустыми.
linelist <- clipr::read_clip_tbl() # импортирует текущую информацию из буфера обмена в виде датафрейма
linelist <- clipr::read_clip() # импортирует в виде текстового вектораВы можете также легко произвести импорт из буфера обмена вашей системы с помощью clipr. См. раздел ниже по Экспорту.
Альтернативно вы можете использовать функцию read.table() из базового R с file = "clipboard") для импорта в виде датафрейма:
df_from_clipboard <- read.table(
file = "clipboard", # уточните, что это "clipboard" (буфер обмена)
sep = "t", # разделителем может быть табуляция, запятые и т.п.
header=TRUE) # если есть строка заголовка7.9 Импорт самого последнего файла
Часто вы можете получать обновления для своих наборов данных. В таком случае вам нужно написать код, который будет импортировать самый последний файл. Ниже представлены два подхода к тому, как это сделать:
- Выбор файла по дате в названии файла
- Выбор файла на основе мета-данных файла (последнее изменение)
Даты в именах файлов
Этот подход основан на трех предположениях:
- Вы доверяете датам в именах файлов
- Даты являются числовыми и представлены, как правило, в одном формате (например, год, потом месяц, потом день)
- В имени файла нет иных цифр
Мы объясним каждый шаг, затем покажем их вам в объединенном виде в конце.
Сначала используем dir() из базового R для извлечения только имен файлов для каждого файла в интересующей нас папке. См. страницу Взаимодействие директорий для получения более детальной информации о dir(). В данном примере нас интересует папка “linelists” внутри папки “example” внутри папки “data” в проекте R.
linelist_filenames <- dir(here("data", "example", "linelists")) # получаем имена файлов из папки
linelist_filenames # печать[1] "20201007linelist.csv" "case_linelist_2020-10-02.csv"
[3] "case_linelist_2020-10-03.csv" "case_linelist_2020-10-04.csv"
[5] "case_linelist_2020-10-05.csv" "case_linelist_2020-10-08.xlsx"
[7] "case_linelist20201006.csv" Как только у вас будет вектор имен, вы можете извлечь из него даты, применив str_extract() из stringr, используя обычное выражение. Эта функция извлечет любые числа в имени файла (включая другие знаки посередине, такие как дефисы или слэши). Более детально о stringr вы можете прочитать на странице Последовательности и текст.
linelist_dates_raw <- stringr::str_extract(linelist_filenames, "[0-9].*[0-9]") # извлекает числа и любые знаки между ними
linelist_dates_raw # печать[1] "20201007" "2020-10-02" "2020-10-03" "2020-10-04" "2020-10-05"
[6] "2020-10-08" "20201006" Предполагая, что даты, как правило, пишутся в одинаковом формате (например, год,потом месяц, потом день) и годы представлены 4 цифрами, вы можете использовать функции гибкой конвертации из lubridate (ymd(), dmy(), или mdy()), чтобы конвертировать их в даты. Для этих функций не имеют значения дефисы, пробелы или слэши, важен только порядок цифр. Более детально об этом можно почитать на странице Работа с датами.
linelist_dates_clean <- lubridate::ymd(linelist_dates_raw)
linelist_dates_clean[1] "2020-10-07" "2020-10-02" "2020-10-03" "2020-10-04" "2020-10-05"
[6] "2020-10-08" "2020-10-06"Затем можно использовать функцию базового R which.max(), которая выдаст индексную позицию (например, 1ую, 2ую, 3ю, …) максимального значения даты. Последним будет правильно выбран 6-й файл - “case_linelist_2020-10-08.xlsx”.
index_latest_file <- which.max(linelist_dates_clean)
index_latest_file[1] 6Если сжать все эти команды, полноценный код будет выглядеть так, как код ниже. Обратите внимание, что . в последней строке является заполнителем для объекта, который будет привязан в канал в этом месте канала. В этот момент значением является только цифра 6. Ее размещаем в двойные квадратные скобки, чтобы извлечь 6-й элемент вектора имены файла, полученного из dir().
