22 Скользящие средние значения
На этой странице мы рассмотрим два метода расчета и визуализации скользящих средних значений:
- Расчет с помощью пакета slider
- Расчет внутри команды
ggplot()с помощью пакета tidyquant
22.1 Подготовка
Загрузка пакетов
Данный фрагмент кода показывает загрузку пакетов, необходимых для анализа. В данном руководстве мы фокусируемся на использовании p_load() из пакета pacman, которая устанавливает пакет, если необходимо, и загружает его для использования. Вы можете также загрузить установленные пакеты с помощью library() из базового R. См. страницу Основы R для получения дополнительной информации о пакетах R.
pacman::p_load(
tidyverse, # для управления данными и визуализации
slider, # для расчета скользящего среднего
tidyquant # для расчета скользящего среднего внутри ggplot
)Импорт данных
Мы импортируем набор данных о случаях из имитированной эпидемии Эболы. Если вы хотите выполнять действия параллельно, кликните, чтобы скачать “чистый” построчный список (как файл .rds). Импортируйте данные с помощью функции import() из пакета rio (она работает с разными типами файлов, такими как .xlsx, .csv, .rds - см. дополнительную информацию на странице Импорт и экспорт).
# импортируем построчный список
linelist <- import("linelist_cleaned.xlsx")Первые 50 строк построчного списка отображены ниже.
22.2 Расчет с помощью slider
Используйте этот подход для расчета скользящего среднего в датафрейме до создания графика.
Пакет slider предоставляет несколько функций “скользящего окна” для расчета скользящих средних значений, нарастающей суммы, скользящих регрессий и т.п. Он рассматривает датафрейм как вектор строк, позволяя итерации по строкам в датафрейме.
Вот некоторые часто используемые функции:
-
slide_dbl()- проводит итерации по числовому столбцу (отсюда “_dbl”), выполняя операцию с использованием скользящего окна-
slide_sum()- краткая функция скользящей суммы дляslide_dbl()
-
slide_mean()- краткая фукнция скользящего среднего значения дляslide_dbl()
-
-
slide_index_dbl()- применяет скользящее окно к числовому столбцу, используя отдельный столбец для индексирования прогресса окна (полезно, если скользит по дате с некоторыми отсутствующими датами)-
slide_index_sum()- краткая функция скользящей суммы с индексированием
-
slide_index_mean()- краткая функция скользящего среднего с индексированием
-
В пакете slider есть множество других функций, которые упоминяются в разделе Ресурсы на этой странице. Мы кратко расскажем о наиболее часто использующихся из них.
Ключевые аргументы
-
.x, первым аргументом по умолчанию является вектор, по которому будет идти итерация и которому будет применяться функция
-
.i =для “индексных” версий функций slider - задайте столбец для “индексирования” скольжения (см. раздел ниже)
-
.f =, второй аргумент по умолчанию, либо:- Функция, написанная без скобок, например,
mean, или
- Формула, которая будет конвертирована в функцию. Например,
~ .x - mean(.x)выдаст результат текущего значения минус среднее значение окна.
- Функция, написанная без скобок, например,
- Дополнительную информацию см. в этом справочном материале
Размер окна
Уточните размер окна, используя либо .before, .after, либо оба аргумента:
-
.before =- задайте число
-
.after =- задайте число
-
.complete =- Установите какTRUE, если вы хотите, чтобы расчет делалася только на полных окнах
Например, чтобы получить 7-дневное окно, включая текущее значение и шесть предыдущих, используйте .before = 6. Чтобы получить “отцентрованное” окно, задайте то же число и в .before =, и в .after =.
По умолчанию .complete = будет FALSE (ЛОЖЬ), так что если не существует полное окно строк, функция использует имеющиеся строки для расчета. Установка на TRUE (ИСТИНА) ограничивает расчеты так, чтобы они проводились только с полными окнами.
Расширение окна
Чтобы выполнить операции с накоплением, установите аргумент .before = на Inf. Это позволит проводить операцию над текущим значеним и всеми предыдущими.
Скольжение по дате
Самый частый вариант применения скользящих расчетов в прикладной эпидемиологии - рассмотрение метрики во времени. Например, рассмотрение скользящего показателя заболеваемости на основе ежедневного количества случаев.