# загрузка пакетов
pacman::p_load(
tidyverse, # управление данными
stringr, # работа с последовательностями/текстом
lubridate, # работа с датами
rio, # импорт / экспорт
here, # относительный путь к файлу
fs) # взаимодействие директорий
# извлечение имени самого последнего по дате файла
latest_file <- dir(here("data", "example", "linelists")) %>% # имена файлов из подпапки "linelists"
str_extract("[0-9].*[0-9]") %>% # извлечение дат (чисел)
ymd() %>% # конвертация цифр в даты (предполагая формат год-месяц-день)
which.max() %>% # получение индекса максимальной даты (самый последний по времени файл)
dir(here("data", "example", "linelists"))[[.]] # возврат имени файла самого последнего построчного списка
latest_file # печать имени самого последнего файла[1] "case_linelist_2020-10-08.xlsx"Теперь вы можете использовать это имя файла для завершения относительного пути к файлу с помощью here():
here("data", "example", "linelists", latest_file) И теперь вы сможете импортировать самый последний по времени файл:
# import
import(here("data", "example", "linelists", latest_file)) # import Использование информации о файле
Если в имени ваших файлов не указана дата (или если вы не доверяете указанным датам), вы можете попробовать извлечь дату последнего изменения из метаданных файлов. Используйте функции из пакета fs для изучения информации из метаданных для каждого файла, которая включает время последнего изменения и путь к файлу.
Ниже мы указываем для функции dir_info() из пакета fs нужную нам папку. В данном случае нас интересует папка в проекте R, папка “data”, подпапка “example”, и подпапка в ней “linelists”. Результатом является датафрейм с одной строчкой на кадлый файл и со столбцами modification_time (время изменения), path (путь) и т.п. Вы можете увидеть визуальный пример на странице Взаимодействие директорий.
Мы можем отсортировать этот датафрейм файлов по столбцу modification_time, затем сохранить только верхнюю/последнюю строку (файл) с помощью функции head() из базового R. Затем мы можем извлечь путь к файлу этого самого последнего файла с помощью функции pull() из пакета dplyr из столбца path. Наконец мы можем вставить этот файл в import(). Импортированный файл сохраняется как latest_file.
latest_file <- dir_info(here("data", "example", "linelists")) %>% # собирает файл по всем файлам в директории
arrange(desc(modification_time)) %>% # сортировка по времени изменения
head(1) %>% # сохраняет тролько верхний (самый последний) файл
pull(path) %>% # извлекает только путь к файлу
import() # импорт файла7.10 API
Автоматизированный программный интерфейс (API) может быть использован для прямого запроса данных с веб-сайта. API - набор правил, которые позволяют одному программному приложению взаимодействовать с другим. Клиент (вы) направляет “запрос” и получает “ответ”, в котором есть какое-то содержимое. Пакеты R httr и jsonlite могут организовать этот процесс.
Каждый сайт с возможностью API будет иметь собственную документацию и специфику, с которыми нужно быть знакомым. Некоторые сайты являются доступными для всех. Другие, такие как платформы с логинами пользователей и их идентифицирующей информацией требуют аутентификации для получения доступа к их данным.
Конечно же, для импорта данных через API требуется интернет-соединение. Мы приведем краткие примеры использования API для импорта данных и дадим вам ссылку на дополнительные ресурсы.
Примечание: помните, что данные могут быть размещены* на веб-сайте без API, что может упростить их извлечение. Например, размещенный CSV файл может быть доступен просто через указание URL сайта в функции import(), как было описано в разделе Импорт из Github.*
Запрос HTTP
Обмен API наиболее часто производится через запрос HTTP. HTTP - гипертекстовый транспортный протокол, и он является базовым форматом запроса/ответа между клиентом и сервером. Точные входные и выходные данные могут варьироваться в зависимости от типа API, но процесс всегда одинаковый - “Запрос” (часто HTTP запрос) от пользователя, часто содержащий вопрос, после которого идет “Ответ”, содержащий информацию о статусе запроса и возможно запрошенное содержание.
Вот несколько компонентов HTTP запроса:
- URL конечной точки API
- “Метод” (или “Глагол”)
- Заголовки
- Основной текст
“Метод” запроса HTTP - действие, которое вы должны предпринять. Два наиболее частых метода HTTP - это GET и POST, но есть и другие, которые могут включать PUT, DELETE, PATCH, и так далее. При импорте данных в R вы скорее всего будете использовать GET.
После вашего запроса компьютер получит “ответ” в формате, похожем на тот, который вы отправили, включая URL, статус HTTP (вам нужен Status 200!), тип файла, размер, а также желаемое содержимое. Затем вам нужно будет проанализировать этот ответ и превратить его в датафрейм, с которым можно работать в среде R.
Пакеты
Пакет httr хорошо работает с HTTP запросами в R. Он не требует больших предварительных знаний веб-API, его могут использовать люди, не очень знакомые с терминологией программного обеспечения. Кроме того, если ответ HTTP является .json, вы можете использовать jsonlite для анализа ответа.
# загрузка пакетов
pacman::p_load(httr, jsonlite, tidyverse)Публично-доступные данные
Ниже представлен пример запроса HTTP, взятый из самоучителя the Trafford Data Lab. На этом сайте есть несколько других ресурсов для изучения, а также упражнения по API.
Сценарий: мы хотим импортировать список фаст-фуд ресторанов города Траффорд, Великобритания. Доступ к данным можно получить из API из Агентства по стандартам продуктов питания, которое предоставляет данные по рейтингу продовольственной гигиены по Великобритании.
Вот параметры нашего запроса:
- HTTP глагол: GET
- API URL конечной точки: http://api.ratings.food.gov.uk/Establishments
- Выбранные параметры: name, address, longitude, latitude, businessTypeId, ratingKey, localAuthorityId
- Headers: “x-api-version”, 2
- Формат(ы) данных: JSON, XML
- Документация: http://api.ratings.food.gov.uk/help
Код R будет выглядеть следующим образом:
# подготовка запроса
path <- "http://api.ratings.food.gov.uk/Establishments"
request <- GET(url = path,
query = list(
localAuthorityId = 188,
BusinessTypeId = 7844,
pageNumber = 1,
pageSize = 5000),
add_headers("x-api-version" = "2"))
# проверка ошибок сервера ("200" это хорошо!)
request$status_code
# подача запроса, анализ ответа и конвертация в датафрейм
response <- content(request, as = "text", encoding = "UTF-8") %>%
fromJSON(flatten = TRUE) %>%
pluck("establishments") %>%
as_tibble()Вы теперь можете вычистить и использовать датафрейм ответа response, который содержит по одной строке на каждый фаст-фуд ресторан.
Требуемая аутентификация
Некоторые API требуют аутентификации - чтобы вы указали, кто вы, чтобы получили доступ к ограниченным данным. Чтобы импортировать эти данные, вам может быть необходимо сначала использовать метод POST, чтобы предоставить имя пользователя, пароль или код. Это вам выдаст токен доступа, который может быть использован для последующих запросов методом GET для извлечения нужных данных.
Ниже представлен пример запроса данных из Go.Data, который является инструментом расследования вспышек. Go.Data использует API для всех взаимодействий между веб фронт-энд и приложениями смартфона, используемыми для сбора данных. Go.Data используется по всему миру. Поскольку данные о вспышках являются чувствительными, и вам должен быть открыт доступ только к данным по вашей вспышке, требуется аутентификация.
Ниже представлен пример кода R с использованием httr и jsonlite для связи с Go.Data API для импорта данных по отслеживанию контактов в вашей вспышке.