Если у вас есть чистые данные по временным рядам со значениями для каждой даты, возможно, вы сможете использовать slide_dbl(), как показано на странице Временные ряды и обнаружение вспышек.
Однако во многих ситуациях в прикладной эпидемиологии у вас могут быть отсутствующие даты в данных, когда не было задокументировано событий. В этих случаях лучше использовать “индексированные” версии функций slider.
Индексируемые данные
Ниже мы показываем пример использования slide_index_dbl() для построчного списка случаев. Представим, что наша задача - рассчитать скользящую 7-дневную заболеваемость - сумму случаев, используя скользящее 7-дневное окно. Если вам нужен пример скользящего среднего значения, см. раздел ниже сгруппированное скользящее.
Для начала создаем набор данных daily_counts, чтобы отразить ежедневное количество случаев из linelist, что рассчитывается с помощью count() из dplyr.
# создаем набор данных ежедневных случаев
daily_counts <- linelist %>%
count(date_hospitalisation, name = "new_cases")Вот датафрейм daily_counts - в нем nrow(daily_counts) строк, каждый день представлен одной строкой, но на самых ранних этапах эпидемии некоторые дни не отражаются (в эти дни не поступали случаи).
Очень важно понимать, что стандартная скользящая функция (например, slide_dbl() будет использовать окно из 7 строк, а не 7 дней. Поэтому если даты отсутствуют, некоторые окна могут растягиваться больше, чем на 7 календарных дней!
Можно создать “умное” скользящее окно с помощью slide_index_dbl(). “index” (индекс) означает, что функция использует отдельный столбец в качестве “индекса” для скользящего окна. Окно не просто основано на строках датафрейма.
Если индексным столбцом является дата, у вас появляется дополнительная возможность уточнить протяженность окна с помощью .before = и/или .after = в единицах из lubridate days() или months(). Если вы это сделаете, функция включит отсутствующие дни в окно, как если бы они имелись (как значения NA).
Давайте покажем сравнение. Ниже мы рассчитываем скользящую 7-дневную заболеваемость с обычными и индексированными окнами.
rolling <- daily_counts %>%
mutate( # создаем новые столбцы
# Используем slide_dbl()
###################
reg_7day = slide_dbl(
new_cases, # расчет для new_cases
.f = ~sum(.x, na.rm = T), # функция sum() с удалением отсутствующих значений
.before = 6), # окно - СТРОКА и 6 предыдущих СТРОК
# Используем slide_index_dbl()
#########################
indexed_7day = slide_index_dbl(
new_cases, # расчет для new_cases
.i = date_hospitalisation, # индексируем по date_onset
.f = ~sum(.x, na.rm = TRUE), # функция sum() с удалением отсутствующих значений
.before = days(6)) # окно - ДЕНЬ и 6 предыдущих ДНЕЙ
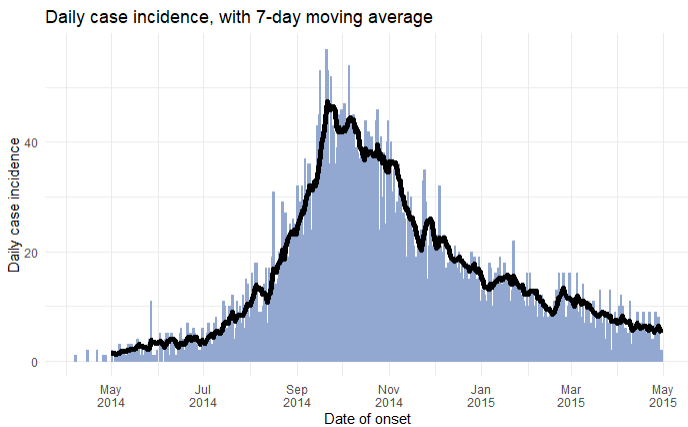
)Посмотрите, что в обычном столбце в первых 7 строках количество стабильно возрастает, хотя строки не находятся в диапазоне 7 дней друг от друга! Соседний “индексированный” столбец учитывает эти отсутствующие календарные дни, поэтому в ней 7-дневные суммы гораздо меньше, по крайней мере в этот период эпидемии, когда между случаями проходит больше времени.