# установка идентификационных данных для авторизации
url <- "https://godatasampleURL.int/" # правильный адрес экземпляра Go.Data
username <- "username" # правильное имя пользователя Go.Data
password <- "password" # правильный пароль Go.Data
outbreak_id <- "xxxxxx-xxxx-xxxx-xxxx-xxxxxxx" # правильное ID вспышки в Go.Data
# получение токена на доступ
url_request <- paste0(url,"api/oauth/token?access_token=123") # определение базового запроса URL
# погдготовка запроса
response <- POST(
url = url_request,
body = list(
username = username, # используйте сохраненное выше имя пользователя/пароль для авторизации
password = password),
encode = "json")
# исполнение запроса и анализ ответа
content <-
content(response, as = "text") %>%
fromJSON(flatten = TRUE) %>% # сведение вложенного JSON
glimpse()
# сохранение токена доступа из ответа
access_token <- content$access_token # сохраните токен доступа, чтобы разрешить указанные ниже запросы API
# импорт контактов по вспышке
# использование токена доступа
response_contacts <- GET(
paste0(url,"api/outbreaks/",outbreak_id,"/contacts"), # запрос GET
add_headers(
Authorization = paste("Bearer", access_token, sep = " ")))
json_contacts <- content(response_contacts, as = "text") # конвертация в текст JSON
contacts <- as_tibble(fromJSON(json_contacts, flatten = TRUE)) # сведение JSON в таблицу tibbleВНИМАНИЕ: Если вы импортируете большие объемы данных из API, требующего аутентификации, может выйти время. Чтобы этого избежать, заново извлекайте access_token перед каждым запросом API GET и попробуйте использовать фильтры или ограничения в запросе.
СОВЕТ: Функция fromJSON() в пакете jsonlite не делает полное разложение с первого раза применения, поэтому, скорее всего, у вас останутся части в виде списка в получившейся таблице tibble. Вам нужно дополнительно разложить некоторые переменные, в зависимости от того, как был построен вложенный .json is. Для получения дополнительной информации, см. документацию по пакету jsonlite, например, функция flatten().
Для получения дополнительной информации, см. документацию по LoopBack Explorer, страницу Отслеживание контактов или советы по API в Github репозитории Go.Data
Вы можете больше прочитать о пакете httr здесь
Информация для данного раздела была также взята из этого самоучителя и этого самоучителя.
7.11 Экспорт
С помощью пакета rio
В rio вы можете использовать функцию export() очень похожим образом, как и import(). Сначала задайте имя объекта R, который вы хотите сохранить (например, linelist) и затем в кавычках укажите путь к файлу, по которому вы хотите сохранить файл, включая желаемое имя и расширение файла. Например:
Это сохраняет датафрейм linelist как рабочую книгу Excel в рабочую директорию/корневую папку проекта R:
export(linelist, "my_linelist.xlsx") # сохранит в рабочую директориюВы можете сохранить тот же датафрейм как csv файл, изменив расширение. Например, мы также можем указать путь к файлу, построенный с помощью here():
export(linelist, here("data", "clean", "my_linelist.csv"))В буфер обмена
Чтобы экспортировать датафрейм в буфер обмена вашего компьютера (чтобы потом вставить в другую программу, такую как Excel, Google Spreadsheets и т.п.), вы можете использовать write_clip() из пакета clipr.
# экспорт датафрейма linelist в буфер обмена вашего компьютера
clipr::write_clip(linelist)7.12 RDS файлы
Кроме .csv, .xlsx, и т.п., вы можете также экспортировать/сохранять R датафреймы как .rds файлы. Это формат файла, специфичный для R, и он также очень полезен, если вы знаете, что вам снова нужно будет работать с экспортированными данными в R.
Классы столбцов сохраняются, так что вам не придется снова делать вычистку при импорте (с файлами Excel или даже CSV это может быть сложно!). Также этот файл меньшего размера, что полезно для экспорта и импорта больших наборов данных.
Например, если вы работаете в команде эпидемиологов и вам нужно отправить файлы команде по GIS для составления карты, а они также используют R, просто отправьте им файл .rds! Тогда сохранятся все классы столбцов, и вы уменьшите им работу.
export(linelist, here("data", "clean", "my_linelist.rds"))7.13 Файлы Rdata и списки
Файлы .Rdata могут содержать несколько объектов R - например, несколько датафреймов, результаты моделирования, списки и т.п. Это может быть очень полезным для консолидации или обмена большим количеством данных для определенного проекта.