Теперь вы можете отразить эти данные на графике, используя ggplot():
ggplot(data = rolling)+
geom_line(mapping = aes(x = date_hospitalisation, y = indexed_7day), size = 1)Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.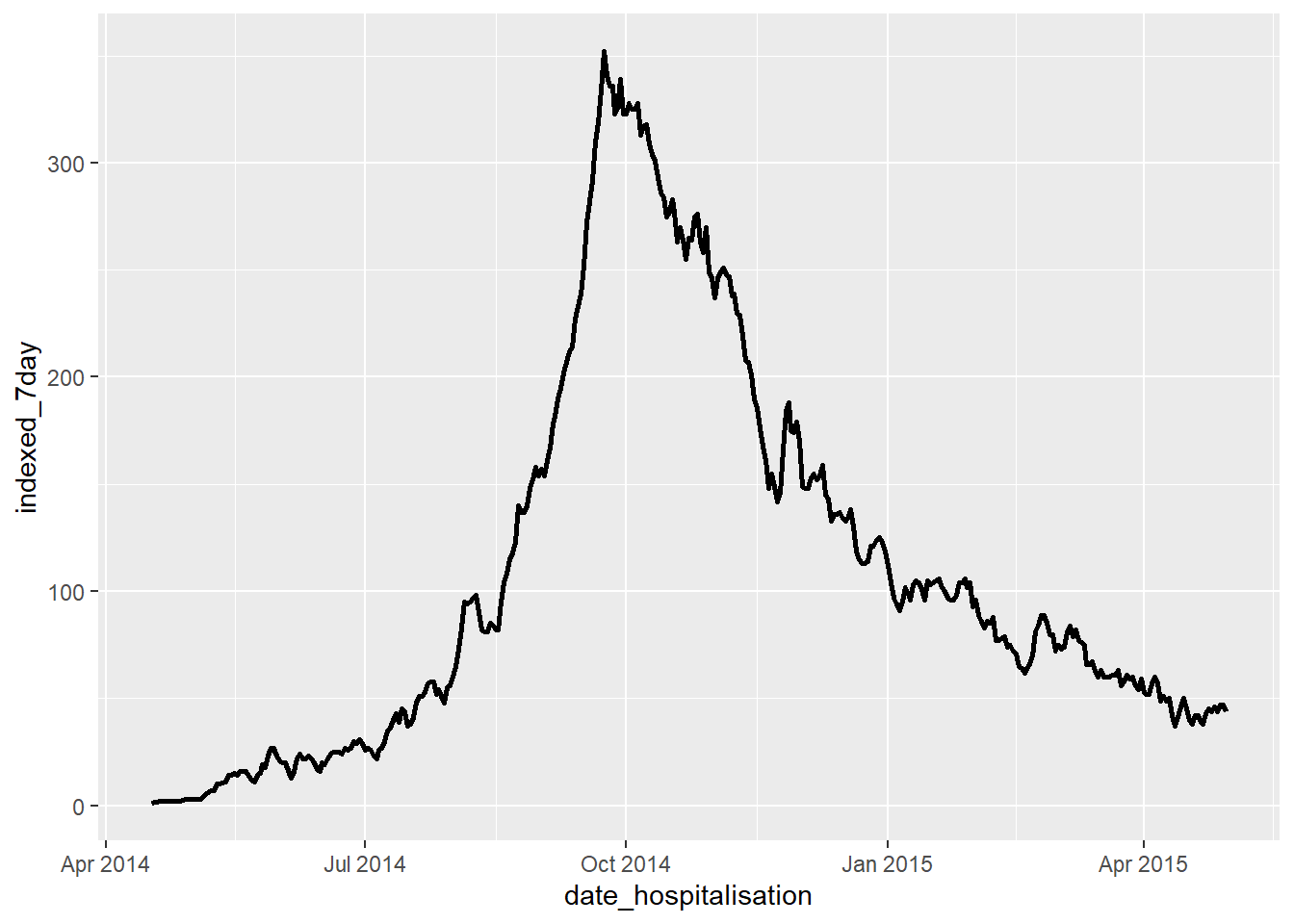
Скользящее по группе
Если вы группируете свои данные до использования функции slider, скользящие окна будут применены по группам. Внимательно упорядочите ваши строки в нужном порядке по группе.
Каждый раз, когда начинается новая группа, будет перезапускаться скользящее окно. Следовательно, необходимо помнить о том нюансе, что если ваши данные сгруппированы и вы установили .complete = TRUE, у вас будут пустые значения при каждом переходе между группами. По мере того как функция двигается вниз по строкам, каждый переход в столбце группирования будет перезапускать накопление минимального размера окна, чтобы начать расчет.
См. страницу руководствча [Группирование данных] для получения детальной информации о группировании данных.
Ниже мы считаем случаи построчного списка по дате и по больнице. Затем мы упорядочиваем строки по возрастанию, сначала упорядочив по больнице, а затем внутри этих групп - по дате. Далее мы устанавливаем group_by(). Затем мы можем создать наге новое скользящее среднее.
grouped_roll <- linelist %>%
count(hospital, date_hospitalisation, name = "new_cases") %>%
arrange(hospital, date_hospitalisation) %>% # arrange rows by hospital and then by date
group_by(hospital) %>% # группируем по больнице
mutate( # скользящее среднее
mean_7day_hosp = slide_index_dbl(
.x = new_cases, # количество случаев на больницу на день
.i = date_hospitalisation, # индексирование по дате госпитализации
.f = mean, # используем mean()
.before = days(6) # используем день и 6 предыдущих дней
)
)Вот новый набор данных:
Теперь мы можем построить график скользящих средних значений, отобразив данные по группе, задав ~ hospital в facet_wrap() в ggplot(). Для интереса построим две геометрии - geom_col(), показывающий количество случаев в день и geom_line(), показывающий 7-дневное скользящее среднее.
ggplot(data = grouped_roll)+
geom_col( # строим график количества случаев в день в виде серых столбцов
mapping = aes(
x = date_hospitalisation,
y = new_cases),
fill = "grey",
width = 1)+
geom_line( # строим график скользящего среднего в виде линии, цвет которой указан по больнице
mapping = aes(
x = date_hospitalisation,
y = mean_7day_hosp,
color = hospital),
size = 1)+
facet_wrap(~hospital, ncol = 2)+ # создаем мини-графики по больнице
theme_classic()+ # упрощаем фон
theme(legend.position = "none")+ # удаляем легенду