В примере ниже несколько объектов R хранятся в экспортированном файле “my_objects.Rdata”:
rio::export(my_list, my_dataframe, my_vector, "my_objects.Rdata")Примечание: если вы пытаетесь импортировать список, используйте import_list() из пакета rio для импорта с полной оригинальной структурой и содержимым.
rio::import_list("my_list.Rdata")7.14 Сохранение графиков
Инструкции по сохранению графиков, например, созданных с помощью ggplot(), детально приведены на странице основы ggplot.
Если говорить кратко, выполните ggsave("my_plot_filepath_and_name.png") после печати вашего графика. Вы можете либо указать объект сохраненного графика в аргументе plot =, либо указать только путь к файлу назначения (с расширением файла), чтобы сохранить последний выведенный на экран график. Вы можете контролировать width = (ширину), height = (высоту), units = (единицы), и dpi = (точки на дюйм).
Сохранение сетевого графика, например, дерева передачи, рассматривается на странице Цепочки распространения.
7.15 Ресурсы
Руководство по импорту/экспорту данных в R
R для аналитики данных, глава по импорту данных
Документация ggsave()
Ниже представлена таблица, взятая из онлайн виньетки по rio. Для каждого типа данных она показывает: ожидаемое расширение файла, пакет, который rio использует для импорта или экспорта данных, а также включен ли этот функционал в версию rio, установленную по умолчанию.
| Формат | Обычное расширение | Пакет для импорта | Пакет для экспорта | Установлен по умолчанию |
|---|---|---|---|---|
| Данные, разделенные запятыми | .csv | data.table fread()
|
data.table | Да |
| Данные, разделенные вертикальной чертой | .psv | data.table fread()
|
data.table | Да |
| Данные, разделенные знаками табуляции | .tsv | data.table fread()
|
data.table | Да |
| SAS | .sas7bdat | haven | haven | Да |
| SPSS | .sav | haven | haven | Да |
| Stata | .dta | haven | haven | Да |
| SAS | XPORT | .xpt | haven | haven |
| SPSS Portable | .por | haven | Да | |
| Excel | .xls | readxl | Да | |
| Excel | .xlsx | readxl | openxlsx | Да |
| Синтакс R | .R | базовый | базовый | Да |
| Сохраненные объекты R | .RData, .rda | базовый | базовый | Да |
| Серийные объекты R | .rds | базовый | базовый | Да |
| Epiinfo | .rec | foreign | Да | |
| Minitab | .mtp | foreign | Да | |
| Systat | .syd | foreign | Да | |
| “XBASE” | файлы базы данных | .dbf | foreign | foreign |
| Формат файлов связи атрибутов Weka | .arff | foreign | foreign | Да |
| Формат обмена данными | .dif | utils | Да | |
| Данные Fortran | no recognized extension | utils | Да | |
| Формат данных с фиксированной шириной | .fwf | utils | utils | Да |
| gzip данные, разделенные запятыми | .csv.gz | utils | utils | Да |
| CSVY (CSV + YAML metadata header) | .csvy | csvy | csvy | Нет |
| EViews | .wf1 | hexView | Нет | |
| Формат обмена Feather R/Python | .feather | feather | feather | Нет |
| Fast Storage | .fst | fst | fst | Нет |
| JSON | .json | jsonlite | jsonlite | Нет |
| Matlab | .mat | rmatio | rmatio | Нет |
| OpenDocument Spreadsheet | .ods | readODS | readODS | Нет |
| Таблицы HTML | .html | xml2 | xml2 | Нет |
| Shallow XML documents | .xml | xml2 | xml2 | Нет |
| YAML | .yml | yaml | yaml | Нет |
| Буфер обмена по умолчанию tsv | clipr | clipr | Нет |