labs( # устанавливаем подписи
title = "7-day rolling average of daily case incidence",
x = "Date of admission",
y = "Case incidence")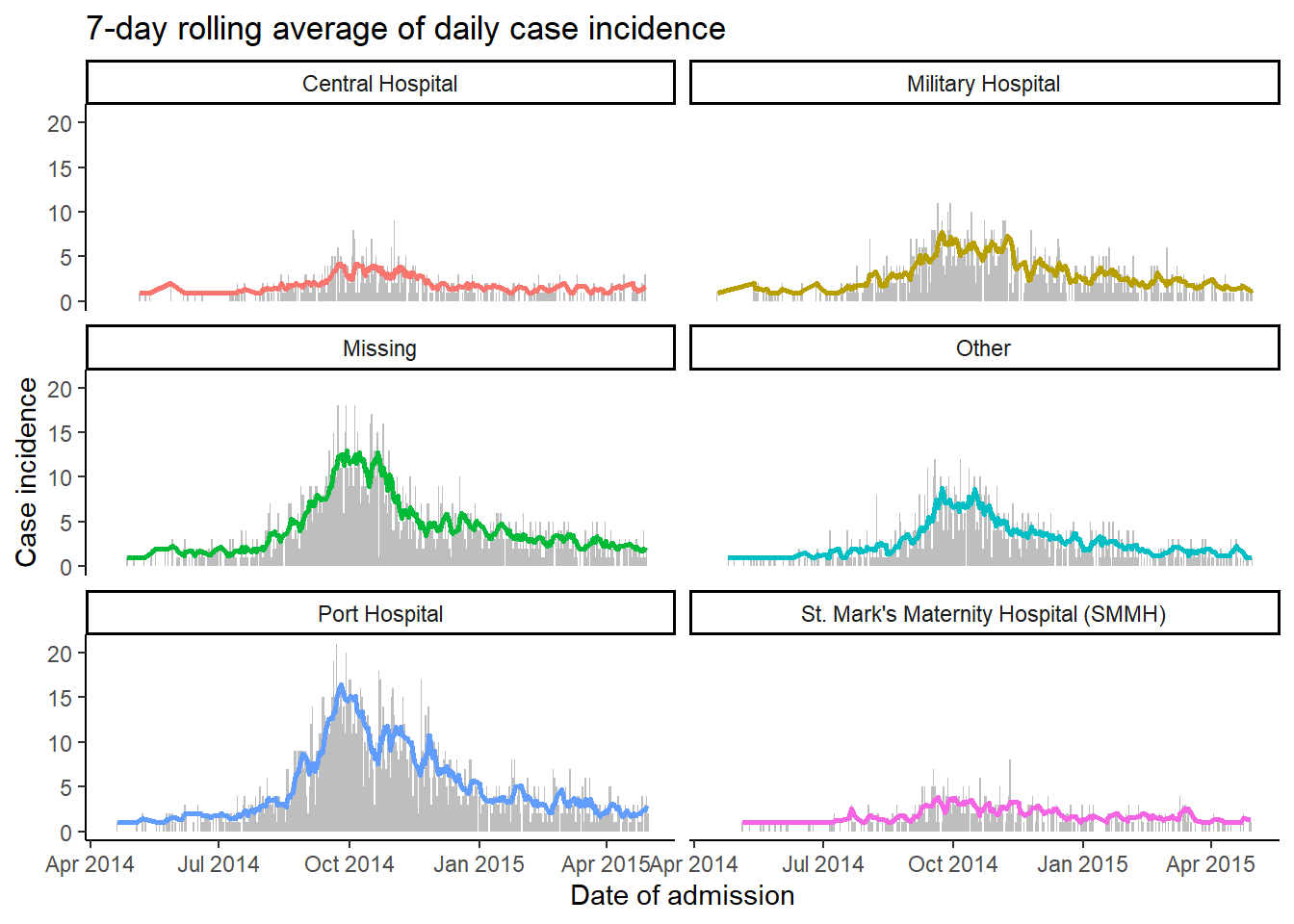
ВНИМАНИЕ: Если у вас появится ошибка “slide() was deprecated in tsibble 0.9.0 and is now defunct. Please use slider::slide() instead.”, это означает, что функция slide() из пакета tsibble маскирует функцию slide() из пакета slider. Это можно исправить, уточнив в команде пакет, например: slider::slide_dbl().
22.3 Расчет с помощью tidyquant внутри ggplot()
Пакет tidyquant предлагает еще один подход к расчету скользящих средних значений - на этот раз внутри команды ggplot().
Ниже данные linelist считаются по дате появления симптомов и это отображается в виде серой линии (alpha < 1). На нее накладывается линия, созданная с помощью geom_ma() из пакета tidyquant, с заданным окном на 7 дней (n = 7) с уточнением цвета и толщины.
По умолчанию geom_ma() использует простое скользящее среднее (ma_fun = "SMA"), но можно задать другие типы, такие как:
- “EMA” - экспоненциальное скользящее среднее (больше вес у более недавних наблюдений)
- “WMA” - взвешенное скользящее среднее (
wtsиспользуются, чтобы взвесить наблюдения в скользящем среднем)
- В документации по функции можно найти и другие виды
linelist %>%
count(date_onset) %>% # подсчет количества случаев в день
drop_na(date_onset) %>% # удаляем случаи с отсутствующей датой появления симптомов
ggplot(aes(x = date_onset, y = n))+ # начинаем ggplot
geom_line( # график сырых значений
size = 1,
alpha = 0.2 # полупрозрачная линия
)+
tidyquant::geom_ma( # график скользящего среднего
n = 7,
size = 1,
color = "blue")+
theme_minimal() # простой фонWarning: Using the `size` aesthetic in this geom was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` in the `default_aes` field and elsewhere instead.
См. эту виньетку для получения более подробной информации об опциях, доступных в tidyquant.
22.4 Ресурсы
См. полезную онлайн виньетку для пакета slider
См. slider страницу в github
slider виньетка
Если в вашем случае нужно “пропускать” выходные или праздники, вам может понравиться пакет almanac.